一种线控转向系统传动比优化控制方法及装置与流程
1.本发明涉及一种线控转向系统传动比优化控制方法及装置,属于车辆控制技术领域。
背景技术:
2.线控转向系统逐步开始进行实际装车应用,在线控转向系统中对操控性能最有影响的就是转向传动比的调整。
3.线控转向系统由于取消了方向盘和转向轮之间的机械控制连接,所以整个转向传动比可以由软件自由调节,但是转向传动比对于车辆的稳定性、操纵性有非常直接的影响,目前比较常见的是采用预设不同传动比由手工选择或者一定速度的自动选择,存在个性化不足且很难发挥出传动比可以无级调节的优势。
技术实现要素:
4.本发明的目的在于克服现有技术中的不足,提供一种线控转向系统传动比优化控制方法及装置,来自动选择转向传动比,使得车辆操作性能和稳定性能最佳。
5.为达到上述目的,本发明是采用下述技术方案实现的:
6.第一方面,本发明提供了一种线控转向系统传动比优化控制方法,包括:
7.获取汽车在路面行驶时的车辆参数;
8.对所述车辆参数进行预处理,获取预处理后的车辆参数;
9.将所述预处理后的车辆参数输入预先训练过的深度强化学习算法中,得到实时的线控转向传动比,基于传动比的计算值对线控转向系统的值进行实时的调整。
10.进一步的,所述车辆参数包括车速、方向盘转角、方向盘角速度、车身俯仰角、车身横摆角速度、车身侧倾角、前轴离地高度、后轴离地高度中的任意一种或多种。
11.进一步的,所述对所述车辆参数进行预处理包括:
12.将各个车辆参数进行滤波处理,消除噪点;
13.将各个车辆参数互相校对,确定参数的可用性,针对各个参数,设置对应的范围限值,超过则报警并将功能降级到初始设置的传动比值。
14.进一步的,所述深度强化学习算法的训练包括:
15.获取汽车在路面行驶时的车辆参数;
16.对所述车辆参数进行预处理,获取预处理后的车辆参数;
17.将所述预处理后的车辆参数作为深度强化学习算法的输入,得到最优传动比;
18.将深度强化学习算法得到的最优传动比作为线控转向系统的输入信号,在汽车继续行驶的过程中,线控转向系统根据算法计算出的值进行传动比的输入,并得到车辆参数的反馈值;
19.将反馈值预处理后再次作为深度强化学习算法的输入;进行多次循环过程,采集每次循环过程中的车辆参数的数据,并使用该数据对深度强化学习算法进行训练;
20.对以上步骤进行多次迭代训练,从而得到训练好的深度强化学习算法;其中,所述深度强化学习算法的输出为线控转向系统的传动比。
21.进一步的,所述深度强化学习算法的实现步骤包括:
22.算法步骤1:利用式(1)定义深度强化学习方法的车辆状态参数v:
23.v={w,α,β,wd,αd,βd}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
24.其中,wd为理想横摆角速度;w为测量横摆角速度;αd为理想车身侧倾角;α为测量车身侧倾角;βd为理想车身俯仰角;β为测量车身俯仰角;
25.算法步骤2:利用式(2)定义深度强化学习方法的动作参数a:
26.a={γ}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
27.式中:γ为线控转向系统角传动比,无单位;
28.算法步骤3:利用式(3)建立深度强化学习方法的奖励函数r:
29.r=rβ+rw+rα+rt
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
30.其中:rβ为车身俯仰角奖励函数、rw为车身横摆角速度奖励函数、rα为车身侧倾角奖励函数、rt为横向加速度响应时间;
31.算法步骤4:构建深度强化学习方法的计算模型;
32.算法步骤5:利用初始数据生成n个车辆数据样本;
33.算法步骤6:用步骤5得到的n个车辆数据样本对深度强化学习方法的模型进行训练,从而得到最优化神经网络模型;
34.算法步骤7:在车辆运行中,实时测量车辆当前状态参数vt,将状态参数输入到以上得到的最优神经网络模型中,直接输出目前状态下最优化的线控转向提供传动比。
35.进一步的,所述奖励函数设置为3个优先级,优先级越高,则该原则越重要,设计原则为:
36.1级:保证横摆角速度控制和横向加速度响应时间在设定范围内;
