一种基于VMD-GA-BiLSTM的月降水量预测方法
本发明属于深度学习及气象预测研究领域,具体涉及一种基于vmd-ga-bilstm的月降水量预测方法。
背景技术:
1、月降水量预测研究对于农业工作方面有一定的指示作用,农业工作者根据未来月降水量变化情况实施作业,在恰当的时机进行播种、施肥、灌溉等工作,可以保证农业工作高质量完成。同时,根据降水预测结果,及时准备防旱防涝等措施,可以减少天气变化对农作物的影响。由此可见,深入研究降水预测理论与技术,把握未来时刻降水的变化趋势,对洪涝干旱的防治以及水资源利用和存储等都有非常重要的意义。近年来,全球气候变暖,极端降水事件频繁发生,尤其在汛期阶段,频发的降水严重威胁了人们的生命财产安全。降水是一个高度复杂的非线性过程,其发生的天气学条件非常复杂,加上易受地形、海拔等各种因素的影响,因此降水量的预测难度大,预测的准确率一直也是研究人员们关注的焦点之一。目前,在人工智能技术迅速发展的背景下,因为深度学习算法能够高效处理庞大数据的特征信息,学习到气象要素间的作用规律,更能准确描述降水的非线性变化过程,众多研究人员已经将深度学习算法应用到降水预测方向上。现阶段对于月降水量的预测研究只考虑到历史时刻降水量的时序特征,忽略了未来时刻降水量变化规律与当前时刻降水量的联系。其次,月降水量数据,逐月之间不具有较强的时间相关性,降水量数据变化幅度较大,平稳性较差,会导致模型提取特征不充分且训练压力大。
2、本发明建立月降水量预测模型,致力于深度挖掘月降水量数据的时序特征,降低月降水数据的非平稳性,提高预测精度。
技术实现思路
1、本发明为解决目前在月降水量预测过程中,挖掘降水数据的时序特征的片面性和不充分性,以及人工设定网络参数的局限性等问题,提供一种基于vmd-ga-bilstm的月降水量预测方法,实现自主学习降水的时序特征,降低降水数据的非稳定性,并预测未来月降水量变化趋势。
2、本发明以月降水量为研究对象,首先,使用bilstm网络,考虑历史和未来两个方向的时序信息,挖掘降水量变化更深层次的特征。其次,由于降水数据不具有平稳性,变化幅度大,时间相关性不明显,导致模型不能充分提取时序特征且模型训练压力大,vmd方法可以将原始数据从时域转换到频域,得到多个在不同频域上的子序列,每个子序列的非线性特征具有一定变化规律,所以采用vmd方法降低降水数据的非平稳性,可以减轻模型提取时序特征的压力。最后,由于遗传算法有变异机制,可以降低模型训练时陷入局部最优的风险,且参数更新具有随机性,鲁棒性更强,更适合较复杂的求解过程,所以采用遗传算法优化bilstm超参数。从而建立基于vmd-ga-bilstm的月降水量预测模型,并与bilstm、vmd-bilstm和ga-bilstm进行实验对比,总结模型的优势和不足。
