一种基于属性概率向量引导注意模式的图片描述方法与流程
本发明设计了一种基于属性概率向量引导注意模式的图片描述方法,涉及深度学习,计算机视觉技术领域。
背景技术:
人类感知世界的一个重要特性是不会一次性对整个场景进行处理,而是会将注意力集中在视觉空间的某些部分上,从而获取需要的时间和地点信息,并且随着时间的推进,人类会根据不同固定点的信息来建立场景的内部表示用以指导未来的一系列认知及行动;由于部分场景相对于整个场景的简洁性,这种将‘有限’的脑力资源集中在感知部分重要场景上的机制,直接导致人类处理场景的复杂性降低,因为其可以使得人类一直将场景内感兴趣的对象放置在固定的中心位置,固定区域之外的视觉环境的无关特征被自然地淡化和忽略,这一机制被称为人类视觉注意模式。
由于视觉注意模式是人类进行视觉活动的主要机制,而计算机视觉是为了让计算机能够模仿人类视觉活动的学科,因此计算机视觉各分支问题不可避免的开始探索如何引入视觉注意模式,并在部分问题上已经取得了进展。
近来随着视觉注意模式在计算机视觉部分方面取得了有效的进展,在图片描述问题上也开始引入了视觉注意模式,虽然引入方法不尽相同,但其指导思想都是基于时间t时输出的描述词汇应当与图像的某一部分重点关联的假设。虽然目前基于注意模式的图片描述方法在效果上相比其它模型没有绝对优势,甚至比有些模型效果要差,但是随着对注意模式的不断探索和改进以及对获取编码矩阵方式的优化,基于注意模式的图片描述方法在效果上肯定会越来越好。
在基于注意模式的图片描述模型中,xu等人提出的软注意模型(softattention,soft-att)是非常具有代表性的,但得到的图片描述结果依然不够准确。
技术实现要素:
本发明为解决上述问题提供一种准确率较高的基于属性概率向量引导注意模式(guidingmil-att,gmil-att)的图片描述方法。本发明通过对图片语义信息的引入方式的不断调整和优化,能取得更好的图片描述效果。
本发明通过以下技术方案来实现上述目的:
一种准确率较高的基于属性概率向量引导注意模式的图片描述方法,包括以下步骤:
(1)输入图像通过全卷积神经网络得到特征图谱,再经过多实例学习算法层得到属性概率向量。
(2)得到的属性概率向量选取一定阈值初始化长短时记忆单元lstm隐藏状态c0,h0。
(3)通过属性概率向量对注意模式进行引导,并结合上一时刻描述语句lstm的状态ht-1,在当前时刻注意模式关注特征图谱上的区域,生成当前需要关注的编码向量。
(4)描述语句lstm根据当前编码向量输出当前时刻的输出状态ht。
(5)当前时刻的输出状态即变成上一时刻的状态,重复步骤三、四直到完成描述语言的生成。
附图说明
图1是使用属性概率向量初始化注意模式的示意图
图2是本发明t时刻引导部分原理框图
具体实施方式
