一种基于自监督学习的婴儿哭声分类方法
本发明涉及语音识别领域,尤其涉及一种基于自监督学习的婴儿哭声分类方法。
背景技术:
1、婴儿哭声是婴儿沟通和表达需求的主要方式,同时也是父母和护理者了解婴儿健康状况的关键指标之一。近年来,深度学习技术的飞速发展为解决复杂的音频信号处理问题提供了新的可能性。目前的语类分类算法,大多数为有监督学习,需要大量有标签数据,无法有效运用无标签数据。
技术实现思路
1、本发明所要解决的技术问题是针对背景技术中所涉及到的缺陷,提供一种基于自监督学习的婴儿哭声分类方法。
2、本发明为解决上述技术问题采用以下技术方案:
3、一种基于自监督学习的婴儿哭声分类方法,包括以下步骤:
4、步骤1),获取婴儿哭声的无标签音频数据和有标签音频数据;
5、步骤2),建立上游自监督网络模型,将婴儿哭声的无标签音频数据输入上游自监督网络模型进行训练;
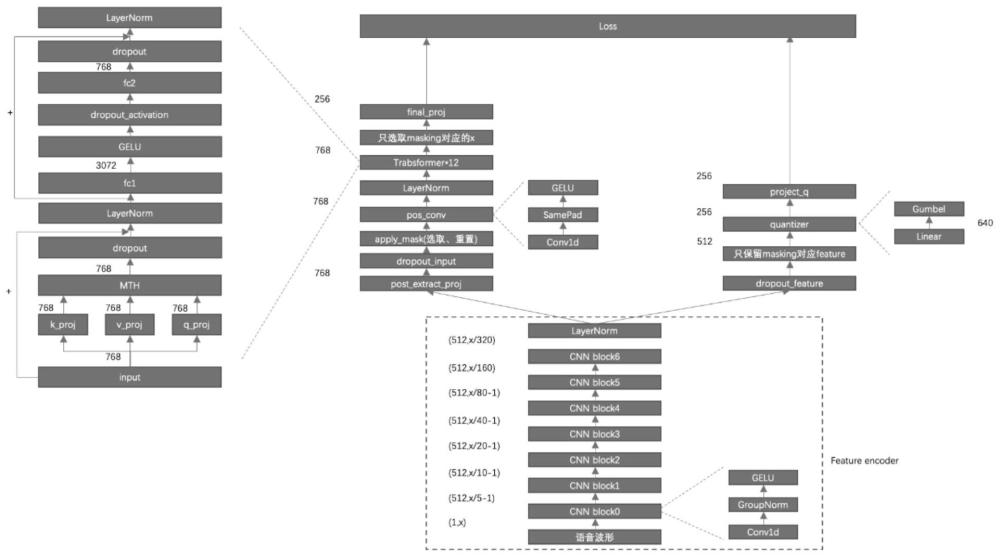
6、所述上游自监督网络模型包括feature encoder、context网络、mask部分、量化模块、输出层;
7、所述feature encoder为7层cnn网络,步长为(5,2,2,2,2,2,2),卷积核宽度为(10,3,3,3,3,2,2),用于根据接收的无标签音频数据提取高维特征,并将生成的高维特征分别传递给context网络、量化模块;
8、所述context网络包含conv部分和transformer部分,其中,所述conv部分用于改变接收到的的高维特征的数据维度,并将生成的调整好的高维特征传递给transformer部分;所述transformer部分接收conv部分调整好的高维特征用于学习全局信息,生成对应特征,并将对应特征传递给mask部分;
9、所述mask部分用于接收transformer部分生成的对应特征,防止transformer部分直接获取未来信息,生成被选取特征传递给输出层;
10、所述量化模块包含全连接层和gumbel_softmax激活函数,用于接收featureencoder生成的高维特征,将无限的特征表达空间坍缩成有限的离散空间,生成离散信息后后将离散信息传递给输出层;
11、所述输出层用接收量化模块和context网络传递的特征,进行比较学习,更新模型参数最后生成所需音频特征,其激活函数为l=lm+ald+blf,式中,α、b分别为预设的ld、lf的系数,lm、ld、lf分别为contrastive loss、diversity loss、针对feature encoder的l2penalty contrastive loss;
12、式中,sim(ct,qt)=cttqt/||ct||||qt||,ct为transformer部分输出,qt为量化部分输出,k为样本数量;
13、式中,g是码本数量,v是聚类中心数量,是特征对应(g,v)子空间的概率值;
14、lf通过平方根求均值得到;
15、步骤3),建立下游分类模型,所述下游分类模型采用卷积神经网络;
16、步骤4),将训练好的上游自监督网络模型引入下游分类模型,形成自监督学习的分类模型;
17、步骤5),将婴儿哭声的有标签音频数据输入自监督学习的分类模型进行训练;
18、步骤6),将待进行分类的婴儿哭声音频数据输入至训练好的自监督学习的分类模型进行哭声识别。
19、作为本发明一种基于自监督学习的婴儿哭声分类方法进一步的优化方案,所述步骤1)中获取婴儿哭声的无标签音频数据和有标签音频数据后对分别重采样至16khz。
20、作为本发明一种基于自监督学习的婴儿哭声分类方法进一步的优化方案,α取0.1,b取10。
21、作为本发明一种基于自监督学习的婴儿哭声分类方法进一步的优化方案,transformer模块中对数据进行随机丢弃的丢弃率为20%。
22、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
23、1.本发明能运用无标签的婴儿哭声数据进行婴儿哭声分类;
24、2.本发明应用了丢弃法,将丢弃数据从网络中删除,让它们不向后面的层传递信号。在学习过程中,丢弃哪些神经元是随机决定,因此模型不会过度依赖某些神经元,能一定程度上抑制过拟合,从而使得神经网络更稳定。
技术特征:
1.一种基于自监督学习的婴儿哭声分类方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于自监督学习的婴儿哭声分类方法,其特征在于,所述步骤1)中获取婴儿哭声的无标签音频数据和有标签音频数据后对分别重采样至16khz。
3.根据权利要求1所述的基于自监督学习的婴儿哭声分类方法,其特征在于,α取0.1,b取10。
4.根据权利要求1所述的基于自监督学习的婴儿哭声分类方法,其特征在于,transformer模块中对数据进行随机丢弃的丢弃率为20%。
技术总结
本发明公开了一种基于自监督学习的婴儿哭声分类方法,首先获取婴儿哭声的无标签音频数据和有标签音频数据,其次,建立上游自监督网络模型,将婴儿哭声的无标签音频数据输入上游自监督网络模型进行训练;接着建立下游分类模型,将训练好的上游自监督网络模型引入下游分类模型,形成自监督学习的分类模型;然后将婴儿哭声的有标签音频数据输入自监督学习的分类模型进行训练;最后将待进行分类的婴儿哭声音频数据输入至训练好的自监督学习的分类模型进行哭声识别。本发明能够利用无标签的婴儿哭声数据,优化婴儿哭声分类算法,提高婴儿哭声分类算法的性能。
技术研发人员:王斌,孙萌,任世伟,施冬奇
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!