基于机器听觉的全流程自动化异音镜头检测方法
本发明涉及机械结构及计算机,尤其涉及一种基于机器听觉的全流程自动化异音镜头检测方法。
背景技术:
1、结构健康监测是利用现场传感系统和相关分析技术来实时评估结构的健康状况和动态特性。在过去的二十年中,结构健康监测(shm)已成为航空、机械工程和土木工程等领域中一个重要且快速发展的研究学科。结构健康监测中的损伤识别系统包括信号监测、处理和解释三个主要步骤。
2、声音是信息的重要载体,是人类感知周围世界的重要途经。由于声音信号具有获取方便、非接触等优点,已经广泛应用于螺栓松动检测、列车塞拉门故障检测、微型电机故障检测等系统损伤监测领域。
3、最初很多领域的基于声音信号的结构健康监测主要是通过人工的分辨,带来效率低、成本高、稳定性差等问题。目前基于音频分类的机器学习检测技术快速发展,基于机器听觉的结构健康监测前景广阔。但是每种方法各有优缺点,只有了解并根据应用场景合理的选择特征提取和分类方法,才能更好的推动机器听觉在结构健康监测的发展。
4、近年来,随着对镜头成像质量要求的提高,镜头的制造要求越来越严苛。除了镜头内部部品的参数要求会影响到镜头的光学性能和质量外,镜头是否组装到位也影响其整体的成像效果。镜头内部的部品如果组装不到位,会造成光路倾斜,导致成像不清晰。因此,检测镜头是否组装到位在镜头质量检测中是十分重要的一步。
5、因松动或错位导致的不符合成像标准的镜头,由于振动时产生异于合格镜头的声音而被称为异音镜头。异音产生的原因是,当镜头装配不到位,如松动或者错位时,若镜头振动,除了镜头整体的振动外,失配位置会产生额外的振动,由于是局部振动,其频率一般较正常镜头的整体振动频率高。目前尚无针对异音镜头的自动化检测方法,导致在实际生产中,异音镜头只能通过经验丰富的工人手工检测,因此带来成本高、效率低、稳定性差等问题。业界亟需全流程自动化异音镜头检测方法。
技术实现思路
1、本发明的目的在于针对现有技术的不足,特别是结构健康监测技术在异音镜头检测的空白,提供一种基于机器听觉的全流程自动化异音镜头检测方法。
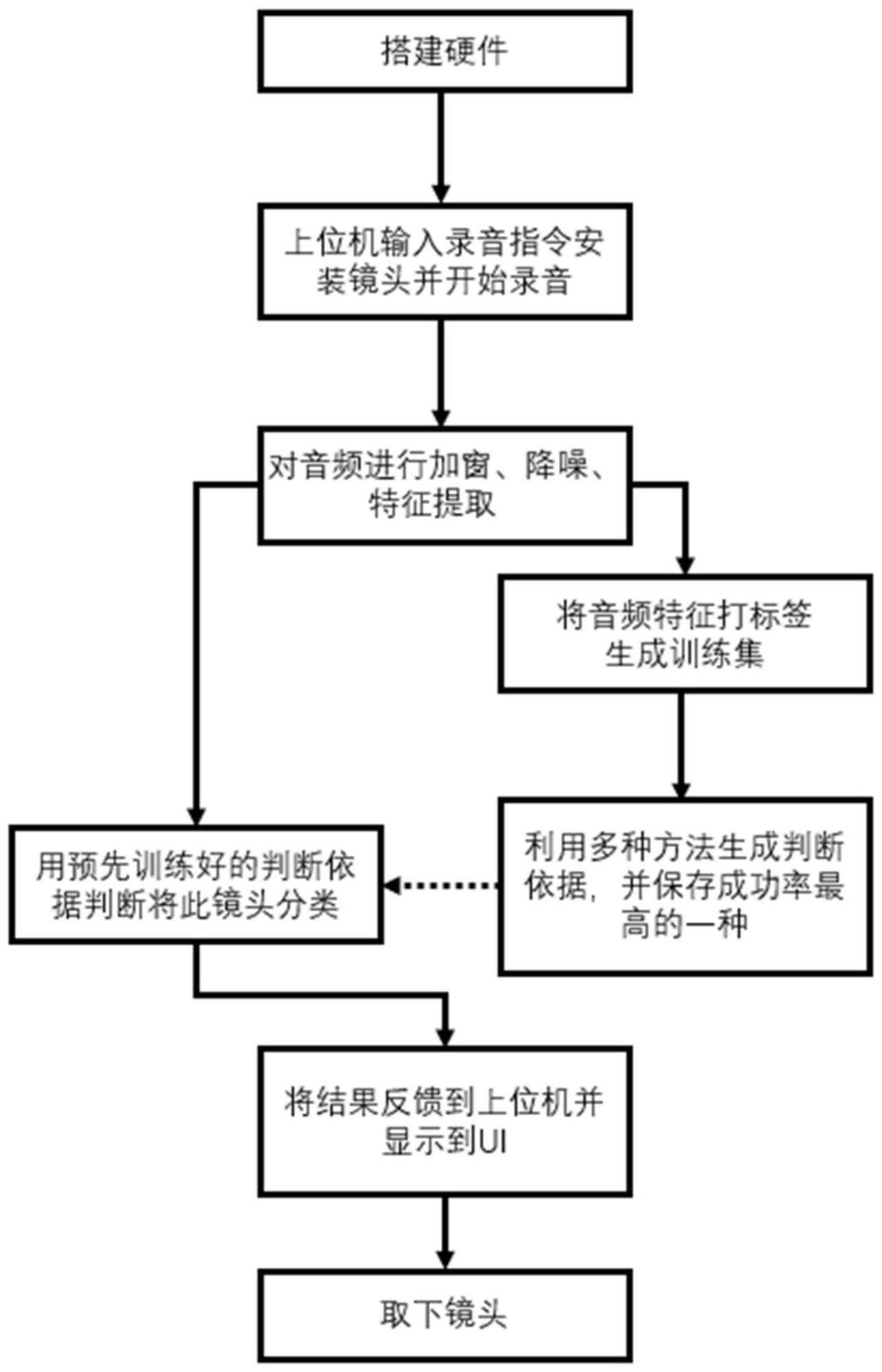
2、本发明的目的是通过以下技术方案来实现的:一种基于机器听觉的全流程自动化异音镜头检测方法,包括以下步骤:
3、步骤一:搭建音频采集设备;
4、步骤二:将上位机与音频采集设备进行通信连接,将多个同一型号且具有不同异音程度的镜头分别填装在音频采集设备上;通过音频采集设备采集镜头的音频;音频采集设备将采集的音频传输至上位机并根据镜头的异音程度添加音频标签;所述镜头的音频标签分为大异音、中异音、小异音以及无异音;
