用于加速BERT神经网络运算的深度学习加速器的制作方法
本发明属于集成电路技术领域,具体涉及一种用于加速bert神经网络运算的深度学习加速器。
背景技术:
随着bert神经网络的发展,其被广泛应用于自动问答、文本翻译、文本分类、语音识别等自然语言处理任务上。bert神经网络包括分支结构的多头注意力(multi-headattention)神经网络部分与端到端的前馈预测神经网络部分。前者用于提取上下文之间的关联特征,后者根据提取到的特征对下一时刻语音或文本输出进行预测。
当前的计算平台cpu/gpu或传统定制设计的神经网络加速器,只能加速处理端到端的神经网络。对于分支结构的神经网络,其只能依次计算出各分支的输出特征值后,再对其进行后处理得到分支网络结构最终的输出特征值。各分支的输出特征值在不参与后处理时必须暂存在特定的存储空间中,浪费了存储单元。
技术实现要素:
本发明的目的在于提供一种能够减少特征值存储空间、降低计算时间和功耗的用于加速bert神经网络运算的深度学习加速器。
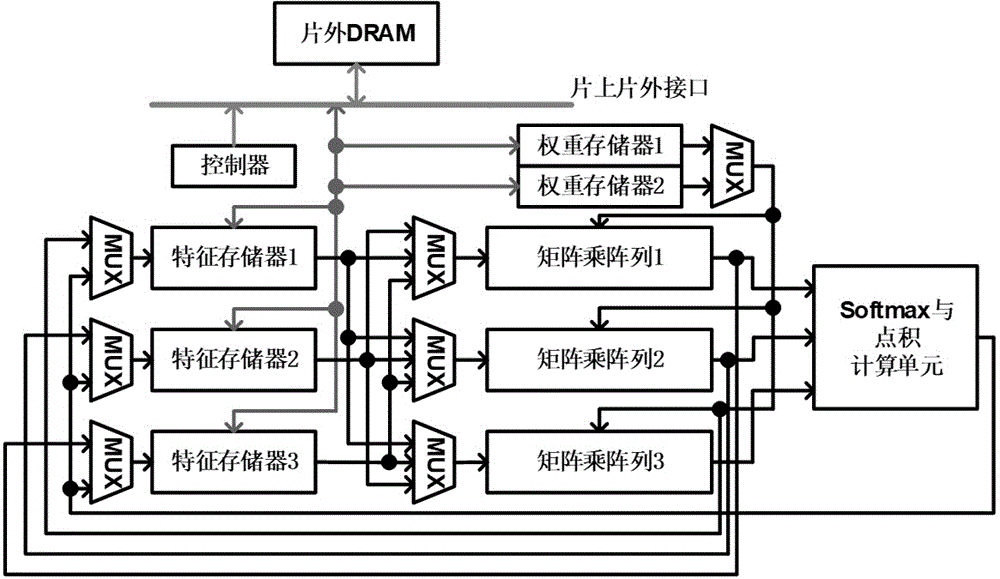
本发明提供的用于加速bert神经网络运算的深度学习加速器,包括:
三个矩阵乘阵列,用于计算神经网络中的乘累加操作;
一个softmax与点积计算单元,用于计算神经网络的softmax概率函数,并对分支网络的输出进行点乘,得到最终的输出特征值;
三个特征存储器,用于存储输入、输出特征值;
两个权重存储器;用于存储网络的权重;
一个控制器和片上片外接口,用于控制片外dram中的数据与片上数据进行交互。
所述特征存储器与矩阵乘阵列输入端之间通过配置可重构的互联结构,可根据bert中的分支网络结构或端对端网络结构特点,高效向矩阵乘阵列传输输入特征值。
所述特征存储器与矩阵乘阵列输出端之间通过配置可重构的互联结构,可并行传输bert中的分支网络结果或端对端网络结构的输出特征值。
所述特征值存储器同时存储当前正在处理的神经网络层的输入特征值与输出特征值。中间层网络的输出特征值可立刻作为下一层网络的输入,中间层的计算结果不必传输到片外dram存储器中,减少片上片下存储单元之间的数据交互,降低功耗。
本发明中,当计算bert神经网络中分支网络部分时,三个特征存储器存储相同输入通道的三块数据。特征存储器中输入特征值依次广播到三个矩阵乘阵列中,完成三个分支的乘累加运算。
本发明中,当计算bert神经网络中端到端网络部分时,根据该层神经网络的输入、输出通道数量,特征值存储器的特征值可依次广播到三个乘矩阵阵列,完成神经网络一个输入通道、三个输出通道的乘累加运算;或三个特征存储器中的特征值与三个乘矩阵阵列点对点连接,完成三个输入通道、一个输出通道计算。
本发明中,当计算bert神经网络中端到端网络部分时,softmax与点积计算单元不参与计算,此时关闭以减少计算功耗。
本发明中,权重特征存储器采用乒乓(ping-pong)的传输方式从片外dram中的权重中读取权重。
本发明将各分支同时计算并将产生的输出特征值及时进行后处理,实现了针对加速bert神经网络运算的深度学习加速器。解决了bert神经网络中分支结构输出特征值存储浪费存储空间的问题。与cpu/gpu或传统的神经网络加速器相比,本发明加速器可减少特征值存储所需空间,降低片内与片外以及片内不同单元的数据交互,降低计算时间和功耗。本发明同时通过配置存储单元与计算单元间可重构的数据互联,满足bert神经网络中的分支网络结构计算要求同时,可用于端到端的神经网络计算。
附图说明
图1是本发明顶层电路框图。
图2是本发明加速的bert神经网络计算流程图。
具体实施方式
在下文中结合图示在参考实施例中更完全地描述本发明,本发明提供优选实施例,但不应该被认为仅限于在此阐述的实施例。
实施例是一个用于加速bert神经网络运算的深度学习加速器,图1是其顶层电路框图。
所述加速器包括三个特征值存储器,两个权重存储器,三个矩阵乘阵列,一个softmax与点积计算单元,一个控制器与片上片外接口。
图2是加速的bert神经网路计算流程图。其主要包括两部分:多头注意力分支神经网络结构与前馈端到端神经网络结构。在进行多头注意力神经网络计算时,相同的输入分别与三个分支的权重进行矩阵乘预算,得到的输出特征值在后处理时经过softmax概率函数与点积运算得到最终该部分网路的输出特征值,并作为前馈端到端神经网络的输入。
