语言模型预训练方法与流程
本发明属于人工技术领域,尤其是涉及一种基于混合字符及子词的改进bert模型的语言模型预训练方法。
背景技术:
自然语言处理是人工智能领域的一个重要分支。预训练语言模型在实践中被证明具有相当突出的有效性。语言模型(languagemodel)是一串词序列的概率分布。具体来说,语言模型是为一个长度为m的文本确定一个概率分布p,表示这段文本存在的可能性。较为常用的语言预训练方法是基于brrt模型的语言预训练,其包括如下步骤:1、准备带有上下句的文本语料;2、使用bpe(bytepieceencoding、即简单分词算法)将文本语料转化为整数序列的分词;3、掩盖/替换15%的分词;4、对被掩盖的分词进行预测,并同时预测该分词的上下句。这种预训练方法存在以下问题:1、其直接预测每个位置该出现的词,由于词表巨大导致各位置均出现高频词导致样本的不均衡;2、其基于分词后的序列建模,对于中文这种分词有歧义的语言不友好,且阻碍了中文在下游应用的迁移;3、建模句子对的关系中,上下句的负例构造具有随意性,对最后的训练效果造成随机性影响。因此,如何针对上述问题,对bert模型进行改进,实现一种新型的语言模型预训练方法,是本领域技术人员需要研究的方向。
技术实现要素:
为克服现有brrt模型语言预训练存在的问题,本发明提供了一种语言模型预训练方法。
其采用的技术方案如下:
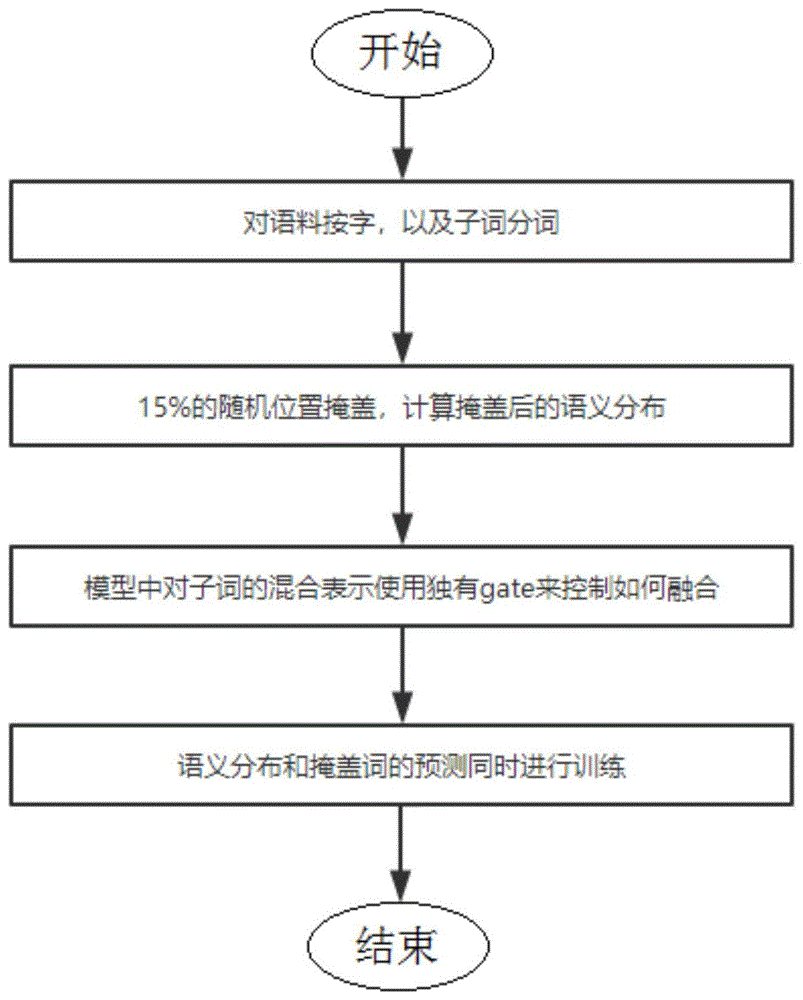
一种语言模型预训练方法,其包括如下步骤:s1:对模型中的语料按字、子词进行分词;s2:对s1生成的各分词随即抽取15%进行位置掩盖、并计算掩盖后的语义分布;s3:以独立的门控制单元对模型中的子词混合进行控制;s4:对语义分布和掩盖词的预测进行同步训练。
优选的是,上述语言模型预训练方法中:所述步骤s2包括如下步骤:s21:初始化空的映射表;s22:从分词表当前位置反向扫描,直至由扫描位置处至当前位置为止构成的字符串出现在词表中;s23:找出该字符串对应的id标号,对映射表中该id出现的频次增加1;s24:对映射表中的各个id标号按出现频次由高到低排序,截取排序后的前k个id标号并分别记录这些id标号的频次;s25:将s24所得k个id的频次分别除以频次和,得到所述k个id的估计概率;s26:以s25所得k个id以及该k个id的频次作为整个词表被掩盖的语义分布。
更优选的是,上述语言模型预训练方法中:所述步骤s3包括如下步骤:s31:对第i个位置的第j种分词结果的词进行嵌入,得到嵌入表示wi,j;s32:根据位置编码机制,并对这个位置得到一个位置嵌入pi,所述pi为第i个位置所用的位置编码向量,一般用最长512个位置,且各个位置都由一个向量表示以建模词的位置关系;所述pi的维度等于所述wi,j的维度k;s33:基于ai,j=θ*[wi,j,pi]+b的运算逻辑获得wi,j和pi的兼容度,所述ai,j为嵌入位置;s34:以s33所得兼容度为权重,对wi,j和pi拼接出来的向量加权求和,得到融合后的表示。
