模型训练方法、语音降噪方法、装置及计算机存储介质与流程
本申请涉及人工智能,特别是涉及一种模型训练方法、语音降噪方法、装置及计算机存储介质。
背景技术:
1、日常行车条件情况复杂多样,风噪、路噪、街道嘈杂声、车内背景声、充电噪声等都在影响车载语音质量。噪声抑制模块作为车载系统中关键的部分,能在嘈杂场景中,为用户保障语音质量,使语音清晰、真实。
2、现有高性能ai降噪模型一般大而复杂,实时性差,当前的车载计算资源无法满足。若直接部署训练的小模型,性能无法保障;如果采用剪枝和量化的手段部署较大的噪声抑制模型,性能会大打折扣,这两种方案在实际当中,无法平衡性能和资源的矛盾。
技术实现思路
1、为解决上述技术问题,本申请提出了一种模型训练方法、语音降噪方法、装置及计算机存储介质。
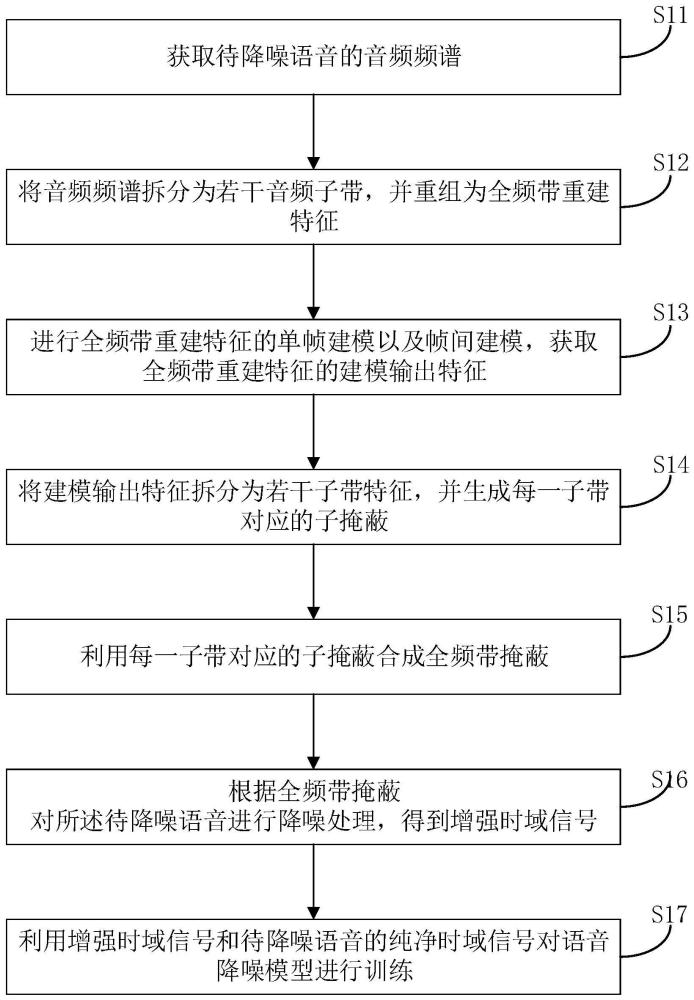
2、为解决上述技术问题,本申请提出了一种语音降噪模型的模型训练方法,所述模型训练方法包括:获取待降噪语音的音频频谱;将所述音频频谱拆分为若干音频子带,并重组为全频带重建特征;进行所述全频带重建特征的单帧建模以及帧间建模,获取所述全频带重建特征的建模输出特征;将所述建模输出特征拆分为若干子带特征,并生成每一子带特征对应的子掩蔽;利用所述每一子带特征对应的子掩蔽合成全频带掩蔽;根据全频带掩蔽对所述待降噪语音进行降噪处理,得到增强时域信号;利用所述增强时域信号和所述待降噪语音的纯净时域信号对所述语音降噪模型进行训练。
3、其中,所述将所述音频频谱拆分为若干音频子带,包括:获取若干频带带宽范围,以及每一频带带宽范围内的子带带宽和子带数量;将所述音频频谱按照频带拆分到各个频带带宽范围内;将所述各个频带带宽范围内的音频频谱按照子带带宽拆分为对应子带数量的音频子带。
4、其中,所述重组为全频带重建特征,包括:将每一音频子带输入特征重建层,获取实数子带特征;按照所述音频子带的顺序,将对应的实数子带特征依次拼接,得到所述全频带重建特征。
5、其中,所述进行所述全频带重建特征的单帧建模以及帧间建模,包括:将所述全频带重建特征输入块内循环神经网络模型,对所述全频带重建特征的单帧频谱模式进行建模,得到所述全频带重建特征的单帧建模;将所述单帧建模输入块间循环神经网络模型,对所述全频带重建特征的连续帧间依赖性进行建模,得到所述全频带重建特征的帧间建模。
6、其中,所述获取所述全频带重建特征的建模输出特征,包括:将所述全频带重建特征经过若干次双路径递归神经网络模块的处理,得到所述建模输出特征;其中,所述双路径递归神经网络模块包括依次连接的块内循环神经网络模型和块间循环神经网络模型。
7、其中,所述块内循环神经网络模型和/或所述块间循环神经网络模型包括循环神经网络模块、完全连接层,即时层归一化层以及残差连接。
8、其中,所述利用所述增强时域信号和所述待降噪语音的纯净时域信号对所述语音降噪模型进行训练,包括:基于所述增强时域信号和所述纯净时域信号,获取信噪比损失;分别提取所述增强时域信号和所述纯净时域信号的实部、虚部和幅度;利用所述增强时域信号和所述纯净时域信号的实部均方误差、虚部均方误差和幅度均方误差,获取频谱均方误差损失;基于所述信噪比损失和频谱均方误差损失,对所述语音降噪模型进行训练。
