一种基于汉语音位特征的文本查重方法与流程
本发明涉及属于数据处理领域,具体涉及一种基于汉语音位特征的文本查重方法。
背景技术:
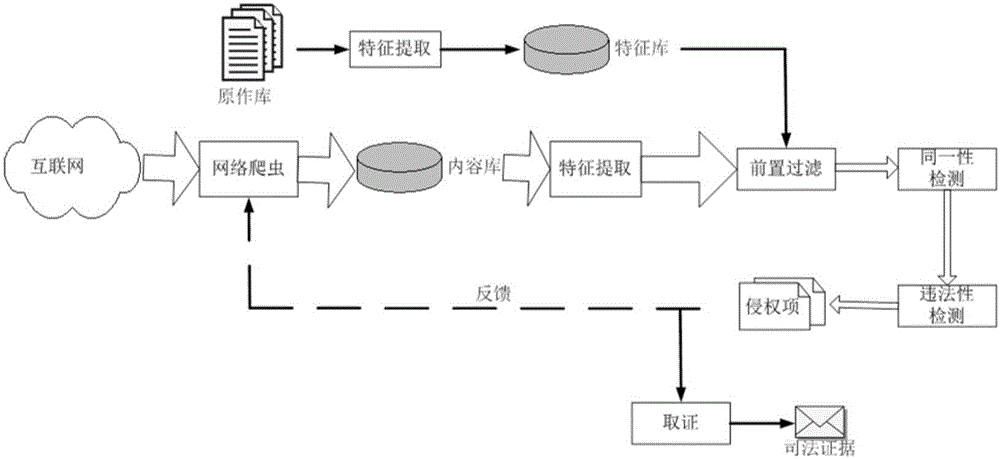
:文本查重是根据一定相似度模型从数据流中发现相重文本的过程。它在搜索引擎构建、抄袭检测、新闻分类等领域有广泛的应用。文本查重是一种特殊的文本过滤,过滤条件是目标文本与源文本相似度大于阈值。传统的文本查重方法基于两种基础技术:文本向量空间模型和文本指纹,前者解决相似性度量的问题,后者优化检索。向量空间模型的作用是将无结构的文本表示成计算机易处理的特征向量,文本间的相似性问题随之转变成向量间距离的问题。特征提取算法包括TF-IDF(TermFrequency-InverseDocumentFrequency)、词频方法、互信息方法、信息增益方法等。其中TF-IDF用关键词的权重做特征,权重计算兼顾了关键词在全局的重要性和在局部的频率这两种信息,使用广泛,是经典方法。有些应用场合需修改TF-IDF的权重公式以优化排序。针对中文,有些应用在特征选取中考虑了词频,也考虑了标点符号,并且将文本的位置因素加入在内;一些应用提出"动词中心词"的概念,将文本中的部分动词组成动词序列作为一种特征;一些应用用以中文句号为基础的特征实现了大规模的新闻网页查重。特征向量确定后,文本间的相似性可用某种空间距离来表示,如余弦距离、数量积、相关系数、指数相似系数、几何平均最小、算数平均最小等。特征向量与距离公式配合,就可以进行文本查重的计算。现实中某些应用,如Google的搜索引擎对存储空间和计算时间特别敏感,需要使用文本指纹技术。它将文本的特征向量通过Hash函数映射为一定字长比如64bit的二进制数,称为指纹,文本的比较通过指纹进行。长度固定的指纹适合构造指纹库,可进行快速检索。从原始文本到特征向量、再到文本指纹是一个单向不可逆的信息减少的过程。64bit的指纹实际只保留了64维向量空间的方向信息。在各种指纹算法之中,Google的SimHash保留了较多信息,即向量间的相似性,可根据指纹间的海明距离反映文档间的差异程度,因此优于MD5等Hash算法,是主要使用的文本指纹技术。根据Google的经验,64位SimHash值的海明距离在3-5之间可认为是同一文本。中文文本的分词是提取关键词向量的前置步骤。分词算法已非常成熟,基于统计的方法是其主流;与人工智能新技术结合的、基于大规模神经网络学习的方法是当前的热点。分词算法至少是O(n2)的复杂度。定性地看,关键词向量可以看做文本“含义”的一种统计表达,大部分文本处理应用如摘要生成、倒排索引、机器翻译等的后续计算需要对文本的含义作一定程度的理解,因此分词的计算开销是完全必要的。而在一些特殊应用如盗版检测中,文本查重、判断是否相同文本是唯一重要的计算,“含义”并不是必须的。对这些应用而言,分词计算开销是一个比较大的负担,如能避免,将加快系统速度。技术实现要素:本发明的目的在于解决现有技术中存在的问题,并提供一种基于汉语音位特征的文本查重方法。本发明是通过以下技术方案来实现的:基于汉语音位特征的文本查重方法,包括如下步骤:S1:选取包括声母、韵母和声调在内的音位特征,使其覆盖汉语拼音标准下包括整体认读音节的所有情况;S2:遍历待查重的两个文档中的所有字,分别得到每个文档中各汉字的声母、韵母和声调在该文档中的频率,并分别将其作为声母、韵母和声调三个空间的向量;再求得两个文档在声母、韵母和声调三个空间的余弦距离;S3:基于得到的三个余弦距离,求得两个文档的相似度,并根据相似度阈值判断两个文档是否重复。作为优选,所述的S1中,音位特征具体为:声母为标准的23个加上零声母:{b,p,m,f,d,t,n,l,g,k,h,j,q,x,zh,ch,sh,r,z,c,s,w,y,none},其中none表示零声母;韵母为标准的24个加10个三拼韵母:{a,o,e,i,u,v,an,en,in,un,vn,ia,ua,uo,ai,ei,ui,ao,ou,iu,ie,ue,er,iang,uang,iong,ang,eng,ing,ong,uai,iao,ian,uan};声调为5种:阴、阳、上、去、轻;根据“ü”去两点的规则,除了nü、lü、nüe、lüe四个音节之外,都作“u”计。