基于完备局部二值模式重构残差的煤岩识别方法与流程
本发明涉及基于完备局部二值模式重构残差的煤岩识别方法,属于图像识别技术领域。
背景技术:
煤岩识别是指通过各种技术手段自动判别煤炭和岩石。在煤炭资源开采及运输过程中,存在许多生产环节需要判别区分煤炭和岩石,如采煤机滚筒高度调节、综采放顶煤过程控制、选煤厂原煤选矸等。从20世纪50年代开始,南非、澳大利亚、德国、美国、中国等世界主要产煤国家对煤岩识别方法展开了一系列研究,相继产生了一些代表性的研究成果,如自然γ射线探测法、雷达探测法、红外探测法、有功功率检测法、振动信号检测法、声音信号检测法等。然而这些方法均存在以下共性问题:(1)需要在现有设备上安装部署各种传感器,相关装置结构复杂,制造成本高;(2)采煤机、掘进机等机械设备在煤炭生产过程中受力复杂、振动剧烈、磨损严重,传感器部署相对比较困难,其电子线路也容易受到损坏,装置可靠性差;(3)针对不同类型的机械载体设备,传感器的选型和安装位置的选择存在较大区别,这就需要进行个性化定制,因此其普适性不佳。
通过对块状的煤炭、岩石样本的观察,发现煤炭和岩石在颜色、光泽、纹理等方面存在较大差异。当通过现有的数字摄像机对煤炭和岩石进行成像时,煤炭和岩石的视觉信息就必然会隐藏在采集得到的数字图像中,因此提出通过挖掘煤岩数字图像中的视觉信息来区分煤炭和岩石。现有的基于图像处理的煤岩识别方法在鲁棒性、识别率等方面还存在着较大的提升空间。
技术实现要素:
为了克服现有煤岩识别方法存在的不足,本发明提出基于完备局部二值模式重构残差的煤岩识别方法,该方法具有实时性强、识别率高、稳健性好等优点,有助于提高现代煤矿的生产效率和安全程度。
本发明所述的煤岩识别方法采用如下技术方案实现,包括样本训练阶段和煤岩识别阶段,具体步骤如下:
rs1.在样本训练阶段,采集m幅煤炭样本图像和m幅岩石样本图像,截取不含非煤岩背景的子图并对它们进行灰度化处理,处理后的煤炭样本子图和岩石样本子图分别记为c1,c2,…,cm和s1,s2,…,sm;
rs2.设定采样半径r=1和采样邻域数p=8,分别提取c1,c2,…,cm和s1,s2,…,sm的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量y1,y2,…,ym∈r1×200和z1,z2,…,zm∈r1×200;
rs3.设定采样半径r=2和采样邻域数p=16,分别提取c1,c2,…,cm和s1,s2,…,sm的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量α1,α2,…,αm∈r1×648和β1,β2,…,βm∈r1×648;
rs4.设定采样半径r=3和采样邻域数p=24,分别提取c1,c2,…,cm和s1,s2,…,sm的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量η1,η2,…,ηm∈r1×1352和μ1,μ2,…,μm∈r1×1352;
rs5.分别构建c1,c2,…,cm和s1,s2,…,sm的最终特征列向量x1=[y1,α1,η1]t,x2=[y2,α2,η2]t,…,xm=[ym,αm,ηm]t∈r2200×1和xm+1=[z1,β1,μ1]t,xm+2=[z2,β2,μ2]t,…,x2m=[zm,βm,μm]t∈r2200×1,其中t为转置运算;
rs6.分别构建煤炭训练样本特征矩阵xc=[x1,x2,…,xm]∈r2200×m和岩石训练样本特征矩阵xs=[xm+1,xm+2,…,x2m]∈r2200×m;
rs7.设置正则化参数λ1,λ2,迭代次数k和字典原子数τ,其中0<λ1<1,0<λ2<1,15≤k≤50,0<τ≤m,对xc和xs进行判别式字典学习,得到煤炭类别综合型字典dc、岩石类别综合型字典ds、煤炭类别解析型字典tc和岩石类别解析型字典ts;
rs8.在煤岩识别阶段,采集未知类别样本图像,截取不含非煤岩背景的子图并对它进行灰度化处理,处理后的未知类别子图记为q;
rs9.设定采样半径r=1和采样邻域数p=8,提取q的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量vq∈r1×200;
