一种基于聚合模型的海量数据质量报告生成方法与流程
本发明涉及数据治理领域,特别是一种基于聚合模型的海量数据质量报告生成方法。
背景技术:
随着信息技术的发展,数据逐渐成为企业价值最重要的资源,而随之而来的数据质量问题也越来越严重,数据的错误、缺失、不一致等数据质量问题是企业必须面对的问题,正确有效的数据是数据存储和分析的前提。
随着互联网技术和各种存储技术的发展,企业存储的数据规模在不断的增长,对海量大规模数据的校验,成为企业数据治理不可避免的问题。
现有技术方案中已经存在一些对数据质量进行校验并生成数据质量报告的管理方法,但是这些技术方案大部分都存在无法灵活配置校验规则,无法支持海量数据进行校验的缺点。
专利申请公布号【cn108595563a】无法支持基于离线计算的聚合模型,只能针对常规规模的数据进行数据质量校验分析。
专利申请公布号【cn107818106a】没有定义一种通用模型和可配置的校验规则,只是针对数据一致性进行校验,不能形成完整的海量数据的数据质量校验方案。
技术实现要素:
有鉴于此,本发明的目的是提出一种基于聚合模型的海量数据质量报告生成方法,既能支持通用校验规则的定制,又能支持海量大规模数据进行离线数据校验。
本发明采用以下方案实现:一种基于聚合模型的海量数据质量报告生成方法,包括以下步骤:
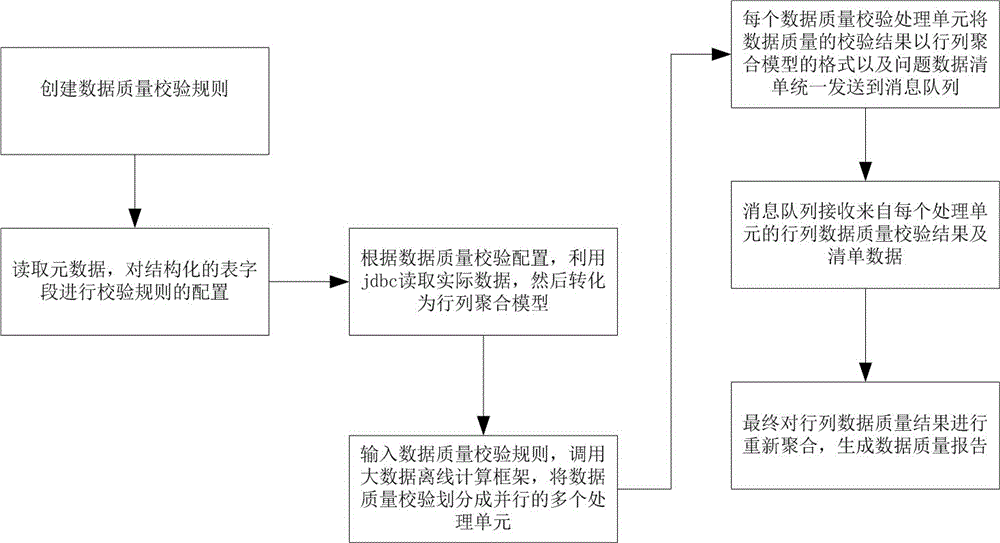
步骤s1:创建数据质量校验规则,并读取元数据,对结构化的表字段进行校验规则的配置;
步骤s2:根据配置好的校验规则,利用jdbc读取实际数据,然后将实际数据转化为行聚合模型与列聚合模型;
步骤s3:输入数据质量校验规则,调用大数据离线计算框架,将数据质量校验划分成并行的多个数据质量校验处理单元;
步骤s4:每个数据质量校验处理单元将数据质量的校验结果以及问题数据清单统一发送到消息队列;其中所述校验结果以行聚合模型、列聚合模型的格式发送至消息队列;
步骤s5:消息队列对接收到的行、列数据质量校验结果进行重新聚合,生成数据质量报告。
进一步地,所述行聚合模型定义了物理映射的表名、校验聚合维度、校验数量、以及校验问题数量。
进一步地,所述列聚合模型定义了物理映射的表名、字段名、校验的规则名、校验聚合维度、校验数量、以及校验问题数量。
进一步地,数据质量校验规则定义了输入单元、输出单元、校验规则名、校验参数、校验值域、以及校验表达式。
本发明通过定义的行聚合模型、列聚合模型等将物理的实际数据先转化为行列聚合模型,所谓的聚合模型就是原来整体的数据,根据聚合特性可以拆分和合并,这样就能支持离线计算,支持多个校验处理单元并行校验;另外生成大规模数据质量报告的结果数据也不是一个整体,而是来自多个数据质量校验的处理单元输出的数据质量报告结果,通过消息队列统一消化和聚合,最终生成针对大规模结构化数据进行的可自定义校验规则的数据质量校验分析报告。
与现有技术相比,本发明有以下有益效果:本发明提供的方法既能支持海量的大规模结构化数据的数据质量的校验,让这些数据质量校验的处理过程支持大数据离线计算框架,可以同时运行在多台服务器上进行数据质量校验计算;又可以支持一种通用的数据质量的校验规则,可以自定义配置校验规则,满足多维度灵活的定制校验策略,生成数据质量报告。
附图说明
