一种网页信息的提取方法及装置与流程
本发明涉及互联网应用领域,特别是涉及一种网页信息提取方法。
背景技术:
网页信息提取技术是一项关于从网页中提取目标信息的技术,即从自然语言文本和网页的结构化数据中提取有价值的信息的技术。
现有技术中的网页信息提取采用人工提取方法,通过观察网页及其源代码,由编程人员找出一些规则,再根据这些规则编写程序提取有价值的信息。为了让网页信息提取过程简单一些,编程人员构建了几种模式规范语言及其用户界面。
然而,现有技术中这种采用人工提取的方法至少存在着以下三点不足:首先,对网页中每个站点均需要人工编写规则,当需要抓取大批量的站点时,人工抽取规则并进行编写程序存在一定的错误率,并且成本过大。其次,当站点的页面结构发生变更时,原来的规则失去效力,因此需要人工再次进行规则的抽取及编码,而人工发现页面结构变更不及时导致网页信息提取依据的抽取规则无法实时更新,降低网页信息提取的准确性。另外,人工提取时容易将一下不安全的网页信息也一并进行了提取导致最终提取的内容不安全。
技术实现要素:
本发明的目的是为了解决上述现有技术的不足而提供一种网页信息的提取方法及装置。通过预先将网页内容进行区域化提取,然后将每一个区域进行安全监测,监测完后然后进行内容查阅,最终使得提取的内容相对安全,另外也解决了现有技术中通过人工提取的速度慢、效率低、错误率高的问题。
本发明公开的一种网页信息的提取方法,其具体包括以下步骤:
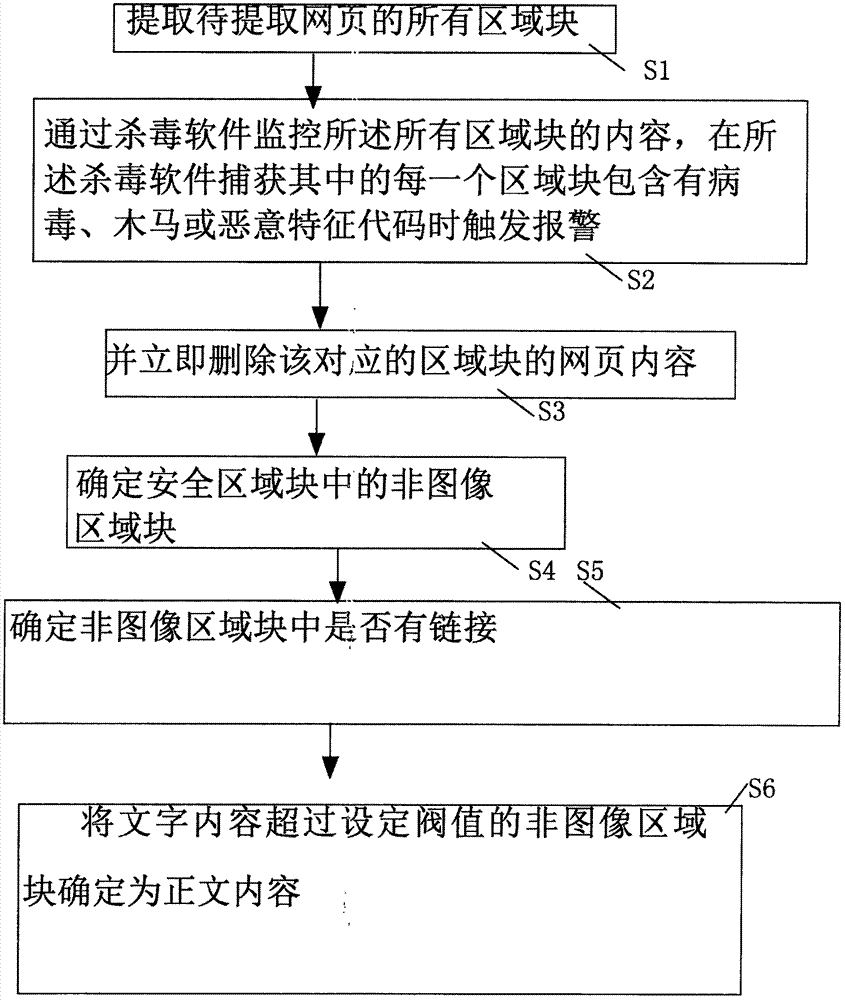
s1:提取待提取网页的所有区域块;
s2:通过杀毒软件监控所述所有区域块的内容,在所述杀毒软件捕获其中的每一个区域块包含有病毒、木马或恶意特征代码时触发报警;
s3:并立即删除该对应的区域块的网页内容;
s4:确定安全区域块中的非图像区域块;
s5:确定非图像区域块中是否有链接;
s6:将文字内容超过设定阀值的非图像区域块确定为正文内容。
进一步,在步骤s4中,确定安全区域块中的非图像区域块包括:
根据获取的安全区域块的对象;
然后利用document.getelementsbytagname(″img″).length>0判断img对象有没有;如果有,直接删除图片;但当是css设置的背景图片,通过读取元素的背景图片查看是否为空;若为空说明没有图片。
进一步,在步骤s4中,确定非图像区域块中是否有链接,若有,直接删除链接部分,若没有,继续步骤s6。
本发明还公开了一种网页信息提取装置,包括采用上述所述的一种网页信息的提取方法,其包括:提取装置,用于提取所述待提取网页的所有区域块;
用于报警提示的报警装置;
用于通过杀毒软件监控所述所有区域块的内容,在所述杀毒软件捕获当前网页包括病毒、木马或恶意特征代码时触发报警装置报警的杀毒软件模块;
对比模块,用于判断是否为文字并进行计数的单元;
链接判断模块,用于判断是否有链接。
进一步,还包括用于判断是否包含图片的图片判断模块。
本发明得到的一种网页信息的提取方法及装置,通过预先将网页内容进行区域化提取,然后将每一个区域进行安全监测,监测完后然后进行内容查阅,最终使得提取的内容相对安全,另外也解决了现有技术中通过人工提取的速度慢、效率低、错误率高的问题。
附图说明
图1是本实施例中一种网页信息的提取方法的流程示意图;
图2是本实施例中一种网页信息提取装置的结构示意图。
附图标记中:1.提取装置;2.报警装置;3.杀毒软件模块;4.对比模块;5.链接判断模块;6.图片判断模块。
具体实施方式
下面结合附图和实施例对本发明进一步说明。