rs10.设定采样半径r=2和采样邻域数p=16,提取q的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量δq∈r1×648;
rs11.设定采样半径r=3和采样邻域数p=24,提取q的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量θq∈r1×1352;
rs12.构建q的最终特征列向量xq=[vq,δq,θq]t∈r2200×1,其中t为转置运算;
rs13.如果满足||xq-dctcxq||2≤||xq-dstsxq||2,那么判定q为煤炭;否则,判定q为岩石,其中||·||2为向量的2–范数。
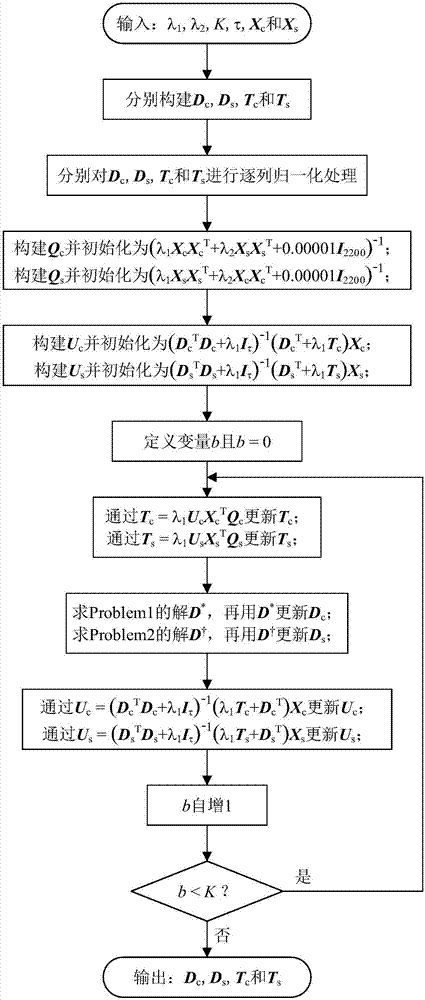
步骤rs7所述的判别式字典学习包括以下步骤:
rs701.从xc中随机地抽取τ列构建煤炭类别综合型字典dc∈r2200×τ,从xs中随机地抽取τ列构建岩石类别综合型字典ds∈r2200×τ,从xc中随机地抽取τ列再通过转置运算构建煤炭类别解析型字典tc∈rτ×2200,从xs中随机地抽取τ列再通过转置运算构建岩石类别解析型字典ts∈rτ×2200,然后分别对dc,ds,tc和ts进行逐列归一化处理;
rs702.构建数据矩阵qc∈r2200×2200并通过qc=(λ1xcxct+λ2xsxst+0.00001i2200)-1初始化,构建数据矩阵qs∈r2200×2200并通过qs=(λ1xsxst+λ2xcxct+0.00001i2200)-1初始化,其中i2200为2200阶单位矩阵,t为转置运算,–1为求逆运算;
rs703.构建煤炭样本稀疏编码矩阵uc∈rτ×m并通过uc=(dctdc+λ1iτ)-1(dct+λ1tc)xc初始化,构建岩石样本稀疏编码矩阵us∈rτ×m并通过us=(dstds+λ1iτ)-1(dst+λ1ts)xs初始化,其中t为转置运算,–1为求逆运算,iτ为τ阶单位矩阵;
rs704.定义迭代序号b并初始化为0;
rs705.通过tc=λ1ucxctqc更新tc,通过ts=λ1usxstqs更新ts;
rs706.把数学描述为
的优化问题记为problem1,用problem1的解d*∈r2200×τ更新dc,其中||·||f为矩阵的frobenius范数,||·||2为向量的2–范数,
rs707.把数学描述为
的优化问题记为problem2,用problem2的解
rs708.分别通过uc=(dctdc+λ1iτ)-1(λ1tc+dct)xc和us=(dstds+λ1iτ)-1(λ1ts+dst)xs更新uc和us,其中t为转置运算,–1为求逆运算,iτ为τ阶单位矩阵;
rs709.迭代序号b自增1;
rs710.如果满足b<k,那么执行步骤rs705–rs710;否则,执行步骤rs711;
rs711.完成字典学习,输出dc,ds,tc和ts。
步骤rs706所述problem1的求解包括以下步骤:
rs70601.定义变量ε1并初始化为1.000,构建数据矩阵d*∈r2200×τ并通过d*=dc初始化;
rs70602.构建临时数据矩阵a1∈r2200×τ并通过a1=dc初始化,构建临时数据矩阵b1∈r2200×τ并初始化为零矩阵,构建临时数据矩阵h1∈r2200×τ并初始化为零矩阵;
rs70603.通过h1=[xcuct+ε1(a1-b1)](ucuct+ε1iτ)-1更新h1,其中iτ为τ阶单位矩阵,t为转置运算,–1为求逆运算;
rs70604.通过a1=b1+h1更新a1;
rs70605.对a1中2–范数大于1的列进行2–范数归一化处理;
rs70606.用(b1+h1-a1)的计算结果更新b1;
rs70607.用(1.25×ε1)的计算结果更新ε1;
rs70608.若满足
rs70609.完成problem1的求解,返回problem1的解d*。
步骤rs707所述problem2的求解包括以下步骤:
rs70701.定义变量ε2并初始化为1.000,构建数据矩阵
rs70702.构建临时数据矩阵a2∈r2200×τ并通过a2=ds初始化,构建临时数据矩阵b2∈r2200×τ并初始化为零矩阵,构建临时数据矩阵h2∈r2200×τ并初始化为零矩阵;