3、本发明具体提供以下技术方案。
4、一种基于vmd-ga-bilstm的月降水量预测方法,实现过程分三个步骤:
5、第一步骤:数据的预处理:脏数据清洗、数据归一化和降水数据集的重构;
6、第二步骤:采用vmd方法将原始降水数据分解为若干个子序列;
7、第三步骤:建立bilstm网络模型,并使用遗传算法优化网络参数,将各个子序列输入模型进行训练和预测并对比分析实验结果。
8、进一步地,所述第一步骤中:
9、1)脏数据清洗:由于气象观测站仪器偶然发生故障或其他不确定因素会导致原始数据缺失,使用前一观测时刻的降水数据对其填充;
10、2)数据归一化:为可以加快收敛过程,在数据输入神经网络前,采用归一化方法将数据限定在一定的范围内,采用min-max的归一化方法;
11、3)降水数据集的重构:使用滑动窗口重构数据集,获得连续时刻的多元时间特征,得到多组输入输出数据,并划分训练集和测试集。
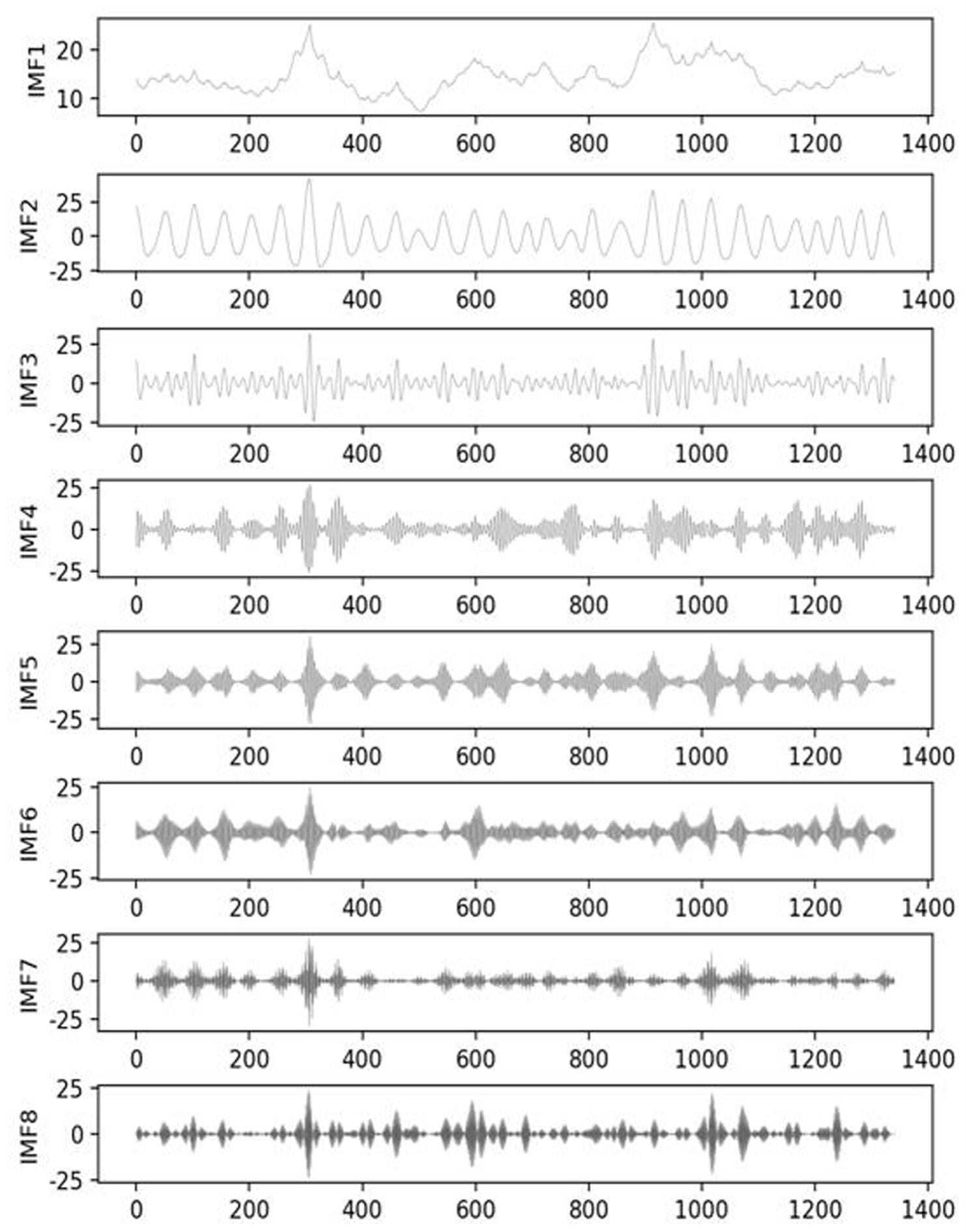
12、进一步地,所述第二步骤中,使用vmd方法将原始数据从时域转换为不同频域上的8个子序列。
13、进一步地,所述第三步骤中,建立基于遗传算法优化的bilstm网络模型(记作ga-bilstm),将第二步骤获得的子序列输入模型进行训练和测试并对比分析实验结果;
14、1)构建bilstm网络模型:初始化bilstm模型的网络参数,包括正向层和反向层的神经元数量、学习率、全连接层神经元数量;设置网络结构,包括输入层、bilstm层、平铺层和全连接层;
15、2)在遗传算法中,定义染色体编码方式、初始化种群、设置适应度函数和遗传操作(包括选择、交叉和变异)过程;
16、3)将第二步骤的子序列输入vmd-ga-bilstm模型进行训练,将bilstm模型中每一轮迭代后得到的准确率作为遗传算法的适应度函数值,作为评估当前种群优劣的标准,在遗传算法中,不断地更新种群,当达到最大种群迭代次数后,当前的种群即为各网络参数的最优组合;
17、4)将测试集的各个子序列输入模型,得到的各分量预测结果并叠加得到最终月降水量预测值,进行实验对比分析。
18、与现有技术相比,本发明具有以下有益效果。