下面结合附图对本发明作进一步说明:
图1使用属性概率向量初始化注意模式的示意图,包括以下步骤:
(1)输入图像通过全卷积神经网络得到特征图谱,再经过多实例学习算法层得到属性概率向量。
(2)得到的属性概率向量选取一定阈值初始化lstm隐藏状态c0,h0。具体初始化方法定义如下:
c0=f(wini⊙vatt)
h0=f(wini⊙vatt)
在上式中,wini表示需要在训练中学习的参数,vatt代表属性概率向量,⊙代表对应矩阵相乘。
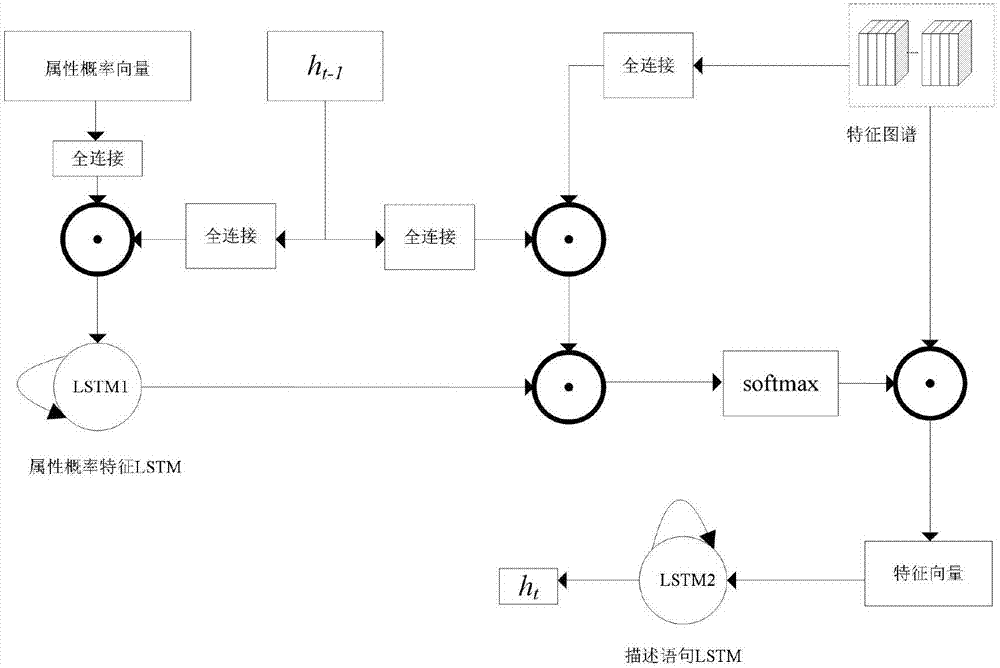
图2是本发明t时刻引导部分原理框图。引导部分由两个关键的lstm构成,它们分别是属性概率特征lstm和描述语句lstm。在时刻t时,首先将上一时刻描述语句lstm的状态与属性概率向量进行结合,并将结合后的值送入到属性概率特征lstm中动态生成权重矩阵,再与特征图谱进行结合,而后生成当前需要关注的编码向量zt,描述语句lstm根据当前编码向量输出当前时刻的输出状态ht。
设属性概率向量为vatt,具体引导方法定义如下:
et=fatt(ht-1,vatt,a)
=lstm(wvvatt⊙wh1ht-1)⊙waa⊙wh2ht-1
zt=∑iαtiai
其中,wv、wh1、wh2和wa均通过训练学习得到,⊙代表对应矩阵进行点乘;αt={αt1,αt2,αt3,...,αtl}为权值,该权值会决定在已产生的词序列之后,产生下一个词时注意力应该重点放在图片哪一部分区域;ai代表特征向量集合,zt代表根据注意模式动态求取的编码向量,其会被送入到lstm中进行解码,解码计算公式如下:
ct=ft⊙ct-1+it⊙gt
ht=ot⊙tanh(ct)。
技术特征:
技术总结
本发明公开了基于属性概率向量引导注意模式的图片描述方法。包括以下步骤:输入图像通过全卷积神经网络得到特征图谱,再经过多实例学习算法层得到属性概率向量,对得到的属性概率向量选取一定阈值初始化长短时记忆单元LSTM隐藏状态c0,h0,通过属性概率向量对注意模式进行引导,并结合上一时刻描述语句LSTM的状态ht‑1,在当前时刻注意模式关注特征图谱上的区域,生成当前需要关注的编码向量,描述语句LSTM根据当前编码向量输出当前时刻的输出状态ht,当前时刻的输出状态即变成上一时刻的状态,重复之前操作直到完成描述语言的生成。本发明所述的基于属性概率向量引导注意模式的图片描述方法比其他方法效果明显提升,评价指标综合表现来说是较好的,基本能够胜任一般的图片描述需要。
技术研发人员:何小海;何榜耕;张杰;苏婕;卿粼波;吴晓红;滕奇志
受保护的技术使用者:四川大学
技术研发日:2017.08.19
技术公布日:2018.01.12
- 还没有人留言评论。精彩留言会获得点赞!