rs70703.通过h2=[xsust+ε2(a2-b2)](usust+ε2iτ)-1更新h2,其中iτ为τ阶单位矩阵,t为转置运算,–1为求逆运算;
rs70704.通过a2=b2+h2更新a2;
rs70705.对a2中2–范数大于1的列进行2–范数归一化处理;
rs70706.用(b2+h2-a2)的计算结果更新b2;
rs70707.用(1.25×ε2)的计算结果更新ε2;
rs70708.若满足
rs70709.完成problem2的求解,返回problem2的解
附图说明
图1是基于完备局部二值模式重构残差的煤岩识别方法的基本流程图;
图2是本发明所述判别式字典学习的基本流程图;
图3是本发明所述求problem1的解d*的基本流程图;
图4是本发明所述求problem2的解
具体实施方式
在对我国河南、山西、陕西等地主要煤种和岩种的图像进行实验分析的基础上,本发明提出了基于完备局部二值模式重构残差的煤岩识别方法,该方法可以有效判别煤炭和岩石。
下面结合附图和具体实施方式对本发明作进一步的详细描述。
参照图1,基于完备局部二值模式重构残差的煤岩识别方法的具体步骤如下:
ss1.在样本训练阶段,采集m幅煤炭样本图像和m幅岩石样本图像,截取不含非煤岩背景的子图并对它们进行灰度化处理,处理后的煤炭样本子图和岩石样本子图分别记为c1,c2,…,cm和s1,s2,…,sm;
ss2.设定采样半径r=1和采样邻域数p=8,分别提取c1,c2,…,cm和s1,s2,…,sm的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量y1,y2,…,ym∈r1×200和z1,z2,…,zm∈r1×200;
ss3.设定采样半径r=2和采样邻域数p=16,分别提取c1,c2,…,cm和s1,s2,…,sm的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量α1,α2,…,αm∈r1×648和β1,β2,…,βm∈r1×648;
ss4.设定采样半径r=3和采样邻域数p=24,分别提取c1,c2,…,cm和s1,s2,…,sm的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量η1,η2,…,ηm∈r1×1352和μ1,μ2,…,μm∈r1×1352;
ss5.分别构建c1,c2,…,cm和s1,s2,…,sm的最终特征列向量x1=[y1,α1,η1]t,x2=[y2,α2,η2]t,…,xm=[ym,αm,ηm]t∈r2200×1和xm+1=[z1,β1,μ1]t,xm+2=[z2,β2,μ2]t,…,x2m=[zm,βm,μm]t∈r2200×1,其中t为转置运算;
ss6.分别构建煤炭训练样本特征矩阵xc=[x1,x2,…,xm]∈r2200×m和岩石训练样本特征矩阵xs=[xm+1,xm+2,…,x2m]∈r2200×m;
ss7.设置正则化参数λ1,λ2,迭代次数k和字典原子数τ,其中0<λ1<1,0<λ2<1,15≤k≤50,0<τ≤m,对xc和xs进行判别式字典学习,得到煤炭类别综合型字典dc、岩石类别综合型字典ds、煤炭类别解析型字典tc和岩石类别解析型字典ts;
ss8.在煤岩识别阶段,采集未知类别样本图像,截取不含非煤岩背景的子图并对它进行灰度化处理,处理后的未知类别子图记为q;
ss9.设定采样半径r=1和采样邻域数p=8,提取q的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量vq∈r1×200;
ss10.设定采样半径r=2和采样邻域数p=16,提取q的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量δq∈r1×648;
ss11.设定采样半径r=3和采样邻域数p=24,提取q的带有旋转不变特性和均匀特性的归一化完备局部二值模式特征行向量θq∈r1×1352;
ss12.构建q的最终特征列向量xq=[vq,δq,θq]t∈r2200×1,其中t为转置运算;
ss13.如果满足||xq-dctcxq||2≤||xq-dstsxq||2,那么判定q为煤炭;否则,判定q为岩石,其中||·||2为向量的2–范数。