实施例:
如图1、图2所示,本实施例提供的一种网页信息的提取方法,具体包括以下步骤:
s1:提取待提取网页的所有区域块;
s2:通过杀毒软件监控所述所有区域块的内容,在所述杀毒软件捕获其中的每一个区域块包含有病毒、木马或恶意特征代码时触发报警;
s3:并立即删除该对应的区域块的网页内容;
s4:确定安全区域块中的非图像区域块;
s5:确定非图像区域块中是否有链接;
s6:将文字内容超过设定阀值的非图像区域块确定为正文内容。
进一步,在步骤s4中,确定安全区域块中的非图像区域块包括:
根据获取的安全区域块的对象;
然后利用document.getelementsbytagname(″img″).length>0判断img对象有没有;如果有,直接删除图片;但当是css设置的背景图片,通过读取元素的背景图片查看是否为空;若为空说明没有图片。
进一步,在步骤s4中,确定非图像区域块中是否有链接,若有,直接删除链接部分,若没有,继续步骤s6。
本实施例还公开了一种网页信息提取装置,包括采用上述所述的一种网页信息的提取方法,其包括:
提取装置1,用于提取所述待提取网页的所有区域块;
用于报警提示的报警装置2;
用于通过杀毒软件监控所述所有区域块的内容,在所述杀毒软件捕获当前网页包括病毒、木马或恶意特征代码时触发报警装置2报警的杀毒软件模块3;
对比模块4,用于判断是否为文字并进行计数的单元;
链接判断模块5,用于判断是否有链接。
其还包括用于判断是否包含图片的图片判断模块6。
本实施例得到的一种网页信息的提取方法及装置,通过预先将网页内容进行区域化提取,然后将每一个区域进行安全监测,监测完后然后进行内容查阅,最终使得提取的内容相对安全,另外也解决了现有技术中通过人工提取的速度慢、效率低、错误率高的问题。
工作时,当需要提取网页信息时,首选将提取待提取网页的所有区域块;然后通过杀毒软件模块3中的杀毒软件监控所述所有区域块的内容,一旦当所述杀毒软件捕获其中的每一个区域块包含有病毒、木马或恶意特征代码时立即通过报警装置2触发报警;并立即删除该对应的区域块的网页内容;然后将安全的内容进行一一确定安全区域块中的非图像区域块;在图像区域确定时,利用document.getelementsbytagname(″img″).length>0判断img对象有没有;如果有,直接删除图片;但当是css设置的背景图片,通过读取元素的背景图片查看是否为空;若为空说明没有图片,一旦判断无图像后,将剩余的安全区域块判断是否有链接;一旦有,删除,没有最后将文字内容超过设定阀值的非图像区域块确定为正文内容。然后进行提取,从而确保在网页信息提取时的安全、可靠且正确。
技术特征:
技术总结
本发明得到的一种网页信息的提取方法及装置,具体步骤如下:S1:提取待提取网页的所有区域块;S2:通过杀毒软件监控所述所有区域块的内容,在所述杀毒软件捕获其中的每一个区域块包含有病毒、木马或恶意特征代码时触发报警;S3:并立即删除该对应的区域块的网页内容;S4:确定安全区域块中的非图像区域块;S5:确定非图像区域块中是否有链接;S6:将文字内容超过设定阀值的非图像区域块确定为正文内容。通过预先将网页内容进行区域化提取,然后将每一个区域进行安全监测,监测完后然后进行内容查阅,最终使得提取的内容相对安全,另外也解决了现有技术中通过人工提取的速度慢、效率低、错误率高的问题。
技术研发人员:刘俊
受保护的技术使用者:刘俊
技术研发日:2017.08.18
技术公布日:2019.03.01
- 还没有人留言评论。精彩留言会获得点赞!