作为优选,所述的S2中,针对每个文档,求得两个文档在声母、韵母和声调三个空间的余弦距离的方法如下:设文档d是汉字zk的序列,字长n的文本为d=(z1z2z3…zk…zn)其中zk∈Z,Z为汉字集;汉字zk的音位由声母a、韵母b和声调c组成;对多音字取其第一种发音,则zk=(ak,bk,ck),其中ak∈S,bk∈Y,ck∈T;S={s1,s2,s3,…si…s24},是声母集合;Y={y1,y2,y3,…yi…y34},是韵母集合;T={t1,t2,t3,…t5},是声调集合;再计算声母si、韵母yi、声调ti在文档d中的频率f(si,d)、f(yi,d)、f(ti,d),计算公式为:其中I为指示函数,且函数值在参数表达式成立时为1,否则为0;将文档d表示为三个特征向量的组合,其中:对于两个待查重的文档d1,d2,定义其在空间的余弦距离cos_s(d1,d2)、cos_y(d1,d2)和cos_t(d1,d2)分别如下:进一步的,所述的S3中,待查重的文档d1、d2间的相似度Similarity计算公式如下:Similarity=αcos_s(d1,d2)+βcos_y(d1,d2)+θcos_t(d1,d2)其中α、β和θ均为权重系数,且满足α+β+θ=1;权重系数α、β、θ计算公式如下:其中Hs、Hy、Ht是声母、韵母、声调的信息熵,计算公式如下:其中p(si)、p(yi)、p(ti)分别为第i个声母si、韵母yi、声调ti在文档中出现的概率,分别通过对大语料统计的频率值来近似。再进一步的,所述的S3中,相似度阈值采用如下方法确定:利用包含多个文本的汉语语料D,首先对其掺入噪声获得语料D’;语料D={di}掺噪声后得语料D’={di’},对每对文本di与di’,提取文字音位的声母、韵母和声调成分,计算各成分频率,获得向量和之后计算它们在S、Y、T空间的夹角cos_s(di,di’),cos_y(di,di’)和cos_t(di,di’);按如下公式得一组Similarity参数的计算值:Similarityi=α’cos_s(di,di’)+β’cos_y(di,di’)+θ’cos_t(di,di’)其中,α’、β’、θ’为权重系数估计值,通过将通过对大语料统计的频率值近似得到的p(si)、p(yi)、p(ti),代入α、β、θ计算公式后得到;最后统计{Similarityi}的最小值min(Similarityi)和均方差SD(Similarityi),令相似度阈值gsimilairty为:gsimilairty=min(Similarityi)+SD(Similarityi)。再进一步的,所述的掺噪声的流程如下:1)预先准备包含随机汉字的现代汉语文本的噪声模板;2)对D中的文本d,获取关键词向量及其SimHash指纹u1;3)从噪声模板中随机取一个字z,选择d文档中一随机位置,用z替换原文字;4)获取d文档的新指纹u2;5)计算u1和u2的海明距离H_dist,若H_dist<3,跳转3),循环;若H_dist==3,转6),出循环;若H_dist>3,比较本次掺噪声前的文本和掺噪声后的文本的指纹哪个更接近3,取接近者为输出文本,转6);6)若最终H_dist==3,d的处理结束;否则,若累积尝试次数小于上限,转2),重新开始文本d的掺噪声处理;否则若尝试次数大于上限,结束文本d的掺噪声处理。再进一步的,所述的掺噪声的流程中,若掺入一个字的噪声后导致海明距离跃迁超过预设值,此时回到原状、重新尝试,直至语料中所有文本d都得到了对应的含噪声为海明距离3的相似文本d’。传统文本查重方法基于两种基础技术:以TF/IDF为代表的向量表示和以SimHash为代表的文本指纹。其弱点是必须先进行耗时的分词操作。本发明基于汉语“字”音位均匀的特点,提出基于音位的查重办法。文本被表示为声、韵、调三个空间的向量,相似性以余弦距离度量。相似度模型取三向量的线性组合,其系数由音位元素的信息熵算出。本发明的最大特点是不需进行分词,由于音位频率的计算只需一次内存访问的开销,因此效率高于基于关键词向量的方法。语言是含义和发音的综合物。关键词向量是对含义的统计表达而不顾及其发音;本发明方法利用了汉语的发音而不顾及其含义。