图1为本发明实施例的方法流程示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本技术提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本实施例提供了一种基于聚合模型的海量数据质量报告生成方法,包括以下步骤:
步骤s1:创建数据质量校验规则,并读取元数据,对结构化的表字段进行校验规则的配置;
步骤s2:根据配置好的校验规则,利用jdbc读取实际数据,然后将实际数据转化为行聚合模型与列聚合模型;
步骤s3:输入数据质量校验规则,调用大数据离线计算框架,将数据质量校验划分成并行的多个数据质量校验处理单元;
步骤s4:每个数据质量校验处理单元将数据质量的校验结果以及问题数据清单统一发送到消息队列;其中所述校验结果以行聚合模型、列聚合模型的格式发送至消息队列;
步骤s5:消息队列对接收到的行、列数据质量校验结果进行重新聚合,生成数据质量报告。
在本实施例中,所述行聚合模型定义了物理映射的表名、校验聚合维度、校验数量、以及校验问题数量。
在本实施例中,所述列聚合模型定义了物理映射的表名、字段名、校验的规则名、校验聚合维度、校验数量、以及校验问题数量。
在本实施例中,数据质量校验规则定义了输入单元、输出单元、校验规则名、校验参数、校验值域、以及校验表达式。
本实施例通过定义的行聚合模型、列聚合模型等将物理的实际数据先转化为行列聚合模型,所谓的聚合模型就是原来整体的数据,根据聚合特性可以拆分和合并,这样就能支持离线计算,支持多个校验处理单元并行校验;另外生成大规模数据质量报告的结果数据也不是一个整体,而是来自多个数据质量校验的处理单元输出的数据质量报告结果,通过消息队列统一消化和聚合,最终生成针对大规模结构化数据进行的可自定义校验规则的数据质量校验分析报告。
特别的,在本实施例中,大数据离线计算,是以hadoop大数据技术为代表,进行大批量离线数据计算处理,以聚合编程模型为典型的计算方式,对数据进行聚合并行计算。hadoopmapreduce的聚合模型,它适用于大规模数据集的并行运算。其基本思想是将问题分解成map(映射)和reduce(化简),map程序将数据分割独立区块,利用计算机群实现分布式处理,最后通过reduce程序将结果汇总整合输出。mapreduce的作业流程是任务的分解与集合的汇总。sparkrdd的聚合模型,spark的弹性分布式数据集,是spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
技术特征:
技术总结
本发明涉及一种基于聚合模型的海量数据质量报告生成方法,通过定义的行聚合模型、列聚合模型等将物理的实际数据先转化为行列聚合模型,所谓的聚合模型就是原来整体的数据,根据聚合特性可以拆分和合并,这样就能支持离线计算,支持多个校验处理单元并行校验;另外生成大规模数据质量报告的结果数据也不是一个整体,而是来自多个数据质量校验的处理单元输出的数据质量报告结果,通过消息队列统一消化和聚合,最终生成针对大规模结构化数据进行的可自定义校验规则的数据质量校验分析报告。本发明既能支持通用校验规则的定制,又能支持海量大规模数据进行离线数据校验。
技术研发人员:肖俊鑫
受保护的技术使用者:福建南威软件有限公司
技术研发日:2018.12.25
技术公布日:2019.04.23
- 还没有人留言评论。精彩留言会获得点赞!