通过采用上述技术方案:在步骤s1生成字符级别的分词作为mlm部分的预测目标,缩小了预测目标的范围,使得模型训练更稳定并减少了计算量。对bert中的输入序列,使用子词和字符混合的方式,同时设置独立门控制单元来混合多种表示,把被掩盖位置的字和词作为一个整体语义分布、统一预测该分布;针对整个篇章而不是句子级别建模,对下游分类任务更为友好以下对本文提出的方法详细描述。
与现有技术相比,本技术能够明显改善bert预训练后模型的预测结果,进一步提高其预测准确率。
附图说明
下面结合附图与具体实施方式对本发明作进一步详细的说明:
图1为实施例1的流程示意图。
具体实施方式
为了更清楚地说明本发明的技术方案,下面将结合各个实施例作进一步描述。
实施例1:
以公司内部职位分类数据为语料,目标是对每段工作经历,预测这段内容对应的职位分类。在本例中,职位分类共有1930类。网络结构采用bert模型中的transformer作为基础,输入一段工作经历,经过transformer后,输出的特征表示使用attention机制,输出对1930类的预测。训练目标使用交叉熵优化,transformer中的参数使用预训练好的bert模型中的参数值。分别采用直接预测、基于bert预训练后预测和在本发明提出的方法进行预训练后预测,三组实验进行预测结果的比对。
其中,采用本技术提出的方法进行的预训练过程如下:
s1:对模型中的语料按字、子词进行分词;
s2:对s1生成的各分词随即抽取15%进行位置掩盖、并计算掩盖后的语义分布;
s3:以独立的门控制单元对模型中的子词混合进行控制;
s4:对语义分布和掩盖词的预测进行同步训练。
三组实验的结果如下:
(1)不采用预训练模型进行直接预测,其预测准确率为50%。
(2)基于bert预训练后的模型进行预测,其预测准确为52%。
(3)基于本发明提出的方法进行预训练后的模型进行预测,其预测准确率为54%。
由此可知,本发明提出的方法对预训练的结果起到了明显的改进作用。
以上所述,仅为本发明的具体实施例,但本发明的保护范围并不局限于此,任何熟悉本领域技术的技术人员在本发明公开的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。本发明的保护范围以权利要求书的保护范围为准。
技术特征:
技术总结
本发明公开了一种语言模型预训练方法,其包括如下步骤:对模型中的语料按字、子词进行分词;对生成的各分词随即抽取15%进行位置掩盖、并计算掩盖后的语义分布;以独立的门控制单元对模型中的子词混合进行控制;对语义分布和掩盖词的预测进行同步训练。本发明能够明显改善BERT预训练后模型的预测结果。
技术研发人员:陈瑶文
受保护的技术使用者:人立方智能科技有限公司
技术研发日:2019.04.03
技术公布日:2019.07.19
- 还没有人留言评论。精彩留言会获得点赞!