定性地考虑,前者相当于人通过默读区分文档,后者相当于不识字的人通过辨音区分文档。两者都是可行的,但必定有各有特点。基于音位的方法优点是不需分词,可以以较快速度实现一定精确率的过滤。它可以单独使用,也可与其他方法联合。在必要的场合,也可通过SimHash产生指纹以加快检索。相对于传统的技术,本发明在如下方面均进行了优化改进:1.提取文本的音位信息,构造特征向量,并计算余弦距离的方法。2.相似度计算公式。3.相似度计算中权重系数的基于信息熵的计算方法。4.以“关键词向量+SimHash指纹”为参照的相似度阈值计算方法。5.基于音位特征判断文档是否相重的流程。附图说明图1为本发明实施例中网络盗版发现系统示意图。具体实施方式下面结合附图和具体实施例对本发明做进一步阐述。中文是极其独特的语言,“字”是独一无二的“音/意”载体,是其他语言没有的构造单位。字的音位构成规整一致,音节占用时长和书写占位大体平均。从字的二进制表示(如Unicode)得到其拼音只需一次内存访问的开销,远低于最好的分词算法。以字的音位统计信息作为特征进行文本查重,符合汉字自身的规律。如能用音位信息代替关键词,或作为关键词向量方法的前置和补充,避免大量分词计算,将提高速度。本发明提出了一套完整的利用音位信息的查重方法。对文本提取声母、韵母、声调三个特征向量,以余弦距离为基本度量;提出了查重操作的流程;提出了相似性公式和求取公式参数的方法。本发明采用的技术方案具体如下:一、音位特征选取国家汉语拼音标准规定了23个声母、24个韵母和16个整体认读音节。本发明选用的音位特征范围如下:1.声母为标准的23个加上零声母,共24个,即:{b,p,m,f,d,t,n,l,g,k,h,j,q,x,zh,ch,sh,r,z,c,s,w,y,none}none表示零声母。2.韵母为标准的24个加10个三拼韵母:ia,ua,uo,uai,iao,ian,iang,uan,uang,iong,共34个,即:{a,o,e,i,u,v,an,en,in,un,vn,ia,ua,uo,ai,ei,ui,ao,ou,iu,ie,ue,er,iang,uang,iong,ang,eng,ing,ong,uai,iao,ian,uan}3.声调为“阴、阳、上、去、轻”5种不变。继承“ü”去两点的规则,除了nü、lü、nüe、lüe四个音节之外,都作“u”计。如此覆盖汉语拼音标准下包括整体认读音节的所有情况,使从汉字到音位的映射可做到1字1声1韵1调。设文本d是字zk的序列,如忽略标点、数字等非汉字元素,字长n的文本为d=(z1z2z3…zk…zn)其中zk∈Z,Z为汉字集。汉字z的音位由声母a、韵母b和声调c组成。若对多音字取其第一种发音,则zk=(ak,bk,ck),其中ak∈S,bk∈Y,ck∈T。S={s1,s2,s3,…si…s24},是声母集合;Y={y1,y2,y3,…yi…y34},是韵母集合;T={t1,t2,t3,…t5},是声调集合。令f(si,d)、f(yi,d)、f(ti,d)是声母si、韵母yi、声调ti在文档d中的频率,即其中I为指示函数,函数值在参数表达式成立时为1,否则为0。则文档d可表示为三个特征向量的组合,其中:设有两个文档d1,d2,可在空间各定义余弦距离如下:以余弦距离cos_s(d1,d2)、cos_y(d1,d2)和cos_t(d1,d2)为基础可对d1、d2间的相似度作出基于音位的度量。二、相似度公式和系数计算文档d1、d2间的相似度Similarity由以下公式计算:Similarity=αcos_s(d1,d2)+βcos_y(d1,d2)+θcos_t(d1,d2)其中α+β+θ=1。查重计算中文本d1,d2相重的条件为:Similarity>gsimilairty,gsimilairty为相似度阈值。权重系数α、β、θ计算公式如下:其中Hs、Hy、Ht是声母、韵母、声调的信息熵,计算公式如下:其中p(si)、p(yi)、p(ti)分别为第i个声母si、韵母yi、声调ti在文本中出现的概率。它们可通过对大语料统计的频率值来近似。设此近似的频率值为p’(si)、p’(yi)、p’(ti),依次代入α、β、θ计算公式中可得权重系数估计值α’、β’、θ’。