一种基于语音离散化和声码器的目标说话人抽取系统
本发明涉及语音识别,尤其涉及一种基于语音离散化和声码器的目标说话人抽取系统。
背景技术:
1、目标说话人抽取任务的目标是借助目标说话人的注册语音或者声纹信息,从混合了多个声源的语音信号中抽取出目标说话人的声源信号。google在2018年提出了voicefilter模型,该模型使用一个额外的声纹模型提取出目标说话人的声纹特征向量,然后将这个声纹特征融合进一个类似于语音分离模型结构的语音抽取模型,从而得到目标说话人的时频谱。而等人提出的speakerbeam模型,抛弃了额外的声纹模型去提取目标说话人的声纹信息,转而在语音抽取模型中添加一个额外的编码器去学习如何提取目标说话人信息,从而能够做到端到端地训练语音抽取模型,实验也证明了端到端语音抽取模型相较于使用额外声纹模型的语音抽取模型有着更高的性能。
2、目前在目标说话人抽取领域,现有技术几乎都使用判别式神经网络的方法处理语音。判别式神经网络经过训练直接将混合语音映射到干净的目标说话人语音,损失函数一般是模型输出的语音信号与干净语音信号之间的一种信号级度量。这种方式可能导致语音抽取模型无法补偿因过度抑制使得输出信号中出现的缺失或受到严重破坏的频率成分。
3、因此,本领域的技术人员致力于开发一种基于语音离散化和声码器的目标说话人抽取系统,使用声码器技术将目标说话人的语音从混合语音信号中重新生成出来,对人耳更加友好,同时不存在残留干扰。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是判别式神经网络模型无法补偿因过度抑制使得输出信号中出现的缺失或受到严重破坏的频率成分。
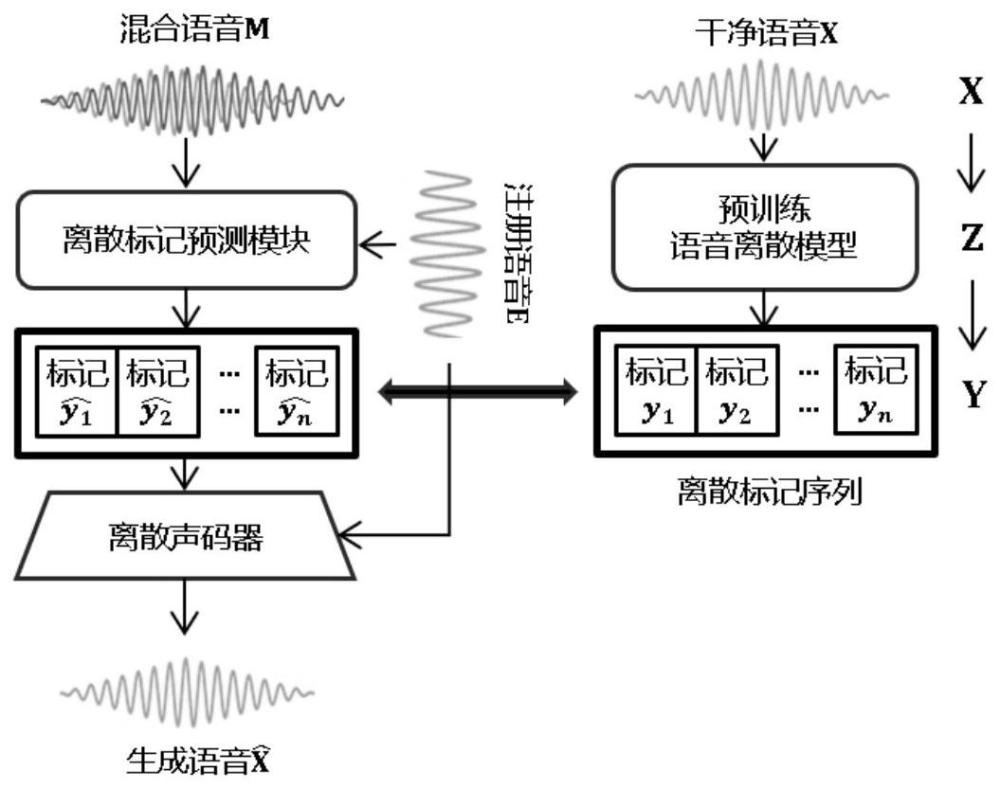
2、为实现上述目的,本发明提供了一种基于语音离散化和声码器的目标说话人抽取系统,包括预训练语音离散模块、离散标记预测模块和语音生成模块,其中,所述预训练语音离散模块用于将语音数据离散化为离散标记序列,所述离散标记预测模块根据所述离散标记序列输出预测离散标记序列,所述语音生成模块根据所述预测离散标记序列输出目标说话人的干净语音。
3、进一步地,所述预训练语音离散模块包括预训练语音离散模型,输入到所述预训练语音离散模型的语音数据为干净语音。
4、进一步地,所述预训练语音离散模型将每帧语音都转化为一个离散标记。
5、进一步地,所述离散标记序列和混合语音、目标说话人注册语音结合输入到所述离散标记预测模块。
6、进一步地,所述离散标记预测模块将目标说话人抽取视作一个分类任务。
7、进一步地,所述离散标记预测模块逐帧预测目标说话人对应的离散标记。
8、进一步地,所述预测离散标记序列的每帧为离散标记的后验概率。
9、进一步地,根据所述预测离散标记序列和所述离散标记序列计算交叉熵损失函数。
10、进一步地,所述语音生成模块包括离散声码器,所述离散声码器生成目标说话人的干净语音。
11、进一步地,所述预测离散标记序列和目标说话人注册语音结合输入到所述离散声码器。
12、与现有技术相比,本发明至少具有如下有益技术效果:
13、1、本发明使用声码器技术将目标说话人的语音从混合语音信号中重新生成出来,相较于传统的基于判别式神经网络的目标说话人抽取技术,本发明抽取出的语音在听感上更好,对人耳更加友好,同时不存在残留干扰;
