基于神经网络的可见光与红外人脸图像的融合方法与流程
本发明涉及图像处理技术领域,特别是涉及一种基于神经网络的可见光与红外人脸图像的融合方法。
背景技术:
人脸识别多年来一直是快速发展的研究领域,是当前模式识别和计算机视觉领域的研究热点。面部识别通过将面部与存储在数据库中的面部图像进行比较来识别或验证身份。由于可见光谱中的面部识别受到照明,姿势,面部表情,视点和伪装的变化的影响。热红外(ir)成像对于照明变化更加稳健因为它捕获来自物体的发射能量以产生图像。因此,在不同的照明条件下,使用热红外图像相对于用于面部识别的可见图像具有显著的优点。然而,红外线对玻璃的透射性较差,眼镜、车窗等玻璃物体,会对红外图像产生较大影响。热红外图像对身体和环境温度的变化也存在敏感性。
技术实现要素:
本发明的目的是针对现有技术中存在的技术缺陷,而提供一种基于神经网络的可见光与红外人脸图像的融合方法。
为实现本发明的目的所采用的技术方案是:
一种基于神经网络的可见光与红外人脸图像的融合方法,包括步骤:
提取人脸红外图像和可见光图像的ltp特征值,分别形成ltp特征矩阵;
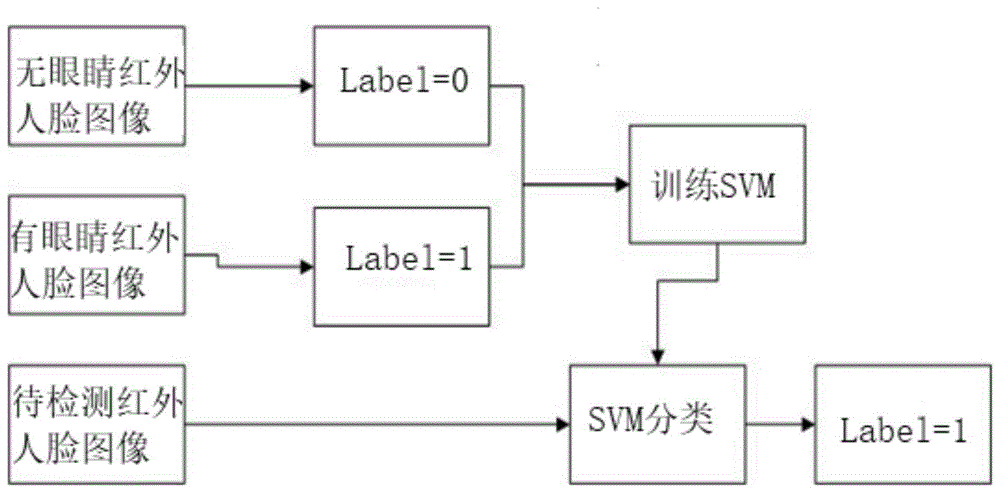
用训练好的svm分类器检测出带眼镜的人脸红外图像并将眼部特征去除,形成除去眼镜部分特征的人脸红外图像的ltp特征矩阵;
将除去眼镜部分特征的人脸红外图像的ltp特征矩阵和可见光图像的ltp特征矩阵输入训练好的resnet50神经网络进行图像融合,得到融合后的图像。
所述提取人脸红外图像和可见光图像的ltp特征值是将原始人脸图像分为若干块区域,对分块后的图像进行ltp算法计算而获得的。
所述svm分类器是由有眼镜的人脸红外图像与无眼镜的人脸红外图像进行训练而得到的。
与现有技术相比,本发明的有益效果是:
本发明使用resnet50神经网络模型对图像进行融合,若红外图像中检测到眼镜,图像融合时去除眼部特征,避免了红外图像对玻璃物体的敏感性带来的影响。
附图说明
图1所示为支持向量机分类器检测模型的示意图;
图2所示为resnet神经网络残差块示意图;
图3所示为基于可见光图像与红外图像的人脸图像融合流程图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明首先对获得的红外人脸图像进行处理,使用ltp算法来提取红外图像的特征,对于眼镜类面部遮挡,使用支持向量机分类器检测眼镜。对于可见光图像,利用ltp算法提取图像特征。
如图1-3所示,本发明基于可见光图像与红外图像的人脸图像融合方法,包括步骤:
(1)提取人脸红外图像和可见光图像的ltp特征值矩阵
首先将原始人脸图像分为s0,s1,s2,…,sm-1共m块区域,对分块后的图像进行ltp算法的计算。ltp算法公式如下。
r和p分别表示半径圆上的中心像素的灰度值和相邻像素的灰度值,r是半径,p是相邻像素的数量。ic代表第c个像素点,该ltp算法首先对每个像素ic的八个邻域进行采样,每个采样点为ip(p=0,1,…,7),t为算法阈值。
(2)使用支持向量机分类器检测眼镜