三、阈值计算相似度公式的阈值gsimilairty的计算用传统的“关键词向量+SimHash指纹”办法作为参照,以行业的经验值、指纹海明距离3作为文档相重的标准。具体做法是,用随机字替换的办法给源文本掺入噪声,直至海明距离为阈值3为止,如此用大量文档作训练,取结果的统计值。如包含多个文本的汉语语料为D,首先对其掺入噪声获得语料D’,掺噪声的流程如下:1)预先准备噪声模板,这是一个包含随机汉字的现代汉语文本。2)对D中文本d,获取关键词向量及其SimHash指纹u1。3)从噪声模板中随机取一个字z,选择d文中一随机位置,用z替换原文字。4)获取d的新指纹u2。5)计算u1和u2的海明距离H_dist。若H_dist<3,跳转3),循环。若H_dist==3,转6),出循环。若H_dist>3,比较本次掺噪声前的文本和掺噪声后的文本的指纹哪个更接近3,取接近者为输出文本,转6)。6)若最终H_dist==3,d的处理结束。否则,若累积尝试次数小于上限(如3000),转2),文本d的掺噪声处理重新开始;否则若尝试次数大于上限,结束该掺噪声处理。有时掺入一个字的噪声会导致海明距离跃迁,比如从2跳到6,此时回到原状、重新尝试,直至语料中所有文本d都得到了对应的含噪声为海明距离3的相似文本d’。语料D={di}掺噪声后得语料D’={di’},对每对文本di与di’,提取文字音位的声母、韵母和声调成分,计算各成分频率,获得向量和之后计算它们在S、Y、T空间的夹角cos_s(di,di’),cos_y(di,di’)和cos_t(di,di’)。按如下公式得一组Similarity参数的计算值:Similarityi=α’cos_s(di,di’)+β’cos_y(di,di’)+θ’cos_t(di,di’)统计{Similarityi}的最小值min(Similarityi)和均方差SD(Similarityi),令:gsimilairty=min(Similarityi)+SD(Similarityi)4、查重操作流程已通过大语料统计获得相似度公式系数的估计值α’、β’、θ’,通过“阈值计算”流程获得参数gsimilairty。判断文档d1、d2是否相重的流程如下:1)对文档d1,遍历所有字zk,取每个字的声、韵、调成分,计算其三个空间的向量2)对文档d2,遍历所有字zk,取每个字的声、韵、调成分,计算其三个空间的向量3)求得余弦距离:4)求得d1、d2相似度Similarity=α’cos_s(d1,d2)+β’cos_y(d1,d2)+θ’cos_t(d1,d2)5)如Similarity≥gsimilairty,则d1、d2相重。否则d1、d2不相重。下面通过给出本发明的一个实施例,使本领域技术人员能够更好地理解本发明。实施例的基本步骤如前所述,不再赘述。对部分具体步骤和参数进行进一步说明。实施例本实施例可用于如图1所示互联网盗版发现系统的前置过滤。出版社、研究单位等拥有大量文字著作权的机构,其文字作品构成原作库;对其中源文本提取音位特征,保存于特征库。网络爬虫连续获取网络文本,存入内容库。对其中内容逐个提取音位信息,用本文方法进行前置过滤,之后再作同一性(查重)检测。同一性为正的未必构成盗版,因此需继续进行违法性检测,找到真正的侵权项目,将其送去取证并反馈给爬虫以优化其策略。网络盗版行为猖獗,但在海量的文本流中涉嫌盗版的毕竟是少数,绝大部分是无关的。由于内容库文本数量巨大,系统效率很大程度取决于能否将这99%以上的无关文本快速排除,因此在精确率和速度之间,系统更关注速度;在精确率和召回率之间,系统更关注召回率。本发明的方法有很好速度和召回率,非常适合做前置过滤。对数据库中的两个待比较的文档,判断文档d1、d2是否相重的流程如下:1)对文档d1,遍历所有字zk,取每个字的声、韵、调成分,计算其三个空间的向量2)对文档d2,遍历所有字zk,取每个字的声、韵、调成分,计算其三个空间的向量3)求得余弦距离:4)求得d1、d2相似度Similarity=α’cos_s(d1,d2)+β’cos_y(d1,d2)+θ’cos_t(d1,d2)5)如Similarity≥gsimilairty,则d1、d2相重。