一种声源定位的高精度实现方法
本发明涉及声源定位的,尤其涉及一种声源定位的高精度实现方法。
背景技术:
1、语音的基本目的是为了人类沟通,即说话人与听者之间的信息传递。随着科技产品的落地化布局,人机交互已覆盖人们生活的各方各面。在人机交互过程中,机器需要完成语音信号的采集、前处理、识别等操作,进而完成人类发出的相应指令。实际环境中,无处不在的各种干扰对信号传输产生很大的影响,例如背景噪声、室内混响以及其他说话人的干扰声等。在阵列信号处理领域中,声源定位估计技术是一项关键的技术。它所需解决的问题是如何在嘈杂的室内环境下,根据麦克风的接收信号估计出目标说话人的入射方向。一旦说话人波束确定后,即可对信号做指定波束的语音增强等处理。在传统算法中,许多研究者不断优化算法来提升定位性能,在一些比较理想的室内环境下,具有良好的估计性能,但在低信噪比或高混响环境下,传统算法无法适应这类嘈杂环境,其性能受到显著性的影响,且实时性也欠佳。
2、近年来,随着硬件的不断更新换代,深度学习得到了突飞猛进的发展。不管是在图像、语音或视频领域,深度学习都成为主要研究工具。相较于传统算法,基于深度学习的声源定位估计能有效提升嘈杂环境下的估计性能,但其在低信噪比和强混响下的性能仍亟待提升。
技术实现思路
1、本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本申请的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
2、鉴于上述现有存在的问题,提出了本发明。
3、因此,本发明解决的技术问题是:现有技术在定位精度上仍具有优化空间,以及环境鲁棒性有待提升的问题。
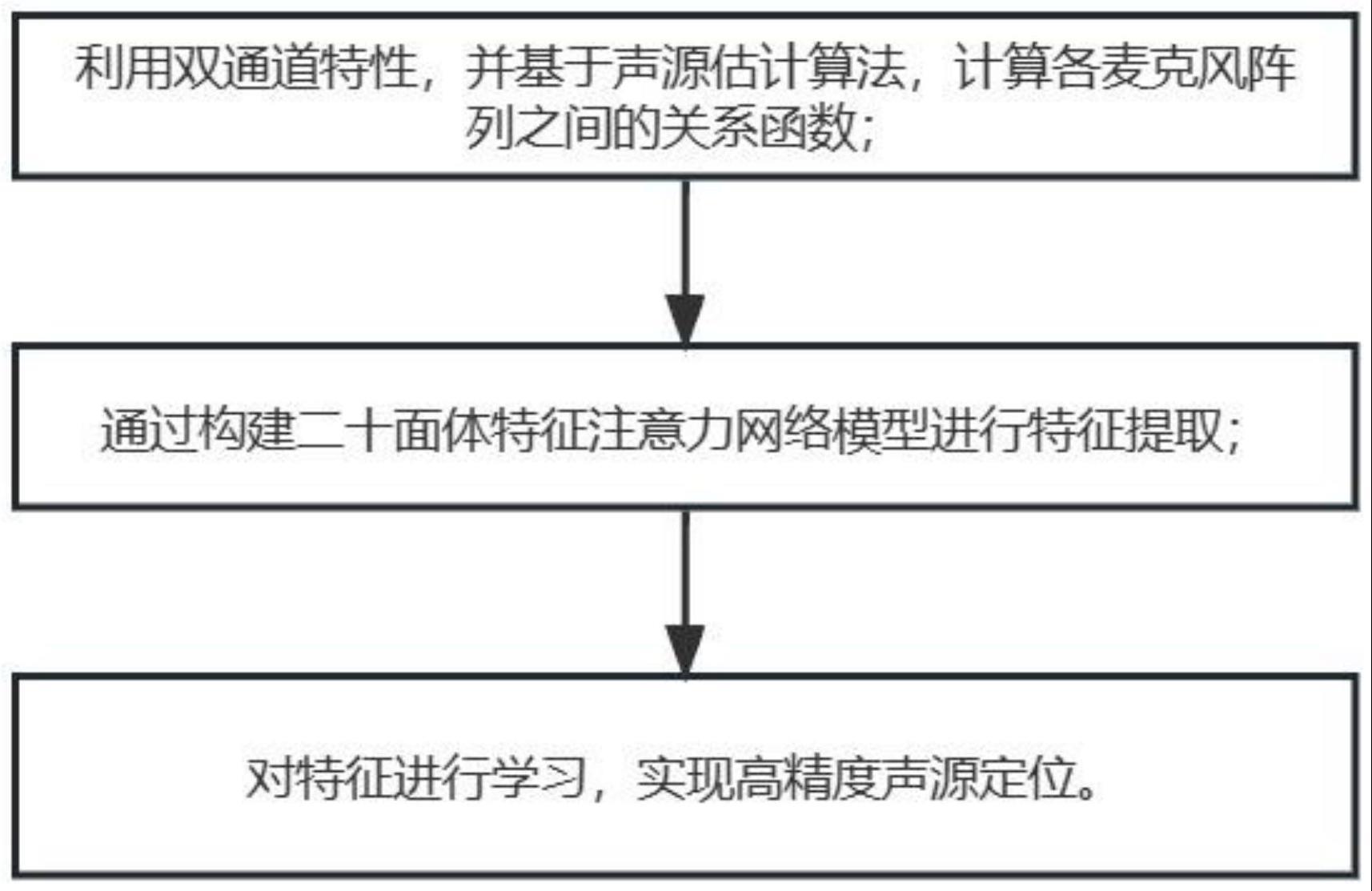
4、为解决上述技术问题,本发明提供如下技术方案:一种声源定位的高精度实现方法,包括:
5、利用双通道特性,并基于声源估计算法,计算各麦克风阵列之间的关系函数;
6、通过构建二十面体特征注意力网络模型进行特征提取;
7、对特征进行学习,实现高精度声源定位。
8、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:所述声源估计算法,包括最小均方自适应算法lms;
9、根据麦克风阵列信号模型,接收的信号表示为x1(n)和x2(n);
10、所述最小均方自适应算法将x1(n)经过滤波器h(n)后的输出信号无限逼近目标信号x2(n),所述输出信号表示为:
11、
12、其中,hopt(n)为最优滤波器,表示为:
13、
14、当取最小均方误差时,滤波器的时间延迟表示为:
15、
16、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:所述声源估计算法,还包括基于相位变换加权的可控响应功率的声源定位算法;
17、所述声源定位算法srp-phat输出功率表示为:
18、
19、其中,m为麦克风总数,θ为声源的方向矢量,τm,n表示从声源到麦克风相对于参考麦克风的延迟差;
