一种在DSI索引结构中基于移动对象的k‑NN连续查询方法与流程
本发明属于一种方法改进,在保证网络延迟的情况下,能快速响应移动对象的k-nn连续查询,重点是降低了网络通信消耗和减少服务器计算成本。
背景技术:
处理移动对象的k最近邻(k-nn)查询在很多基于位置的应用程序中是一个基本操作。例如,基于位置社交网络服务可以帮助用户找到k个最接近他/她的其他用户。在基于位置的广告中,一个商店可能希望广播促销信息能是目前最接近商店的潜在客户,其中每个用户或客户可以被认为是一个移动对象。移动对象的k最近邻连续查询能快速响应用户需求,用户能够实时接收到周边环境信息。
传统的连续查询过程如下:
首先服务器接收到用户发来的需求信息,然后服务器分析用户需求信息,用户信息分析之后,服务器会计算用户周围的移动对象,并把结果返回给用户。当同一对象再次进行查询时,服务器会做相同的处理,当用户在同一地点一直进行查询时,服务器就一直重复计算其周围信息,并返回和上一次相同的结果。服务器计算会有一定的延迟,若计算时间过长,可能返回的结果就是以前的,并不是用户当前的需求,因此传统的连续查询并没有考虑网络延迟的问题,而且当对象在网络情况不好的地点进行查询时,结果传输需要时间过长,用户接受到的可能也是以前的信息。
传统的移动对象连续查询的解决方案不能用来处理互联网中大规模的数据,传统的方法都是设计用于在单个服务器上进行的,即对象的维持和更新都是在一个中心位置上,虽然它能处理小的数据量和小的更新,对于海量数据却不适用。
根据传统的方案的不足之处,一些现有的方法对其改进,主要有基于树的索引(如r-tree,r*-tree,tpr*-tree和四叉树)和基于网格的索引对移动对象进行连续查询,这两种索引结构都可以直接采用分布式设置,能够处理海量数据。但这两种结构也存在不足:首先基于树的索引具有复杂的结构,当在分布式集群中对象频繁的移动查询导致成本非常高,每次查询都要遍历树,这对于服务器来说是一个比较大的消耗。基于网格的方法通常需要迭代的扩大搜索区域以进行识别在网格中的单元格集合,来保证包含k-nn搜索的结果,这对于连续查询来说无疑是一个巨大的消耗,同时,这种迭代的次数是不确定的,在分布式设置中,这样的迭代可能导致集群中的节点大量的通信,并因此降低查询处理的性能。
基于动态索引条dynamicstripindex(dsi)索引结构的方法能够很好的处理分布式k-nn查询,也能够实时维护对象的更新,但是这种查询只能对于移动对象的一次查询效果较好,对于同一对象的连续查询往往需要对同一个对象重复大量的计算,这对于服务器来说是一个很大的消耗,并且这种方法并没有考虑网络延迟对于查询结果的影响。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,如服务器的重复计算,网络延迟对于结果的影响等问题,提供一种基于dsi的移动对象的分布式k-nn连续查询方法,保证了同一用户在k-nn查询方面能够快速获得结果,同时减少服务器的消耗。
本发明的主要思想描述如下:
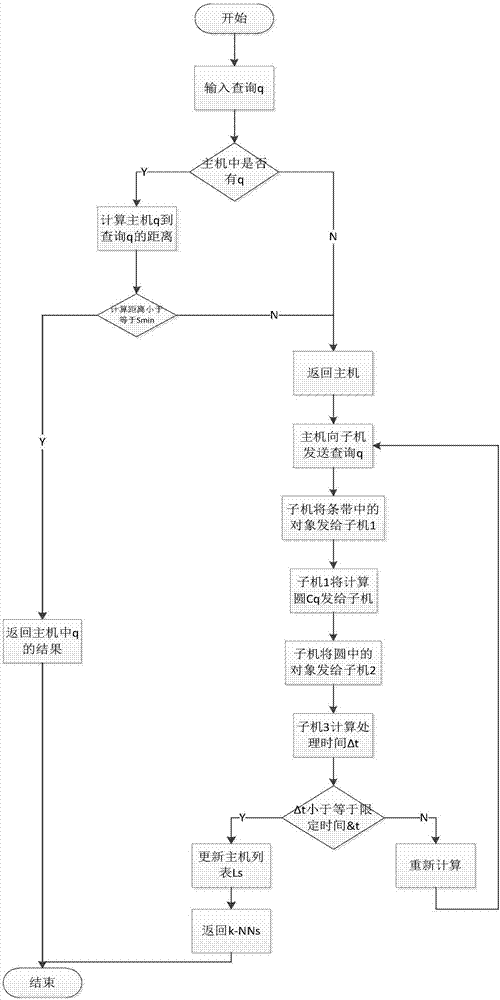