参照图2,步骤ss7所述的判别式字典学习的具体步骤如下:
ss701.从xc中随机地抽取τ列构建煤炭类别综合型字典dc∈r2200×τ,从xs中随机地抽取τ列构建岩石类别综合型字典ds∈r2200×τ,从xc中随机地抽取τ列再通过转置运算构建煤炭类别解析型字典tc∈rτ×2200,从xs中随机地抽取τ列再通过转置运算构建岩石类别解析型字典ts∈rτ×2200,然后分别对dc,ds,tc和ts进行逐列归一化处理;
ss702.构建数据矩阵qc∈r2200×2200并通过qc=(λ1xcxct+λ2xsxst+0.00001i2200)-1初始化,构建数据矩阵qs∈r2200×2200并通过qs=(λ1xsxst+λ2xcxct+0.00001i2200)-1初始化,其中i2200为2200阶单位矩阵,t为转置运算,–1为求逆运算;
ss703.构建煤炭样本稀疏编码矩阵uc∈rτ×m并通过uc=(dctdc+λ1iτ)-1(dct+λ1tc)xc初始化,构建岩石样本稀疏编码矩阵us∈rτ×m并通过us=(dstds+λ1iτ)-1(dst+λ1ts)xs初始化,其中t为转置运算,–1为求逆运算,iτ为τ阶单位矩阵;
ss704.定义迭代序号b并初始化为0;
ss705.通过tc=λ1ucxctqc更新tc,通过ts=λ1usxstqs更新ts;
ss706.把数学描述为
的优化问题记为problem1,用problem1的解d*∈r2200×τ更新dc,其中||·||f为矩阵的frobenius范数,||·||2为向量的2–范数,
ss707.把数学描述为
的优化问题记为problem2,用problem2的解
ss708.分别通过uc=(dctdc+λ1iτ)-1(λ1tc+dct)xc和us=(dstds+λ1iτ)-1(λ1ts+dst)xs更新uc和us,其中t为转置运算,–1为求逆运算,iτ为τ阶单位矩阵;
ss709.迭代序号b自增1;
ss710.如果满足b<k,那么执行步骤ss705–ss710;否则,执行步骤ss711;
ss711.完成字典学习,输出dc,ds,tc和ts。
参照图3,求步骤ss706所述problem1的解d*的具体步骤如下:
ss70601.定义变量ε1并初始化为1.000,构建数据矩阵d*∈r2200×τ并通过d*=dc初始化;
ss70602.构建临时数据矩阵a1∈r2200×τ并通过a1=dc初始化,构建临时数据矩阵b1∈r2200×τ并初始化为零矩阵,构建临时数据矩阵h1∈r2200×τ并初始化为零矩阵;
ss70603.通过h1=[xcuct+ε1(a1-b1)](ucuct+ε1iτ)-1更新h1,其中iτ为τ阶单位矩阵,t为转置运算,–1为求逆运算;
ss70604.通过a1=b1+h1更新a1;
ss70605.对a1中2–范数大于1的列进行2–范数归一化处理;
ss70606.用(b1+h1-a1)的计算结果更新b1;
ss70607.用(1.25×ε1)的计算结果更新ε1;
ss70608.若满足
ss70609.完成problem1的求解,返回problem1的解d*。
参照图4,求步骤ss707所述problem2的的解
ss70701.定义变量ε2并初始化为1.000,构建数据矩阵
ss70702.构建临时数据矩阵a2∈r2200×τ并通过a2=ds初始化,构建临时数据矩阵b2∈r2200×τ并初始化为零矩阵,构建临时数据矩阵h2∈r2200×τ并初始化为零矩阵;
ss70703.通过h2=[xsust+ε2(a2-b2)](usust+ε2iτ)-1更新h2,其中iτ为τ阶单位矩阵,t为转置运算,–1为求逆运算;
ss70704.通过a2=b2+h2更新a2;
ss70705.对a2中2–范数大于1的列进行2–范数归一化处理;
ss70706.用(b2+h2-a2)的计算结果更新b2;
ss70707.用(1.25×ε2)的计算结果更新ε2;
ss70708.若满足
ss70709.完成problem2的求解,返回problem2的解
需要指出的是,以上所述实施实例用于进一步说明本发明,实施实例不应被视为限制本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!