9、为解决上述技术问题,本申请提出了一种语音降噪方法,所述语音降噪方法包括:将待降噪语音输入预先训练的语音降噪模型,获取降噪后的语音信号;将所述语音信号通过车载音响输出;其中,所述语音降噪模型通过上述的模型训练方法训练所得。
10、为解决上述技术问题,本申请提出了一种语音降噪装置,所述语音降噪装置包括存储器以及与所述存储器耦接的处理器;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现如上述的模型训练方法,和/或上述的语音降噪方法。
11、为解决上述技术问题,本申请提出了一种计算机存储介质,所述计算机存储介质用于存储程序数据,所述程序数据在被计算机执行时,用以实现如上述的模型训练方法,和/或上述的语音降噪方法。
12、与现有技术相比,本申请的有益效果是:语音降噪装置获取待降噪语音的音频频谱;将所述音频频谱拆分为若干音频子带,并重组为全频带重建特征;进行所述全频带重建特征的单帧建模以及帧间建模,获取所述全频带重建特征的建模输出特征;将所述建模输出特征拆分为若干子带特征,并生成每一子带对应的子掩蔽;利用所述每一子带对应的子掩蔽合成全频带掩蔽;根据全频带掩蔽对所述待降噪语音进行降噪处理,得到增强时域信号;利用所述增强时域信号和所述待降噪语音的纯净时域信号对所述语音降噪模型进行训练。通过上述方式,使用基于频带拆分的轻量模型,可在有限的车载计算资源下部署,使得音频降噪模型实现高性能高保真语音降噪,在低信噪比和复杂噪声环境下提高所需语音的质量。
技术特征:
1.一种语音降噪模型的模型训练方法,其特征在于,所述模型训练方法包括:
2.根据权利要求1所述的模型训练方法,其特征在于,
3.根据权利要求2所述的模型训练方法,其特征在于,
4.根据权利要求1所述的模型训练方法,其特征在于,
5.根据权利要求4所述的模型训练方法,其特征在于,
6.根据权利要求5所述的模型训练方法,其特征在于,
7.根据权利要求1所述的模型训练方法,其特征在于,
8.一种语音降噪方法,其特征在于,所述语音降噪方法包括:
9.一种语音降噪装置,其特征在于,所述语音降噪装置包括存储器以及与所述存储器耦接的处理器;
10.一种计算机存储介质,其特征在于,所述计算机存储介质用于存储程序数据,所述程序数据在被计算机执行时,用以实现如权利要求1至7任一项所述的模型训练方法,和/或权利要求8所述的语音降噪方法。
技术总结
本申请提出一种模型训练方法、语音降噪方法、装置及计算机存储介质。所述模型训练方法包括:获取待降噪语音的音频频谱;将所述音频频谱拆分为若干音频子带,并重组为全频带重建特征;进行所述全频带重建特征的单帧建模以及帧间建模,获取所述全频带重建特征的建模输出特征;将所述建模输出特征拆分为若干子带特征,并生成每一子带特征的对应的子掩蔽;利用所述每一子带特征对应的的子掩蔽合成全频带掩蔽;根据全频带掩蔽对所述待降噪语音进行降噪处理,得到增强时域信号;利用所述增强时域信号和所述待降噪语音的纯净时域信号对所述语音降噪模型进行训练。通过上述方式,提高语音降噪模型实现音频的强降噪的效果。
技术研发人员:徐峰
受保护的技术使用者:浙江零跑科技股份有限公司
技术研发日:
技术公布日:2024/4/24
- 还没有人留言评论。精彩留言会获得点赞!