20、所述声源定位算法srp-phat表示为:
21、
22、通过对波束输出功率进行峰值检测得到声源的方位信息。
23、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:结合所述最小均方自适应算法和声源定位算法得到一种基于最小均方自适应的延迟和波束形成方法srp-lms,所述形成方法srp-lms的输出功率表示为:
24、
25、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:所述二十面体特征注意力网络模型包括特征提取模块、特征残差学习模块、特征注意力权重模块和特征学习模块;
26、通过特征提取模块得出两个特征值作为整个系统提取的特征,随后进入特征残差学习模块、特征注意权值模块和特征融合学习模块,通过对提取的特征进行学习训练,提升定位精度。
27、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:将srp-phat映射和srp-lms映射投入二十面体网格中,得到相应的二十面体srp功率谱图;
28、将二十面体srp功率谱图输入特征提取模块,得到二十面体特征1和二十面体特征2。
29、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:所述二十面体srp功率谱图包括二十面体srp-phat功率谱图和二十面体srp-lms功率谱图,输入特征是维度为b×t×c×r×5×h×w的七维张量;
30、其中,b为批量大小,t为时间维度,c是通道维数,r是二十面体卷积所需的六个通道,开始时输入特征标量r的值为1,5是图表的数量,h和w分别为输入特征的二十面体网格的长度和宽度。
31、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:所述特征残差学习模块包括卷积层、relu激活层和残差结构;
32、对特征残差学习模块的输入二十面体特征1和二十面体特征2得到增强特征1和增强特征2。
33、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:所述特征注意力权重模块包括归一化、卷积层、relu激活函数、sigmod激活函数和池化层;
34、所述特征注意力权重模块的输入为所述特征残差学习模块的输入和输出特征;
35、对增强特征采用二十面体层归一化层得到输入通道维度和二十面体卷积通道维度上相对应的描述符,所述描述符f表示为:
36、f=lnormico(增强特征)
37、所述描述符f经过两个卷积层以及一个relu函数激活,最后结合sigmod层,反馈两类特征在不同环境下的自适应权系数,所述自适应权系数w表示为:
38、w=sigmoid(icoconv(ρ(icoconv(f))))
39、其中,sigmoid为sigmoid激活函数,ρ表示relu激活函数,icoconv为二十面体卷积。
