一种基于随机森林算法的恶意文件检测技术的制作方法
本发明涉及数据处理技术领域,尤其涉及一种基于随机森林算法的恶意文件检测技术。
背景技术:
自互联网的普及和发展过程中,具有毁坏系统、篡改文件、影响系统稳定与执行效率、窃取信息等的计算机恶意程序一直是计算机使用中的重要问题。这些恶意程序包括特洛伊木马程序,勒索软件,间谍程序等,它们可能对企业或用户造成极大的危害或是极大的财产损失。因此,使用有效的手段进行精确的恶意文件识别,成为计算机安全防御的一个重点。
目前的检测手段主要采用基于特征码的查杀和启发式的人工特征行为查杀。其中基于特征码的查杀是基于杀毒软件技术的检测,这种方法无法有效识别未知恶意程序,只有当恶意程序的特征码加入病毒库后才能被检测。而启发式的人工特征行为查杀是通过对大量病毒的行为特征进行描述分析,将经典的病毒行为特征串作为检测标准,主要通过经验判,存在较高的漏报率和误报率。
上述基于规则的检测方案只能检测已知的恶意文件类型,但无法更好地对日益更新的恶意文件类型进行识别。而通过行为识别未知的恶意文件就显得尤为重要。
技术实现要素:
本发明通过采集恶意文件与正常文件在沙箱中的文件、网络、注册表、进程等行为信息,构建9大类行为特征,组成特征向量。该特征向量作为机器学习算法的输入数据,选取集成算法随机森林,建立有监督的检测模型。当新的文件行为数据产生,该模型能准确有效的识别出文件恶意与否。
本发明技术方案带来的有益效果:
1、漏报和误报低。通过采集恶意文件在沙箱的动态行为特征,构建机器学习的分类器进行检测,相对基于传统的规则匹配,能有效地减少漏报率和误报率。
2、模型容识别率高。可以通过丰富训练样本库的方式,增强模型的识别能力,使该模型能发现已知和未知种类的恶意文件。
3、消耗系统资源低。模型一旦训练完成,可以直接导出称为文件,当需要检测新样本文件时,只需要导入该模型文件,便可完成检测,极大低减少系统资源的消耗。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
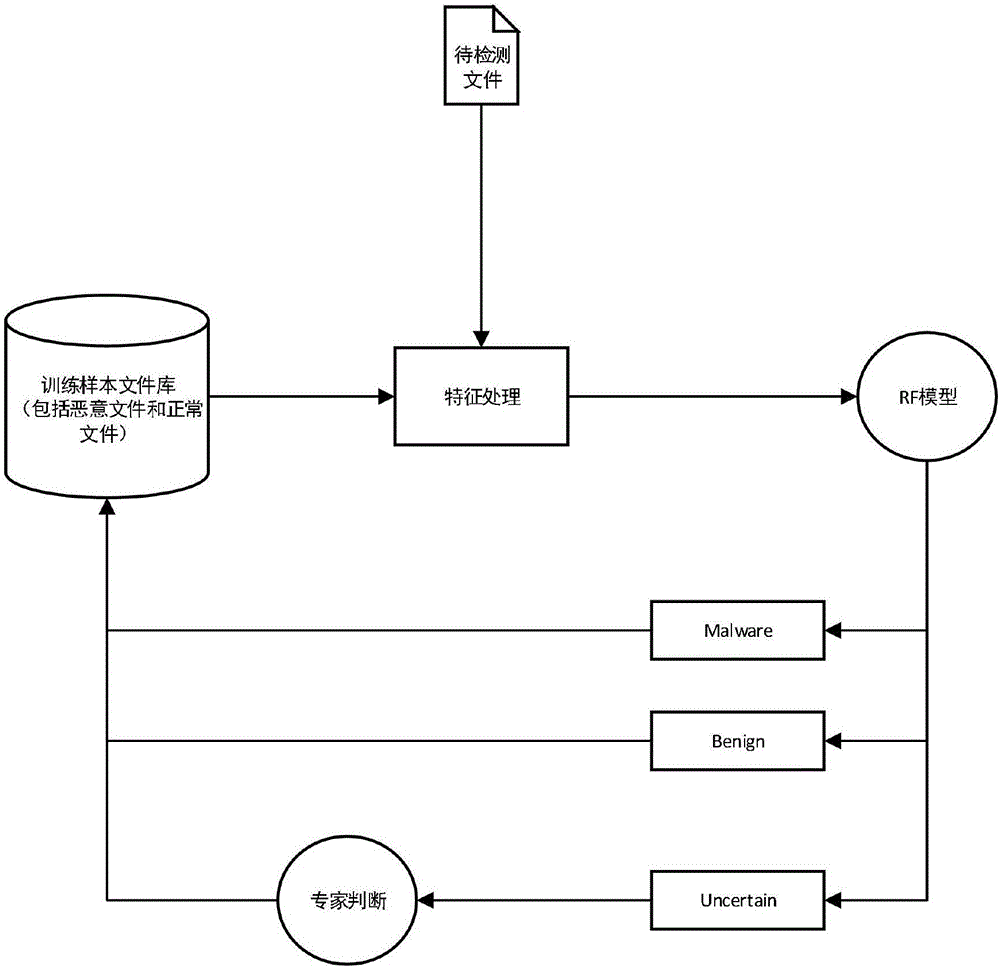
图1是本发明流程图图;
具体实施方式
本发明提供的一种基于随机森林算法的恶意文件检测技术方案如下所述:
步骤1:收集恶意样本和正常样本。分别从开源病毒网站收集公开的恶意、病毒文件和正常无恶意的文件,作为训练样本。
步骤2:搭建安装沙箱模块并收集恶意样本和正常样本在沙箱中产生的所有行为信息。
步骤3:根据window底层api的作用,构造9大类行为特征。
步骤4:将沙箱收集的样本数据,处理为9大行为特征向量,作为训练样本特征向量。
步骤5:使用处理好的训练样本特征向量,输入到随机森林算法,学习一个有监督的分类器。
步骤6:收集待检测未知样本程序文件的沙箱行为数据。
步骤7:计算待检测样本的9大类行为特征,构造待检测特征向量。
步骤8:使用训练好的随机森林模型,检测待检测样本。
步骤9:随机森林输出该样本的检测结果,恶意文件或正常文件。
步骤10:丰富训练样本库,提高模型检测能力。
下面将结合附图,对本发明进行详细说明。所描述的详细案例仅是本发明的一部分,而不是对本发明的限制。
具体实施流程:
步骤1:使用爬虫技术,分别从开源病毒网站收集公开的恶意、病毒文件和正常无恶意的文件,作为训练样本文件。