svm是一种广泛用于模式识别的监督学习方法。如果该人戴着眼镜,则在脸上施加阈值以分割眼镜。考虑到眼镜和皮肤之间的显着温差,这种分割大大简化。将每个热红外(ir)面标准化为32×32像素,并将其进一步转换为长特征向量。使用这些特征向量来训练svm分类器,该svm分类器将面部图像分成两类,具有眼镜的和没有眼镜的,识别出有眼镜的红外图像,被分类为有眼镜的红外图像去除眼部的特征,以避免红外图像对玻璃物体的敏感性带来的影响。
通过使用svm支持向量机分类器检测眼镜,在检测到眼镜的情况下对图像的眼部进行处理,避免了透射性的玻璃对红外图像的影响。
(3)将两个图像特征矩阵输入神经网络进行图像融合
利用训练集对resnet神经网络进行训练。将除去眼镜部分特征的红外人脸图像的特征矩阵和可见光图像的特征矩阵输入训练好的resnet50神经网络来进行图像融合,得到融合后的图像。
resnet神经网络利用残差块的结构,一定程度上解决了梯度消失和梯度爆炸等现象。
本发明中,resnet神经网络是2015年由微软研究院的四名华人提出的神经网络结构。resnet神经网络提出残差学习的思想,主要思想是在网络中增加了直连通道从而允许原始输入信息直接传到后面的层中。传统的卷积网络或者全连接网络在信息传递的时候或多或少会存在信息丢失,损耗等问题,同时还有导致梯度消失或者梯度爆炸,导致很深的网络无法训练。resnet在一定程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度。
测试时,使用casianir-vis2.0数据库共包含725个科目。每个受试者有1-22个可见光图像和5-50个近红外脸部图像,适合作为此次人脸图像融合方法的训练集和测试集。resnet神经网络选择resnet50的结构,利用谷歌开源的tensorflow来搭建。卷积神经网络采用mini-batch方法进行训练可得到较好的结果。
本发明考虑了可见光和热红外图像中包含的特征信息,两者的融合可用于提高人脸识别的准确性,因此提出了本发明的方法。
本发明利用resnet神经网络来对红外人脸图像和可见光人脸图像进行融合,使融合后的图像既具有红外图像对光照的鲁棒性,同时减小了红外图像受到温度和眼镜等遮挡物的影响。将融合后的图像应用于人脸识别,可以得到很好的识别准确率。
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
技术特征:
技术总结
本发明公开一种基于神经网络的可见光与红外人脸图像的融合方法,包括:提取人脸红外图像和可见光图像的LTP特征值,分别形成LTP特征矩阵;用训练好的SVM分类器检测出带眼镜的人脸红外图像并将眼部特征去除,形成除去眼镜部分特征的人脸红外图像的LTP特征矩阵;将除去眼镜部分特征的人脸红外图像的LTP特征矩阵和可见光图像的LTP特征矩阵输入训练好的ResNet50神经网络进行图像融合,得到融合后的图像。本发明采用可见光人脸图像和红外人脸图像共同提取特征信息,通过ResNet神经网络来进行人脸图像融合,避免红外图像对玻璃物体的敏感性带来的影响。
技术研发人员:高静;于子涵;徐江涛;聂凯明;史再峰
受保护的技术使用者:天津大学
技术研发日:2019.04.12
技术公布日:2019.08.09
- 还没有人留言评论。精彩留言会获得点赞!