37.2级:保证车身的侧倾控制高于车身的俯仰控制;
38.3级:保证车身的俯仰在设定范围内;
39.其中,rα车身侧倾角奖励函数如式(4)所示,对应于2级设计原则,公式如下:
[0040][0041]
其中,roll为车身俯仰角;
△
roll=|roll
–
roll_normal|,表示车身俯仰角变化量;所述roll_normal表示在平整路面上汽车的车身侧倾角;max_pitch为
△ꢀ
pitch的最大值,roll_th为
△
pitch的阈值,max_roll≥roll_th≥0;
[0042]
rβ车身俯仰角奖励函数如式(5)所示,对应于3级设计原则,公式如下:
[0043][0044]
其中,pitch为车身俯仰角;δph=|ph
–
ph_normal|,表示车身俯仰角变化量;所述ph_normal表示在平整路面上汽车的车身俯仰角;max_ph为
△
pitch 的最大值,ph_th为δph的阈值,max_ph≥ph_th≥0;
[0045]
rw车身横摆角速度奖励函数如式(6)所示,对应于1级设计原则,设计二次函数作
为1级奖励函数,公式如下:
[0046][0047]
其中,yaw为车身横摆角速度;δyaw=|yaw
–
yaw_normal|,表示车身横摆角速度变化量;所述yaw_normal表示在平整路面上汽车的车身俯仰角; max_yaw为δyaw的最大值,yaw_th为δyaw的阈值,max_yaw≥yaw_th≥0;
[0048]
rt车身横向加速度响应时间奖励函数如式(7)所示,对应于1级设计原则,设计二次函数作为1级奖励函数,公式如下:
[0049][0050]
其中,yt为车身横向加速度响应时间;δyt=|yt
–
yt_normal|,表示车身横向加速度响应时间变化量;所述yt_normal表示在平整路面上汽车的车身横向加速度响应时间;max_yt为δyt的最大值,yt_th为δyaw的阈值,max_yt≥yt_th≥0。
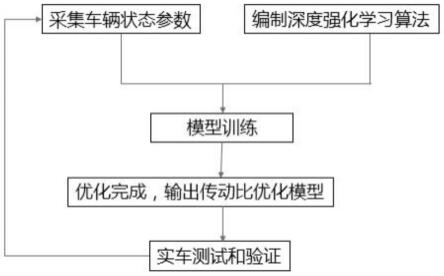
[0051]
进一步的,所述构建深度强化学习方法的计算模型包括:
[0052]
构建初始动作神经网络模型,模型为三层神经网络模型包括:第一层输入层,包含一个神经元,第二层为隐藏层,包含x1个神经元,第三层为包含2个神经元的输出层;初始化动作参数为ina_first;
[0053]
构建评价神经网络模型,模型为三层神经网络模型,包括:第一层输入层,包含两个神经元,隐藏层包含x2个神经元,输出层包含1个神经元,初始化评价参数为inev_first;
[0054]
构建目标神经网络模型,其结构与初始神经网络模型结构相同,且令目标动作参数ina_target=ina_first,构建目标评价神经网络模型,其结构与评价神经网络模型结构相同,且令目标评价参数inev_target=inev_first。
[0055]
进一步的,所述利用初始数据生成n个车辆数据样本,包括:
[0056]
利用经验值或者实车测量值赋值初始车辆状态参数v_inital,并以此车辆状态参数v_inital作为初始神经网络的输入,由该模型输出f(v_inital|ina_first);
[0057]
利用式(8)得到第n个车辆动作参数an:
[0058]
an=f(v_inital|ina_first)(8)
[0059]
根据式(3)获取第n个车辆奖励值rn,并得到更新后的第n个车辆状态参数 vn_new;从而得到获得第n条样本,记为(vn,an,rn,vn_new)
[0060]
重复以上步骤进而得到所需要的n个数据样本。
[0061]
进一步的,所述用步骤5得到的n个车辆数据样本对深度强化学习方法的模型进行训练,从而得到最优化神经网络模型,包括:
[0062]
初始化n=1,以第n个车辆状态参数vn作为当前第n个动作神经模型的输入,由所述当前第n个动作神经模型输出第n个输出值f(vn|ina_first);
[0063]