在计算多头注意力网络时,三个特征存储器存储相同输入通道的三块数据。特征存储器中输入特征值依次广播到三个矩阵乘阵列中。同时,三个乘累加阵列分别接收来自权重存储器的三个分支的权重,完成乘累加操作。每一个时钟周期产生的输出特征值立刻进入softmax与点积计算单元完成后处理运算得到最终的输出特征值。输出特征值不同通道一次传输到三个特征值存储器中,作为前馈网络的输入。
在计算前馈网络时,根据该层神经网络的输入、输出通道数量,特征值存储器的特征值可依次广播到三个乘矩阵阵列,完成神经网络一个输入通道、三个输出通道的乘累加运算;或三个特征存储器中的特征值与三个乘矩阵阵列点对点连接,完成三个输入通道、一个输出通道计算。
在上述计算过程中,若权重存储器不能存储网络中的全部权重。其采用乒乓的方式,经过片上片外接口读取片外dram中的权重。保证权重能及时读取到片上。避免因等待权重传输而暂停计算造成的计算延时。
以上通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
技术特征:
1.一种用于加速bert神经网络运算的深度学习加速器,其特征在于,包括:
三个矩阵乘阵列,用于计算神经网络中的乘累加操作;
一个softmax与点积计算单元,用于计算神经网络的softmax概率函数,并对分支网络的输出进行点乘得到最终的输出特征值;
三个特征存储器,用于存储输入、输出特征值;
两个权重存储器,用于存储网络的权重;
一个控制器和片上片外接口,用于控制片外dram中的数据与片上数据进行交互;
所述特征存储器与矩阵乘阵列输入端之间通过配置可重构的互联结构,可根据bert中的分支网络结构或端对端网络结构特点,高效向矩阵乘阵列传输输入特征值;
所述特征存储器与矩阵乘阵列输出端之间通过配置可重构的互联结构,可并行传输bert中的分支网络结果或端对端网络结构的输出特征值;
所述特征值存储器同时存储当前正在处理的神经网络层的输入特征值与输出特征值;中间层网络的输出特征值可立刻作为下一层网络的输入,中间层的计算结果不必传输到片外dram存储器中,减少片上片下存储单元之间的数据交互,降低功耗。
2.根据权利要求1所述的加速bert神经网络运算的深度学习加速器,其特征在于,当计算bert神经网络中分支网络部分时,三个特征存储器存储相同输入通道的三块数据;特征存储器中输入特征值依次广播到三个矩阵乘阵列中,完成三个分支的乘累加运算。
3.根据权利要求1所述的加速bert神经网络运算的深度学习加速器,其特征在于,当计算bert神经网络中端到端网络部分时,根据该层神经网络的输入、输出通道数量,特征值存储器的特征值可依次广播到三个乘矩阵阵列,完成神经网络一个输入通道、三个输出通道的乘累加运算;或三个特征存储器中的特征值与三个乘矩阵阵列点对点连接,完成三个输入通道、一个输出通道计算。
4.根据权利要求3所述的加速bert神经网络运算的深度学习加速器,其特征在于,当计算bert神经网络中端到端网络部分时,softmax与点积计算单元不参与计算,此时关闭以减少计算功耗。
5.根据权利要求1所述的加速bert神经网络运算的深度学习加速器,其特征在于,权重存储器采用乒乓的传输方式从片外dram中的权重中读取权重。
技术总结
本发明属于集成电路技术领域,具体为一种用于加速BERT神经网络运算的深度学习加速器。本发明加速器包括:三个矩阵乘阵列,用于计算乘累加操作;一个Softmax与点积计算单元,用于计算Softmax概率函数,并对分支网络输出进行点乘得到输出特征值;三个特征存储器,用于存储输入、输出特征值;两个权重存储器;一个控制器和片上片外接口,用于控制片外DRAM中的数据与片上数据进行交互。本发明针对神经网络中的分支网络结构进行优化,有效减少中间数据的存储空间,降低片外片上数据交互次数,降低功耗;同时通过配置存储单元与计算单元间可重构的数据互联,满足BERT神经网络中的分支网络结构计算要求,可用于端到端的神经网络计算。
技术研发人员:刘诗玮;张怡云;史传进
受保护的技术使用者:复旦大学
技术研发日:2019.11.23
技术公布日:2020.04.24
- 还没有人留言评论。精彩留言会获得点赞!