19、本发明对月降水量预测研究方向具有重要的学术意义和应用参考价值。本发明针对月降水量数据不具有平稳性,会导致模型提取时序特征不充分的问题,且经典lstm网络没有考虑到未来时刻降水量变化特征对当前时刻降水量的影响,本方法以辽宁省本溪市明山区观测站逐月降水量数据为研究对象,使用滑动窗口构建数据集,得到多组具有多元时间特征的输入输出数据。首先采用了vmd方法将原始数据分解为多个子序列,有效降低了数据的非平稳性,然后使用bilstm网络对数据进行训练和测试,最后结合遗传算法优化超参数,建立了基于vmd-ga-bilstm月降水量预测模型,经过与bilstm、ga-bilstm和vmd-bilstm进行对比分析,实验结果表明,首先,遗传算法能够获得更适合的网络参数,提高了预测精度,增强了模型的鲁棒性,验证了遗传算法优化bilstm的有效性和可行性;其次,vmd方法可以减轻模型提取时序特征的压力,并能充分学习月降水数据的变化规律,提升了模型预测精度。
20、本发明给出的vmd-ga-bilstm模型与其他模型相比,具有更低的误差,r2达到了0.98。体现了vmd-ga-bilstm模型在月降水量预测上的优势。本发明的vmd方法从数据本身出发,提高了模型预测能力的上限,为月降水量人工预测提供了新思路。
技术特征:
1.一种基于vmd-ga-bilstm的月降水量预测方法,其特征在于,实现过程分三个步骤:
2.根据权利要求1所述的一种基于vmd-ga-bilstm的月降水量预测方法,其特征在于,所述第一步骤中:
3.根据权利要求1所述的一种基于vmd-ga-bilstm的月降水量预测方法,其特征在于,所述第二步骤中,使用vmd方法将原始数据从时域转换为不同频域上的8个子序列。
4.根据权利要求1所述的一种基于vmd-ga-bilstm的月降水量预测方法,其特征在于,所述第三步骤中,建立基于遗传算法优化的bilstm网络模型(记作ga-bilstm),将第二步骤获得的子序列输入模型进行训练和测试并对比分析实验结果;
技术总结
本发明属于深度学习及气象预测研究领域,具体涉及一种基于VMD‑GA‑BiLSTM的月降水量预测方法。第一步骤:数据的预处理:脏数据清洗、数据归一化和降水数据集的重构;第二步骤:采用VMD方法将原始降水数据分解为若干个子序列;第三步骤,建立BiLSTM网络模型,并使用遗传算法优化网络参数,将各个子序列输入模型进行训练和预测并对比分析实验结果。使用该方法,实现自主学习降水的时序特征,降低降水数据的非稳定性,并预测未来月降水量变化趋势。
技术研发人员:于霞,张博臻,宋杰,段勇,李冰洁,陈晓达,娄宇泉,刘鼎歆,刘先康
受保护的技术使用者:沈阳工业大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!