否则d1、d2不相重。系数α’、β’、θ’计算办法如下:对1,411,996篇、共481,065,247字搜狐实验室全网新闻语料作音位统计,结果如表1-3:表1声母频率统计声母bpmfdtnlgk频率4.314%1.723%2.773%2.940%9.419%3.202%1.986%5.022%5.062%1.985%声母hjqxzhchshrzc频率4.365%8.121%3.382%6.185%6.337%3.461%7.218%2.331%3.497%1.639%声母swynone频率1.668%3.264%9.005%1.099%表2韵母频率统计韵母ianguangiongangengingonguaiiaoian频率1.877%0.631%0.033%3.686%3.202%4.040%4.456%0.136%1.741%4.304%韵母uanaieiuiaoouiuieueer频率2.808%3.892%3.287%2.077%3.516%3.496%0.923%1.349%0.974%0.427%韵母aneninunvniauauoao频率4.137%3.088%2.702%1.285%0.000%1.199%0.578%3.056%2.970%0.611%韵母eiuv频率8.386%15.997%6.567%2.569%表3声调频率统计声调yinyangshangquqing频率21.775%21.200%17.134%35.816%4.075%用表中声、韵、调频率值的作为概率值的估计,得到Hs、Hy、Ht的估计值:Hs’=4.3644;Hy’=4.5300;Ht’=2.1081;进而得到模型系数α、β、θ的估计值:α’=0.3967;β’=0.4117;θ’=0.1916。对gsimilairty的获取办法如下,选用包含925个文本共534,924汉字的现代汉语语料,命名为D,首先对其掺入噪声获得语料D’。掺噪声的流程如下:1)预先准备噪声模板NoiseTemplate.txt,这是一个包含7000余字的现代汉语文本。2)对D中文本d,获取关键词向量及其SimHash指纹u1。3)从噪声模板中随机取一个字z,选择d文中一随机位置,用z替换原文字。4)获取d的新指纹u2。5)计算u1和u2的海明距离H_dist。若H_dist<3,跳转3),循环。若H_dist==3,转6),出循环。若H_dist>3,比较本次掺噪声前的文本和掺噪声后的文本的指纹哪个更接近3,取接近者为输出文本,转6)。6)若最终H_dist==3,d的处理结束。否则,若累积尝试次数小于上限3000,转2),文本d的处理重新开始;否则若尝试次数大于上限,结束。若掺入一个字的噪声会导致海明距离跃迁,比如从2跳到6,此时回到原状、重新尝试,直至语料中所有文本d都得到了对应的含噪声为海明距离3的相似文本d’。语料D={di|i=1..925}掺噪声后得语料D’={di’|i=1..925},对每对文本di与di’,提取文字音位的声、韵、调成分,计算各成分频率,获得向量和之后计算它们在S、Y、T空间的夹角cos_s(di,di’),cos_y(di,di’)和cos_t(di,di’),并按如下公式得一组Similarity计算值:Similarityi=α’cos_s(di,di’)+β’cos_y(di,di’)+θ’cos_t(di,di’)最终结果如表4:表4模型参数训练结果均值最大值最小值均方差cos_s0.9780.9920.9530.00174cos_y0.9790.9950.9320.00168cos_t0.9890.9920.9640.00044Similarity0.9810.9890.9620.00140得gsimilairty=0.9634。利用上述gsimilairty对库中的文本进行比较,从而实现互联网盗版发现系统的前置过滤,然后再进行同一性检测和违法性检测,大大提高整体效率。以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关
技术领域:
的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1