以第n个车辆状态参数vn、第n个车辆动作参数an和动作网络的第n个输出值f(vn|ina_first)均作为当前第n个评价模型的输入,由第n个车辆状态参数 vn和第n个车辆动作参数an经过当前第n个评价模型输出第n个输出值fn(an);由动作神经模型的第n个输出值f(vn|ina_first)经过当前第n个评价模型输出第 n个输出值fn(f(vn|ina_first));
[0064]
以更新后的第n个车辆状态参数vn_new作为当前第n个目标动作神经模型的输入,
由当前第n个目标动作神经模型输出第n个输出值f(vn_new|ina_target);
[0065]
以更新后的第n个车辆状态参数vn_new和目标动作神经模型的第n个输出值f(vn_new|ina_target)作为当前第n个目标评价模型的输入,由当前第n个目标评价模型输出第n个输出值f
′
n(an_vew);
[0066]
根据当前第n个评价模型的第n个输出值fn(f(vn|ina_first))利用自然梯度法对当前第n个动作神经模型进行更新,从而得到第n次更新后的动作神经模型并作为第n+1个动作神经模型;
[0067]
以当前第n个评价模型的输出fn(an)以及当前第n个目标评价模型的输出 f
′
n(an_new),利用最大似然损失对当前第n个评价模型进行更新,从而得到第 n次更新后的评价模型并作为第n+1个评价模型;
[0068]
如果n+1>n则表明得到最优神经网络模型,如果n《n,重复步骤,直到n》n。
[0069]
第二方面,本发明提供一种线控转向系统传动比优化控制装置,包括:
[0070]
车辆参数获取单元,用于获取汽车在路面行驶时的车辆参数;
[0071]
预处理单元,用于对所述车辆参数进行预处理,获取预处理后的车辆参数;
[0072]
计算调整单元,用于将所述预处理后的车辆参数输入预先训练过的深度强化学习算法中,得到实时的线控转向传动比,基于传动比的计算值对线控转向系统的值进行实时的调整。
[0073]
与现有技术相比,本发明所达到的有益效果:
[0074]
1、本发明提供一种线控转向系统传动比优化控制方法及装置,根据传统车辆动力学算法,确定基本的传动比选择范围,然后根据深度学习强化算法,根据车辆的状态进行最优化学习,动态的调整转向传动比,让线控转向系统的性能发挥到最优;
[0075]
2、本发明提供一种线控转向系统传动比优化控制方法及装置,利用车辆传感器采集的信号,进行深度学习强化算法计算,优化出转向传动比的实时最佳选择,使得车辆不论在低速转弯、高速转弯、空载、满载等各种状态下均让驾驶员的感受最佳,同时使得车辆的稳定性和舒适性最佳。
附图说明
[0076]
图1是本发明实施例提供的一种线控转向系统传动比优化控制方法的流程图。
具体实施方式
[0077]
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
[0078]
实施例1
[0079]
本实施例介绍一种线控转向系统传动比优化控制方法,包括:
[0080]
获取汽车在路面行驶时的车辆参数;
[0081]
对所述车辆参数进行预处理,获取预处理后的车辆参数;
[0082]
将所述预处理后的车辆参数输入预先训练过的深度强化学习算法中,得到实时的线控转向传动比,基于传动比的计算值对线控转向系统的值进行实时的调整。
[0083]
本实施例提供的线控转向系统传动比优化控制方法,其应用过程具体涉及如下步
骤:
[0084]
步骤(1):实时获得汽车在路面行驶时的车辆参数;所述参数包括:车速、方向盘转角、方向盘角速度、车身俯仰角、车身横摆角速度、车身侧倾角、前轴离地高度、后轴离地高度
[0085]
步骤(2):对测量参数进行预处理,将各个参数进行滤波处理,消除噪点,将各个参数互相校对,确定参数的可用性,针对各个参数,设置对应的范围限值,超过则报警并将功能降级到初始设置的传动比值;
[0086]
步骤(3):对深度强化学习算法进行训练:将处理后的采集参数作为深度强化学习算法的输入,将深度强化学习算法得到的最优传动比作为线控转向系统的输入信号,在汽车继续行驶的过程中,线控转向系统根据算法计算出的值进行传动比的输入,并得到车辆参数的反馈值,将反馈值预处理后再次作为深度强化学习算法的输入;进行多次循环过程,采集每次循环过程中的步骤(1)中的参数数据,并使用该数据对深度强化学习算法进行训练;对步骤(3)进行多次迭代训练,从而得到训练好的深度强化学习算法;所述深度强化学习算法的输出为线控转向系统的传动比;