14、2、本发明使用离散标记序列的声码器,相较于使用梅尔频谱作为输入的声码器,生成的语音会有更好的质量。
15、以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
技术特征:
1.一种基于语音离散化和声码器的目标说话人抽取系统,其特征在于,包括预训练语音离散模块、离散标记预测模块和语音生成模块,其中,所述预训练语音离散模块用于将语音数据离散化为离散标记序列,所述离散标记预测模块根据所述离散标记序列输出预测离散标记序列,所述语音生成模块根据所述预测离散标记序列输出目标说话人的干净语音。
2.如权利要求1所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述预训练语音离散模块包括预训练语音离散模型,输入到所述预训练语音离散模型的语音数据为干净语音。
3.如权利要求2所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述预训练语音离散模型将每帧语音都转化为一个离散标记。
4.如权利要求1所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述离散标记序列和混合语音、目标说话人注册语音结合输入到所述离散标记预测模块。
5.如权利要求4所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述离散标记预测模块将目标说话人抽取视作一个分类任务。
6.如权利要求5所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述离散标记预测模块逐帧预测目标说话人对应的离散标记。
7.如权利要求6所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述预测离散标记序列的每帧为离散标记的后验概率。
8.如权利要求1所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,根据所述预测离散标记序列和所述离散标记序列计算交叉熵损失函数。
9.如权利要求1所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述语音生成模块包括离散声码器,所述离散声码器生成目标说话人的干净语音。
10.如权利要求9所述的基于语音离散化和声码器的目标说话人抽取系统,其特征在于,所述预测离散标记序列和目标说话人注册语音结合输入到所述离散声码器。
技术总结
本发明公开了一种基于语音离散化和声码器的目标说话人抽取系统,涉及语音识别技术领域,包括预训练语音离散模块、离散标记预测模块和语音生成模块,其中,所述预训练语音离散模块用于将语音数据离散化为离散标记序列,所述离散标记预测模块根据所述离散标记序列输出预测离散标记序列,所述语音生成模块根据所述预测离散标记序列输出目标说话人的干净语音。本发明使用离散标记序列的声码器生成的语音,在听感上更好,对人耳更加友好,同时不存在残留干扰。
技术研发人员:钱彦旻,余林峰,张王优
受保护的技术使用者:上海交通大学
技术研发日:
技术公布日:2024/4/22
- 还没有人留言评论。精彩留言会获得点赞!