一种基于词向量的检测词义随时间变化的方法与流程
本发明涉及自然语言处理的技术领域,更具体地,涉及一种基于词向量的检测词义随时间变化的方法。
背景技术:
词义随时间的变化是理解语言与文化发展的关键因素之一。但是历史资料并没有对语义的变化有很好的统计。词向量是解决这个问题的一个好工具。
词向量是词的向量表示,向量的一些几何性质能够很好的反映词的句法或者句义。现阶段应用最广的词向量训练技术就是word2vector。word2vector的基本思路是:一个词的词义是由它的上下文决定的。它的实现方法有cbow模型和skip-gram模型,cbow模型是根据输入周围n-1个词来预测出中心词。而skip-gram模型的输入是中心词的词向量,输出是中心词周围的词的词向量。
word2vector可以很好地体现词的静态词义,在很多自然语言处理的任务中应用广泛,但是它只是体现了词的静态词义,没有考虑到词的动态词义,即词随时间变化词义是动态变化的。
上述技术在训练词向量的时候,都是把收集的语料一次性拿去训练词向量,得到的是词的静态词义。而并没有考虑到词的动态词义,即没有体现出词义随时间的变化情况。之所以有这样的缺点,是上述技术没有考虑到时间因素对词义的影响。
技术实现要素:
本发明为克服上述现有技术所述的至少一种缺陷,提供一种基于词向量的检测词义随时间变化的方法,使用深度学习的方法,利用不同时间阶段的语料来训练词向量,最后利用训练好的词向量来检测词义随时间的变化情况。
本发明的技术方案是:一种基于词向量的检测词义随时间变化的方法,其中,包括以下步骤:
s1:将数据集按照每十年的间隔时间分开;
s2:在每个数据集中,初始的词向量除了第一个时间段是随机产生的外,其它时间的词向量都是以上一个时间段的词向量作为初始词向量;
s3:对于数据集中的每一行,以窗口大小为n,将窗口内的词与窗口的中心词组成pair;所以一个窗口总共有n-1对pair;
s4:对于其中的每对pair,先索引到它们各自的词向量,然后将中心词的词向量作为输入;另个词是当成label;
s5:搭建全连接神经网络,将中心词的词向量作为输入;
s6:利用交叉熵函数计算loss;
s7:重复s2到s6,直到loss收敛,不再下降;
s8:对于下一个时间段的训练,将词向量初始化为上一个时间段已经训练好的词向量,然后重复s2到s7;
s9:所有时间段的词向量都训练完成之后,通过计算同一个词在不同的时间段的词向量的余弦相似度,就可以判断这个词在不同时代的词义是否发生了变化。
进一步的,所述的步骤s1中,按照时间顺序来训练词向量。
进一步的,所述的步骤s5中,神经网络经过softmax层之后输出是一个向量,这个向量的长度是词库中的词的数目,其中每个元素代表该词作为输出的概率。
进一步的,所述的步骤s6中,引入negativesampling,即只采样少数负例的样本来和正例一起计算loss;采样的规则是根据词在数据集中的词频来确定被采样到的概率;词频越高,选中的概率就越高。
与现有技术相比,有益效果是:本发明在普通词向量的基础上考虑上了时间维度,相比普通的词向量,丰富了词向量在不同时间上的语义表示。有助于自然语言处理更高层次上的应用。而不像现有方法,将所有数据都认为是在同一个时间段内,忽视了时间对词义的影响。
另一方面,通过对比词在不同时代的词向量的变化,可以观察到词随时代变迁的词义变化情况,有助于语言学家,历史学家的考察。
附图说明
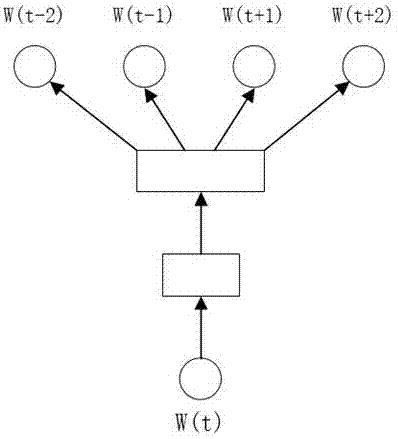
图1是本发明整体示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。附图中描述位置关系仅用于示例性说明,不能理解为对本专利的限制。
如图1所示,
s1:将数据集按照每十年的间隔时间分开。并且按照时间顺序来训练词向量。
s2:在每个数据集中,初始的词向量除了第一个时间段是随机产生的外,其它时间的词向量都是以上一个时间段的词向量作为初始词向量。
s3:对于数据集中的每一行,以窗口大小为n(n一般是奇数),将窗口内的词与窗口的中心词(即n/2位置的词)组成pair。所以一个窗口总共有n-1对pair。
s4:对于其中的每对pair,先索引到它们各自的词向量,然后将中心词的词向量作为输入。另个词是当成label。
s5:搭建全连接神经网络,将中心词的词向量作为输入。神经网络经过softmax层之后输出是一个向量,这个向量的长度是词库中的词的数目,其中每个元素代表该词作为输出的概率。
s6:利用交叉熵函数计算loss。
针对s6,由于词库的数量很大,所以输出向量的维度很大,这对loss的计算复杂度影响很大,而且由于正例的样本只有一个,负例的样本很多,所以导致在计算梯度时,误差比较大。为了解决这个问题,引入negativesampling,即只采样少数负例的样本来和正例一起计算loss。采样的规则是根据词在数据集中的词频来确定被采样到的概率。词频越高,选中的概率就越高。
s7:重复s2到s6,直到loss收敛,不再下降。
s8:对于下一个时间段的训练,将词向量初始化为上一个时间段已经训练好的词向量,然后重复s2到s7。
s9:所有时间段的词向量都训练完成之后,通过计算同一个词在不同的时间段的词向量的余弦相似度,就可以判断这个词在不同时代的词义是否发生了变化。
本发明引入时间维度,考虑时间对词的词义的影响,从而得到词的动态词义,进而可以根据词的动态词义检测出词义随时间的变化,有助于人们了解语言和文化的发展情况,也可以应用在其它涉及到时间序列的场景中。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
技术特征:
技术总结
本发明涉及自然语言处理的技术领域,更具体地,涉及一种基于词向量的检测词义随时间变化的方法。本发明在普通词向量的基础上考虑上了时间维度,相比普通的词向量,丰富了词向量在不同时间上的语义表示。有助于自然语言处理更高层次上的应用。而不像现有方法,将所有数据都认为是在同一个时间段内,忽视了时间对词义的影响。另一方面,通过对比词在不同时代的词向量的变化,可以观察到词随时代变迁的词义变化情况,有助于语言学家,历史学家的考察。
技术研发人员:李伟彬;潘嵘
受保护的技术使用者:中山大学
技术研发日:2018.09.18
技术公布日:2019.02.05
- 还没有人留言评论。精彩留言会获得点赞!