一种基于影评的电影标签自动生成方法与流程
本发明涉及人工智能领域,更具体的,涉及一种基于影评的电影标签自动生成方法。
背景技术:
电影由于其丰富的元素迅速地成为人们日常生活中必备的休闲方式之一。电影的市场越来越大,电影的种类越来越多。琳琅满目的电影以及电影的时长导致用户不可能完整浏览一部影片,对于即将上映的电影来说,用户了解一部电影的较好方式通常包括简介,预告片,其他用户的片评论以及电影标签,但对于一些年份较古老或者较冷门的电影,用户了解的方式通常只有简介和电影标签。因此,电影的社会标签具有较大的意义,能帮助推荐系统提升为用户推荐的电影的准确性,能帮助提供电影资讯的平台进行电影细粒度分类以及丰富电影检索功能,并能帮助用户迅速的了解电影的主要信息。但是,目前对于未上映的电影或者冷门电影,由于观看的用户数目极少,因此这部分电影的社会标签通常非常少甚至没有,而这部分电影的数量远超于社会标签较为丰富的电影。手工的为这部分电影打标签不仅费时费力,而且难以较全面地覆盖电影的各个方面。
技术实现要素:
为了解决现有技术中对于未上映的电影或者冷门电影这部分电影的社会标签通常非常少甚至没有不足,本发明提供了一种基于影评的电影标签自动生成方法。
为实现以上发明目的,采用的技术方案是:
一种基于影评的电影标签自动生成方法,包括以下步骤:
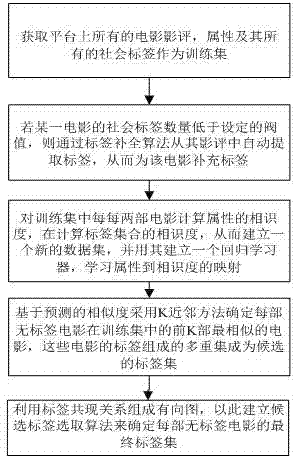
步骤s1:获取平台上所有电影的影评、属性及其对应的社会标签作为训练集;
步骤s2:若某一电影的社会标签数量低于设定的阈值,则通过标签补全算法从其影评中自动提取标签,从而为该电影补充标签;
步骤s3:对训练集中的每每两部电影计算属性的相似度,以及计算每每两部电影社会标签集合的相似度,从而构建一个新的数据集,并用其建立一个回归学习器,学习从属性到相似度的映射;
步骤s4:基于回归学习器预测的相似度采用k近邻方法确定每部无标签电影在训练集中的前k部最相似的电影,这些电影的社会标签组成的多重集成为候选标签集;
步骤s5:利用标签共现关系组成有向图,以此建立候选标签选取算法从候选标签集中确定每部无标签电影的最终标签集。
优选的,步骤s2所述的标签补全算法包括以下步骤:
步骤s201:通过所有电影的所有影评计算每个词汇的逆文档频率,计算每部电影所有影评对应词汇的频率;
步骤s202:通过训练集的所有标签计算每个标签的正向权重;
步骤s203:为训练集中每部标签数量低于设定阈值的电影补充tf-idf乘上正向权重后最大的那些标签,补充到社会标签的数量达到设定的阈值为止。
优选的,步骤s5具体包括以下步骤:
步骤s501:采用候选标签集构建有向带权图g的顶点,其中g的从u到v的边的权重由u,v共现次数及u和其他顶点共现次数给出;
步骤s502:采用候选标签集中每个标签出现的次数给对应的顶点赋值;
步骤s503:不断从图中删除掉顶点值最小的顶点,并且给删掉的顶点前k大权值的边对应的顶点传输按比例分配的数值,直到图的顶点数达到预定义的数值;
步骤s504:取出图中剩下的顶点,其对应的标签组成的集合即是从候选标签集中最终选出的标签集合。
本发明中的算法充分考虑了目前有标签的电影的数据集中存在的缺失问题,首先采用带权重的无监督算法从影评中自动为训练集补足标签。同时,本发明还充分考虑了两部电影各项属性的相似性和标签相似性的关系,以机器学习的方法预测从各项属性到标签相似性的映射,而不是采用简单的相似性如余弦相似性计算粗略的相似性关系。最后,本方法在使用传统k近邻算法得到标签的候选多重集后,并不采用简单的评价标准排序选出标签集,而是采用基于标签共现关系的图算法来决定候选标签的顺序,从而决定最终的标签集。本发明能够根据为电影自动生成一套标签,具有智能,便捷的特点。
附图说明
图1为本发明的步骤流程图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
一种基于影评的电影标签自动生成方法,包括以下步骤:
步骤s1:获取平台上所有电影的影评、属性及其对应的社会标签作为训练集;
步骤s2:若某一电影的社会标签数量低于设定的阈值,则通过标签补全算法从其影评中自动提取标签,从而为该电影补充标签;
步骤s3:对训练集中的每每两部电影计算属性的相似度,以及计算每每两部电影社会标签集合的相似度,从而构建一个新的数据集,并用其建立一个回归学习器,学习从属性到相似度的映射;
步骤s4:基于回归学习器预测的相似度采用k近邻方法确定每部无标签电影在训练集中的前k部最相似的电影,这些电影的社会标签组成的多重集成为候选标签集;
步骤s5:利用标签共现关系组成有向图,以此建立候选标签选取算法从候选标签集中确定每部无标签电影的最终标签集。
优选的,步骤s2所述的标签补全算法包括以下步骤:
步骤s201:通过所有电影的所有影评计算每个词汇的逆文档频率,计算每部电影所有影评对应词汇的频率;
步骤s202:通过训练集的所有标签计算每个标签的正向权重;
步骤s203:为训练集中每部标签数量低于设定阈值的电影补充tf-idf乘上正向权重后最大的那些标签,补充到社会标签的数量达到设定的阈值为止。
优选的,步骤s5具体包括以下步骤:
步骤s501:采用候选标签集构建有向带权图g的顶点,其中g的从u到v的边的权重由u,v共现次数及u和其他顶点共现次数给出;
步骤s502:采用候选标签集中每个标签出现的次数给对应的顶点赋值;
步骤s503:不断从图中删除掉顶点值最小的顶点,并且给删掉的顶点前k大权值的边对应的顶点传输按比例分配的数值,直到图的顶点数达到预定义的数值;
步骤s504:取出图中剩下的顶点,其对应的标签组成的集合即是从候选标签集中最终选出的标签集合。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
技术特征:
技术总结
本发明提出了一种基于影评的电影标签自动生成算法,本发明中的算法充分考虑了目前有标签的电影的数据集中存在的缺失问题,首先采用带权重的无监督算法从影评中自动为训练集补足标签。同时,本发明还充分考虑了两部电影各项属性的相似性和标签相似性的关系,以机器学习的方法预测从各项属性到标签相似性的映射,而不是采用简单的相似性如余弦相似性计算粗略的相似性关系。最后,本方法在使用传统K近邻算法得到标签的候选多重集后,并不采用简单的评价标准排序选出标签集,而是采用基于标签共现关系的图算法来决定候选标签的顺序,从而决定最终的标签集。
技术研发人员:吴迪;吴灿锐
受保护的技术使用者:中山大学
技术研发日:2018.08.13
技术公布日:2019.02.01
- 还没有人留言评论。精彩留言会获得点赞!