5、步骤三:在上位机上将录制的音频进行加窗分段;加窗分段后的音频保留音频标签;
6、步骤四:对加窗分段后的音频进行特征提取;
7、步骤五:将提取的特征和相应音频标签整合为数据集,通过支持向量机、最近邻法、随机森林算法分别构建检测模型,采用十折交叉验证法利用数据集对检测模型进行训练并输出检测模型分类的成功率,比较三种检测模型输出的成功率,保存成功率最高的检测模型;
8、步骤六:更换不同型号的镜头,重复步骤二到步骤五的操作,直到所有镜头型号的音频都获得对应的检测模型;
9、步骤七:在实际检测中,采集待检测镜头的音频并按照步骤三和步骤四的操作对音频进行加窗分段以及特征提取;根据待检测镜头的型号选择保存的检测模型,对提取特征后的音频进行检测,并将检测结果在上位机进行显示。
10、作为本发明的优选方案,所述步骤一中:音频采集设备包括音圈电机、舵机、微型麦克风、硅胶垫、支撑板、隔音海绵、支撑壁以及底座;
11、音圈电机的下端固定设置在底座上,音圈电机的上端固定有支撑板,支撑板上一周围绕有支撑壁,支撑板与支撑壁形成一个空腔,支撑壁的内壁面铺设有隔音海绵;麦克风设置在空腔的底端并与支撑板固定;空腔还用于放置镜头;
12、转向杆的一端设置在底座上,转向杆的另一端连接有舵机,舵机上设置有硅胶;镜头放置在空腔内时,舵机运动使得硅胶垫能够压紧待测镜头。
13、作为本发明的优选方案,步骤三中将录制的音频进行加窗分段具体为:去除音频前后各2-4万个音频数据点后,将音频均匀分成4-6段,取每段中间0.8-1.2w个音频数据点。
14、作为本发明的优选方案,步骤四中对音频进行特征提取具体为:对加窗分段后的音频x(t)作快速傅里叶变换得到傅立叶谱x(jw);之后再通过公式计算:фxx(w)=x(jw)2/t;其中t为音频的持续时间。
15、作为本发明的优选方案,步骤七中采集待检测镜头的音频通过音频采集设备进行采集。
16、作为本发明的优选方案,步骤五中比较三种检测模型输出的成功率,具体为:分别计算每个检测模型对同一型号镜头的四种音频标签分类成功率的平均值,选择平均值最大的检测模型作为用于检测这一型号镜头异音程度的检测模型。
17、作为本发明的优选方案,步骤五中采用十折交叉验证法具体为:将所有数据集分成10份,不重复地每次取其中9份做训练集训练模型,剩余一份做测试集测试该模型分类的成功率;将10次的成功率取平均值作为最后的成功率。
18、与现有技术相比,本发明具有以下有益效果:
19、1)本发明的异音镜头检测方法,实现了全流程自动化的异音镜头检测,有效提高检测效率,降低生产成本。