40、作为本发明所述的声源定位的高精度实现方法的一种优选方案,其中:将所述自适应权系数与增强特征1和增强特征2相乘得到自适应特征;
41、将输入的二十面体特征1和二十面体特征2与自适应特征相加结合得到融合特征;
42、所述融合特征结合了二十面体卷积核和一维卷积的学习前一帧信息;
43、将所述融合特征输入特征学习模块,得到静态和动态声源定位信息。
44、本发明的有益效果:本发明提供的一种声源定位的高精度实现方法,通过提出一种二十面体特征注意力网络模型满足了人工智能领域和工业领域对高精度声源定位的迫切需求,减少目前高精度声源定位的实现成本,有着很好的实用性。
技术特征:
1.一种声源定位的高精度实现方法,其特征在于,包括:
2.如权利要求1所述的声源定位的高精度实现方法,其特征在于:所述声源估计算法,包括最小均方自适应算法lms;
3.如权利要求2所述的声源定位的高精度实现方法,其特征在于:所述声源估计算法,还包括基于相位变换加权的可控响应功率的声源定位算法;
4.如权利要求3所述的声源定位的高精度实现方法,其特征在于:结合所述最小均方自适应算法和声源定位算法得到一种基于最小均方自适应的延迟和波束形成方法srp-lms,所述形成方法srp-lms的输出功率表示为:
5.如权利要求4所述的声源定位的高精度实现方法,其特征在于:所述二十面体特征注意力网络模型包括特征提取模块、特征残差学习模块、特征注意力权重模块和特征学习模块;
6.如权利要求5所述的声源定位的高精度实现方法,其特征在于:将srp-phat映射和srp-lms映射投入二十面体网格中,得到相应的二十面体srp功率谱图;
7.如权利要求5或6所述的声源定位的高精度实现方法,其特征在于:所述二十面体srp功率谱图包括二十面体srp-phat功率谱图和二十面体srp-lms功率谱图,输入特征是维度为b×t×c×r×5×h×w的七维张量;
8.如权利要求7所述的声源定位的高精度实现方法,其特征在于:所述特征残差学习模块包括卷积层、relu激活层和残差结构;
9.如权利要求8所述的声源定位的高精度实现方法,其特征在于:所述特征注意力权重模块包括归一化、卷积层、relu激活函数、sigmod激活函数和池化层;
10.如权利要求9所述的声源定位的高精度实现方法,其特征在于:将所述自适应权系数与增强特征1和增强特征2相乘得到自适应特征;
技术总结
本发明属于声源定位的技术领域,公开了一种声源定位的高精度实现方法,包括利用双通道特性,并基于声源估计算法,计算各麦克风阵列之间的关系函数;通过构建二十面体特征注意力网络模型进行特征提取;对特征进行学习,实现高精度声源定位。本发明提供的一种声源定位的高精度实现方法,通过提出一种二十面体特征注意力网络模型满足了人工智能领域和工业领域对高精度声源定位的迫切需求,减少目前高精度声源定位的实现成本,有着很好的实用性。
技术研发人员:许宜申,朱欣程,冯慧涛,姜余杰,邱志昕,颜明轩,蒋宇阳,吴彦昊,张晓俊,陶智
受保护的技术使用者:苏州大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!