1)如图2所示的运行图,在一个集群中确定一个主机和多个子机,主机用来接收查询对象,子机则用来存储对象。在主机中设置一个查询列表ls,列表内存储已查询过的对象,包括对象的位置以及该对象的查询结果。每次查询开始时总是先访问列表ls,查看列表中是否存在有与此相同的对象,如果有与此相同的对象,则计算此对象与列表中与此相同对象之间的距离,若它们之间的距离小于或等于smin,则将列表中的存储此对象的查询结果表示为此次查询结果。若列表中没有与此相同对象或者有相同对象但距离大于smin,该算法将会重新进行查询,并将查询结果储存在列表ls中,其中smin是由用户设定的。
2)为了控制因处理k-nn连续查询而引起的网络延迟,本发明给出合理的限定时间&t,同时令δt表示查询处理时间,&t明显大于一次查询所需要的平均时间。若δt小于或等于&t,则这次查询有效,然后将有效结果输出并储存在列表ls中;若δt大于&t,说明本次查询结果无效,需要重新运行算法进行查询。
附图说明
图1是本发明所提流程图。
图2是本发明所提方法在分布式设置中的运行图。
具体实施方式
如图1所示的流程图,用户发布查询请求,服务器接收到用户请求之后,服务器会查找其存储列表中是否是此用户的查询信息,若服务器中有此用户的查询信息,则读取存储在服务器中的用户信息,并获得该用户的地理坐标,然后计算服务器中存储该用户的坐标与此时用户正在查询时的坐标的距离,根据计算得出的距离与提出的限定距离smin对比,若计算出的距离小于等于smin,该方法会把存储在服务器中的用户信息返回给用户,从而不用再次计算,减少计算量。同时若服务器中没有该用户信息或者计算得出的距离大于限定距离smin,则主服务器会把查询对象分发给不同的子机,每个子机都是基于dsi索引结构存储数据,能够快速响应,把结果返回子机1,同时计算查询时间δt与限定查询时间&t比较,若δt小于或等于&t则把结果返回给主机,同时主机存储结果并返回给用户。若δt大于&t,则需要重新计算查询结果,主机需要重新发送查询对象到各个子机,重新计算。
以上实施例仅用于说明本发明的技术方案,同时参照实施例对本发明进行了详尽的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换,而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
技术特征:
技术总结
现在有很多应用都涉及到移动对象的k‑最近邻查询任务,处理该问题的大多数现有方法都是进行一次查询处理,这很难用于多次连续查询处理。本发明的目的在于克服现有技术的缺点与不足,提供一种在DSI索引结构中基于移动对象的k‑NN连续查询方法。该方法根据同一移动对象的连续查询情况,首先查找该对象是否被查询过,若被查询过,则计算查询对象的移动距离是否超过限定距离,若没有超过给定的限定距离,则将上次的查询结果作为本次的查询内容。同时根据网络的延迟情况,限定网络延迟时间,若查询时间Δt超过限定时间&t,则查询结果无效,重新进行查询。此方法能有效避免网络延迟对于查询结果的影响,同时减少服务器的计算消耗。
技术研发人员:陈辉;关凯胜
受保护的技术使用者:广东工业大学
技术研发日:2017.04.21
技术公布日:2017.10.10
- 还没有人留言评论。精彩留言会获得点赞!