20、2)本发明考虑在实际生产中,异音镜头只能通过经验丰富的工人手工检测,能够投入的时间以及人员有限,获取的不同异音程度的镜头数量有限;采用三种不同的模型建立方法,根据不同模型对于有限数据灵敏度有差异,选择最合适的检测模型进行检测;在训练集有限的的情况下实现了能用于实际应用的检测模型建立。
技术特征:
1.一种基于机器听觉的全流程自动化异音镜头检测方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的异音镜头检测方法,其特征在于,所述步骤一中:音频采集设备包括音圈电机、舵机、微型麦克风、硅胶垫、支撑板、隔音海绵、支撑壁以及底座;
3.根据权利要求1所述的异音镜头检测方法,其特征在于,步骤三中将录制的音频进行加窗分段具体为:去除音频前后各2-4万个音频数据点后,将音频均匀分成4-6段,取每段中间0.8-1.2w个音频数据点。
4.根据权利要求1所述的异音镜头检测方法,其特征在于,步骤四中对音频进行特征提取具体为:对加窗分段后的音频x(t)作快速傅里叶变换得到傅立叶谱x(jw);之后再通过公式计算:фxx(w)=x(jw)2/t;其中t为音频的持续时间。
5.根据权利要求1所述的异音镜头检测方法,其特征在于,步骤七中采集待检测镜头的音频通过音频采集设备进行采集。
6.根据权利要求1所述的异音镜头检测方法,其特征在于,步骤五中比较三种检测模型输出的成功率,具体为:分别计算每个检测模型对同一型号镜头的四种音频标签分类成功率的平均值,选择平均值最大的检测模型作为用于检测这一型号镜头异音程度的检测模型。
7.根据权利要求1所述的异音镜头检测方法,其特征在于,步骤五中采用十折交叉验证法具体为:将所有数据集分成10份,不重复地每次取其中9份做训练集训练模型,剩余一份做测试集测试该模型分类的成功率;将10次的成功率取平均值作为最后的成功率。
技术总结
本发明公开了一种基于机器听觉的全流程自动化异音镜头检测方法,该方法设计了控制镜头安装、振动以产生声音以及录音的硬件设备,并支持网口通信和串口通信控制上述硬件,将收集到的音频通过加窗,降噪,并进行特征提取,进而通过支持向量机、最近邻法、随机森林等机器学习分类方法,将不同异音程度的异音镜头准确区分开。本发明能有效改变目前镜头生产中异音镜头只能通过经验丰富的工人检测的现状,进行高效准确的全流程自动化检测。
技术研发人员:汪凯巍,王路明,蒋奇,刘海斌,高少华,刘貌,李荣华,田鑫睿,潘林,祝飞
受保护的技术使用者:浙江大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!