一种基于时间序列数据的分类算法的制作方法
本发明涉及分类算法技术领域,具体涉及一种基于时间序列数据的分类算法。
背景技术:
分类算法在互联网中有着广泛的应用。现实生活中我们各种各样的商品、物体需要分类,在互联网世界中分类的应用更是普遍,邮件需要分类(垃圾邮件、正常邮件)、图片需要分类、文本需要分类等等,分类几乎无处不在,同时分类算法也是非常的多,在各个领域都有相关的算法,也有成熟的应用,但在时间序列数据上,传统分类算法应用效果往往不是很好,由于基于时间序列的数据在分类时比较难于准确划分基础项,导致分类结果准确度不高,达不到满意的效果。
技术实现要素:
本发明的目的在于克服现有技术中存在的问题,提供一种基于时间序列数据的分类算法,它可以实现提高分类的准确性。
为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现的:
一种基于时间序列数据的分类算法,其包括如下步骤:
step1,将每个采集点的原始数据按时间进行排序;
step2,确定时间间隔,认为在此时间间隔内的候选项都是一组的,并按设置的时间间隔,两两划分成组;
step3,统计每一项的频数;
step4,统计每一组的频数;
step5,计算每组数据的支持度,计算公式为:c(xy)/avg(c(x),c(y))=组x与组y中的项在一条记录中同时出现的次数/数据的个数;
step6,根据实际情况,排除掉支持度低的候选项;
step7,通过融合最终候选项,得出最终结果。
进一步地,所述step2中的按时间分组,只要在一个时间段内,同一个候选项可以被划分到多个分组里。
进一步地,所述step3中统计出的频数按其大小进行排序并剔除支持度小的项。
本发明的有益效果:通过将最原始的基础项两两划分,先判断这两个基础项是不是一类,然后再根据支持度计数、支持度等排除不相关的数据项,最后再将所有两个基础项的候选项是一类的数据融合,得到整个分类结果,从而提高分类准确性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
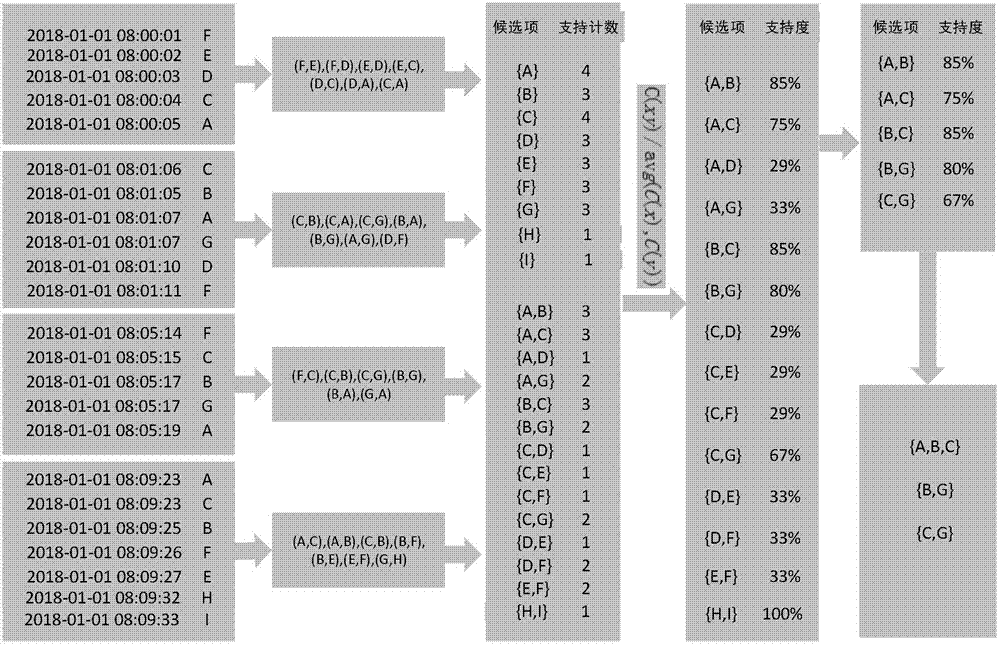
图1为本发明的实施例的原理示意图。
具体实施方式
基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
如图1所示的一种时间序列数据分类算法,其包括如下步骤:
step1:将原始数据根据每个采集点,分别按时间排序。如图四个采集的数据已经按时间排顺序。
step2:确定时间间隔,图中设置的为3秒,在此时间间隔内的候选项都是一组的。并按设置的时间间隔,来两两划分成组(图1中的(f,e),(f,d),(e,d),(e,c),(d,c),(d,a),(c,a))。
step3:统计每一项的频数(支持度计数),并按频数大小排序(这里排序为了方便后面计算,每个采集点一个时间段采集一次算一次,(a,4),(c,3)等支持度计数)。这里设置的小支持度数为2,将没有满足条件的数据丢掉,因为可能出现最({h,i}1),(h,1),(h,1)这种情况,这种情况计算出来的支持度就为100%,但其只是一个偶然的情况,并不能代表真实情况。这里的最小支持度为2,则将{h,i}这个选项剔除。
step4:统计每一组的频数,不限组顺序,(a,b),(b,a)视为一种。(如({a,b}3),({a,c}3))。
step5:计算每组数据的支持度。使用公式c(xy)/avg(c(x),c(y)),计算每组数据的支持度(如({a,b}85%),({a,c}75%))。
step6:排除掉支持度小于50%的候选项。这里就剩下(a,b),(a,c),(b,c),(b,c),(c,g)
step7:通过融合最终候选项,得出最终结果。如(a,b),(a,c),(b,c)都在候选项里。则可以得出(a,b,c),(c,g)
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
技术特征:
技术总结
本发明涉及分类算法技术领域,具体涉及一种基于时间序列数据的分类算法,包括如下步骤:将每个采集点的原始数据按时间进行排序、确定时间间隔,认为在此时间间隔内的候选项都是一组的,并按设置的时间间隔,两两划分成组、统计每一项的频数、统计每一组的频数、计算每组数据的支持度,排除掉支持度低的候选项、通过融合最终候选项,得出最终结果。本发明的有益效果:通过将最原始的基础项两两划分,先判断这两个基础项是不是一类,然后再根据支持度计数、支持度等排除不相关的数据项,最后再将所有两个基础项的候选项是一类的数据融合,得到整个分类结果,从而提高分类准确性。
技术研发人员:孟彦;韦建;章文友;朱静轩
受保护的技术使用者:中新网络信息安全股份有限公司
技术研发日:2018.09.03
技术公布日:2019.02.01
- 还没有人留言评论。精彩留言会获得点赞!