一种基于Storm的工业信令数据流式计算框架的制作方法
本发明涉及大数据存储、数据搜索、数据挖掘、流数据处理领域,具体涉及到一种基于storm的工业信令数据流式计算框架。
背景技术:
工业4.0时代发展要求下,工业大数据主要分为机器数据、外部第三方数据和企业经营相关业务数据。基于工业行业特性,生产过程中收集到的大规模时序数据显现出规模大、类型杂、质量低的三大难点,同时对工业数据的收集也会带来影响。
流数据挖掘的特点决定了它比传统的数据挖掘要复杂,因为流数据是不停产生的,而内存的大小是有限的,无法把收集到的数据都放在内存中等待挖掘,而只能实时的进行处理。所以在设计挖掘算法时要注意怎样才能将有限的内存充分利用,使得一次能处理更多的数据。又由于储存在内存中的数据都是最新产生的数据,我们必须在这些数据还没被后来的数据替代前,对它进行处理。考虑到当前工业数据增长迅速、处理复杂的难点,为了从以流形式存在的工业信令数据中挖掘有价值的信息,利用storm对实时数据流进行挖掘。
技术实现要素:
为解决现有技术中的缺点和不足,本发明提出了一中基于storm的工业信令数据流式计算框架,解决对工业信令数据的流式处理。
本发明的技术方案为:
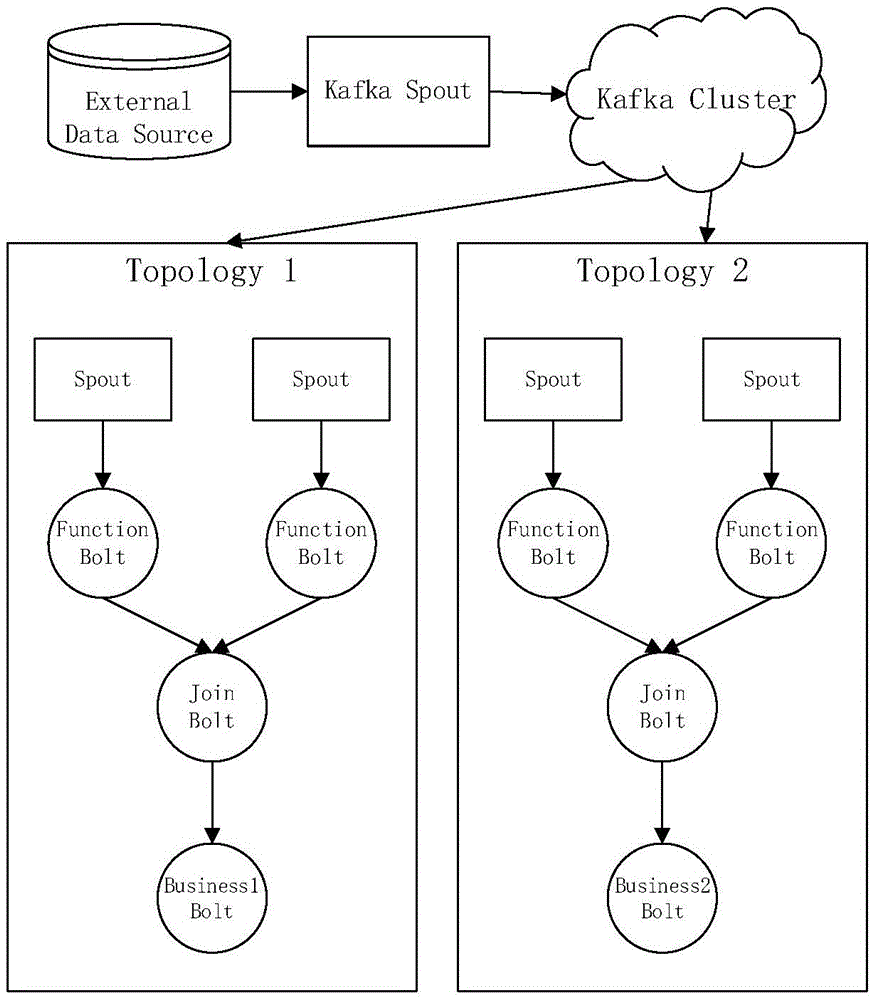
工业信令数据通过ftp定期将数据推动到kafka消息队列中用于缓存信令详单数据,完成数据的缓存、传输等操作;在kafka中划分出不同的partation,建立针对工业信令数据的存储规则,根据已建立的工业数据信令存储规则,实现不同topology的spout共享数据源,保证消息的可靠传输、回传;然后由storm客户端根据业务需求从kafka中取相应的工业信令数据,根据具体的业务设计相应的流处理模型,完成任务所需环境下的数据挖掘系列操作过程。
本发明的有益效果:
(1)解决当前工业信令数据流式处理复杂问题,提高对工业信令数据的手机、缓存、传输效率,保证服务消息的可靠传输、回传操作。
(2)提高工业信令数据的规则化程度,解决工业大数据的杂、乱、质量低的问题,提高数据挖掘所用数据集质量。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明系统逻辑框架图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明基于storm的工业信令数据流式计算框架如图1所示,包括信令预处理、数据采集。
步骤(1)、工业信令数据通过ftp定期将数据推动到kafka消息队列中用于缓存信令详单数据,完成数据的缓存、传输等操作;
步骤(2)、在kafka中划分出不同的partation,建立针对工业信令数据的存储规则,解决规模大、类型杂的数据特点;
步骤(3)、根据已建立的工业数据信令存储规则,实现不同topology的spout共享数据源,保证消息的可靠传输、回传等操作;
步骤(4)、然后由storm客户端根据业务需求从kafka中取相应的工业信令数据,根据具体的业务设计相应的流处理模型,完成任务所需环境下的数据挖掘系列操作过程。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
技术特征:
技术总结
本发明提出一种基于Storm的工业信令数据流式计算框架。由于当前工业大数据规模大、类型杂、质量低的难点以及挖掘流数据时的复杂方式,设计一种在执行数据挖掘算法时合理利用有限内存,从而一次性获得更多数据的框架。为了从以流形式存在的工业信令数据中挖掘有价值的信息,利用Storm对实时数据流进行挖掘。针对不同的实时数据挖掘任务,可能会用到同一类数据源,本发明中通过Kafka消息中间件,实现不同Topology的Spout共享数据源,保证消息可靠传输、消息回传等。该发明的基于Storm的工业信令数据流式计算框架,能有效提升工业信令数据挖掘过程中信息提取的有效性、高效性,改变工业大数据类型杂、质量低的现状,满足智能工业生产发展需求。
技术研发人员:任鹏程;张卫山;房凯
受保护的技术使用者:中国石油大学(华东)
技术研发日:2019.01.28
技术公布日:2019.06.18
- 还没有人留言评论。精彩留言会获得点赞!