[0087]
步骤(4):在汽车行驶的过程中,实时采集步骤(1)中的车辆运行参数,并对参数进行预处理,将该预处理后的参数输入至训练好的深度强化学习算法中,得到实时的线控转向传动比,基于传动比的计算值对线控转向系统的值进行实时的调整。
[0088]
深度强化学习算法是其中的核心点,深度强化学习算法的实现步骤主要如下:
[0089]
算法步骤1:利用式(1)定义深度强化学习方法的车辆状态参数v:
[0090]
v={w,α,β,wd,αd,βd}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0091]
理想横摆角速度wd;测量横摆角速度w;理想车身侧倾角αd;测量车身侧倾角α;理想车身俯仰角βd;测量车身俯仰角β;。
[0092]
算法步骤2:利用式(2)定义深度强化学习方法的动作参数a:
[0093]
a={γ}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0094]
式中:线控转向系统角传动比γ,取值为10~20;无单位;
[0095]
算法步骤3:利用式(3)建立深度强化学习方法的奖励函数r:
[0096]
r=rβ+rw+rα+rt
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0097]
其中:rβ为车身俯仰角奖励函数、rw为车身横摆角速度奖励函数、r α为车身侧倾角奖励函数、rt为横向加速度响应时间
[0098]
奖励函数是整个深度强化学习算法的核心,能够引导深度神经网络参数的调整方向。在设计时应该首先给出设计原则,然后根据设计原则再设计具体的奖励函数。本实例中奖励函数设置为3个优先级,优先级越高,则该原则越重要,设计原则为:
[0099]
1级:本发明首要保证的是汽车操纵稳定性能,因此保证横摆角速度控制和横向加速度响应时间是首要任务;
[0100]
2级:侧倾在转向时更容易被客户感知,所以车身的侧倾控制要高于车身的俯仰控制;
[0101]
3级:尽可能的使车身的俯仰也更小;
[0102]
rα车身侧倾角奖励函数如式(4)所示,对应于2级设计原则,公式如下:
[0103][0104]
其中,roll为车身俯仰角;
△
roll=|roll
–
roll_normal|,表示车身俯仰角变化量;所述roll_normal表示在平整路面上汽车的车身侧倾角;max_pitch为
△ꢀ
pitch的最大值,roll_th为
△
pitch的阈值,max_roll≥roll_th≥0;
[0105]
rβ车身俯仰角奖励函数如式(5)所示,对应于3级设计原则,公式如下:
[0106][0107]
其中,pitch为车身俯仰角;δph=|ph
–
ph_normal|,表示车身俯仰角变化量;所述ph_normal表示在平整路面上汽车的车身俯仰角;max_ph为
△
pitch 的最大值,ph_th为δph的阈值,max_ph≥ph_th≥0;
[0108]
rw车身横摆角速度奖励函数如式(6)所示,对应于1级设计原则,设计二次函数作为1级奖励函数,公式如下:
[0109][0110]
其中,yaw为车身横摆角速度;δyaw=|yaw
–
yaw_normal|,表示车身横摆角速度变化量;所述yaw_normal表示在平整路面上汽车的车身俯仰角;max_yaw为δyaw的最大值,yaw_th为δyaw的阈值,max_yaw≥yaw_th≥0;
[0111]
rt车身横向加速度响应时间奖励函数如式(7)所示,对应于1级设计原则,设计二次函数作为1级奖励函数,公式如下:
[0112][0113]
其中,yt为车身横向加速度响应时间;δyt=|yt
–
yt_normal|,表示车身横向加速度响应时间变化量;所述yt_normal表示在平整路面上汽车的车身横向加速度响应时间;max_yt为δyt的最大值,yt_th为δyaw的阈值,max_yt≥ yt_th≥0;
[0114]
算法步骤4:构建深度强化学习方法的计算模型:
[0115]
首先构建初始动作神经网络模型,模型为三层神经网络模型包括:第一层输入层,包含一个神经元,第二层为隐藏层,包含x1个神经元,第三层为包含2 个神经元的输出层;初始化动作参数为ina_first;
[0116]
其次构建评价神经网络模型,模型为三层神经网络模型,包括:第一层输入层,包含两个神经元,隐藏层包含x2个神经元,输出层包含1个神经元,初始化评价参数为inev_first;
[0117]
最后再构建目标神经网络模型,其结构与初始神经网络模型结构相同,且令目标动作参数ina_target=ina_first,构建目标评价神经网络模型,其结构与评价神经网络模型结构相同,且令目标评价参数inev_target=inev_first;
[0118]
算法步骤5:利用初始数据生成n个车辆数据样本:
[0119]
利用经验值或者实车测量值赋值初始车辆状态参数v_inital,并以此车辆状态参数v_inital作为初始神经网络的输入,由该模型输出f(v_inital|ina_first);
[0120]
利用式(8)得到第n个车辆动作参数an:
[0121]
an=f(v_inital|ina_first)(8)
[0122]
根据式(3)获取第n个车辆奖励值rn,并得到更新后的第n个车辆状态参数 vn_new;从而得到获得第n条样本,记为(vn,an,rn,vn_new)
[0123]
重复以上步骤进而得到所需要的n个数据样本;
[0124]
算法步骤6:用步骤5得到的n个车辆数据样本对深度强化学习方法的模型进行训练,从而得到最优化神经网络模型
[0125]
初始化n=1,以第n个车辆状态参数vn作为当前第n个动作神经模型的输入,由所述当前第n个动作神经模型输出第n个输出值f(vn|ina_first);
[0126]
以第n个车辆状态参数vn、第n个车辆动作参数an和动作网络的第n个输出值f(vn|ina_first)均作为当前第n个评价模型的输入,由第n个车辆状态参数vn和第n个车辆动作参数an经过当前第n个评价模型输出第n个输出值 fn(an);由动作神经模型的第n个输出值f(vn|ina_first)经过当前第n个评价模型输出第n个输出值fn(f(vn|ina_first));
[0127]
以更新后的第n个车辆状态参数vn_new作为当前第n个目标动作神经模型的输入,由当前第n个目标动作神经模型输出第n个输出值f(vn_new|ina_target);
[0128]
以更新后的第n个车辆状态参数vn_new和目标动作神经模型的第n个输出值f(vn_new|ina_target)作为当前第n个目标评价模型的输入,由当前第n个目标评价模型输出第n个输出值f
′
n(an_vew);
[0129]
根据当前第n个评价模型的第n个输出值fn(f(vn|ina_first))利用自然梯度法对当前第n个动作神经模型进行更新,从而得到第n次更新后的动作神经模型并作为第n+1个动作神经模型;
[0130]
以当前第n个评价模型的输出fn(an)以及当前第n个目标评价模型的输出 f
′
n(an_new),利用最大似然损失对当前第n个评价模型进行更新,从而得到第 n次更新后的评价模型并作为第n+1个评价模型;
[0131]
如果n+1>n则表明得到最优神经网络模型,如果n《n,重复步骤,直到 n》n;
[0132]
算法步骤7:在车辆运行中,实时测量车辆当前状态参数vt,将状态参数输入到以上得到的最优神经网络模型中,直接输出目前状态下最优化的线控转向提供传动比。
[0133]
实施例2
[0134]
本实施例提供一种线控转向系统传动比优化控制装置,包括:
[0135]
车辆参数获取单元,用于获取汽车在路面行驶时的车辆参数;
[0136]
预处理单元,用于对所述车辆参数进行预处理,获取预处理后的车辆参数;
[0137]
计算调整单元,用于将所述预处理后的车辆参数输入预先训练过的深度强化学习算法中,得到实时的线控转向传动比,基于传动比的计算值对线控转向系统的值进行实时的调整。
[0138]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1