步骤2:在虚拟环境安装搭建沙箱,并将恶意样本文件和正常样本文件,分别放到沙箱中运行,同时收集各自运行的结果数据。该数据包括动态链接库加载、文件操作、注册表修改、网络连接信息等。
步骤3:根据windowapi函数的功能,构造了9大类行为特征,分别为“文件操作类”、“网络操作类”、“注册表与服务类”、“进程线程类”、“注入类”、“驱动类”、“加密与解密”、“消息传递”、“其他系统关键api”,其中每类特征是由相关api集合组成。
步骤4:在windows操作系统中,基本上所有的功能都是通过调用api来实现的。如果恶意文件不使用api调用而直接进行系统调用,需要编写大量的程序代码,导致更容易被入侵检测系统检测出来。所以一般恶意文件会选择利用api来实现其一系列的功能。而根据api的功能,构造了9大行为特征类,分别为“文件操作类”、“网络操作类”、“注册表与服务类”、“进程线程类”、“注入类”、“驱动类”、“加密与解密”、“消息传递”、“其他系统关键api”,其中每类特征是由相关api集合组成。在9类行为特征中,每一类特征包含多个api,将所有特征包含的api作为特征指标,构造一个160维的特征向量。而样本文件的沙箱行为数据中,包含了其调用api的种类和调用次数。统计其调用在160维特征中对应api的调用次数,构建该样本文件的特征向量。
步骤5:使用处理好的训练样本特征向量,输入到随机森林算法,学习一个有监督的分类器。随机森林使用了bagging的思想,采取有放回地随机抽取样本和特征,生成多棵决策树,统计所有树的决策结果,将结果投票次数最多的类别指定为最终的输出。将训练样本特征向量输入到随机森林的每一颗决策树进行分类,最后统计所有树的结果进行分类,以此训练随机森林。
步骤6:将待检测的未知样本程序文件,放到沙箱运行,收集其在沙箱中产生的行为数据。
步骤7:计算待检测样本的9大类行为特征,构造待检测特征向量。处理方法与步骤4相同,将待检测的样本文件处理成一个160维的特征向量。
步骤8:使用训练好的随机森林模型,检测待检测样本。将处理好的待检测文件的特征向量输入到训练好的随机森林模型中,进行检测。
步骤9:随机森林输出该样本的检测结果,恶意文件或正常文件。该随机森林是由多棵选取不同特征和随机样本的决策树构成的集成算法,通过多棵决策树检测并投票的方式,判断待检测文件是恶意文件或正常文件。
步骤10:丰富训练样本库。将检测出是恶意文件概率大于0.9放到恶意文件训练样本库,概率小于0.1的放到正常文件训练样本库,而概率介于0.1-0.9的由安全专家进行人工检测,检测完毕亦可以用于丰富训练样本库。
以上对本发明实施例所提供的一种基于随机森林算法的恶意文件检查技术进行了详细介绍。本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
技术特征:
技术总结
本发明公开了一种基于随机森林算法的恶意文件检测技术,该方法为了解决现有技术中使用特征匹配方法检测恶意文件的缺点或不足,采用了有效特征提取并使用机器学习算法检测恶意文件的方案,从而实现了准确有效识别已知和未知恶意文件的目的。
技术研发人员:杨育斌;吴智东;柯宗贵
受保护的技术使用者:蓝盾信息安全技术有限公司
技术研发日:2018.03.28
技术公布日:2019.10.15
- 还没有人留言评论。精彩留言会获得点赞!