一种文本分类方法及系统与流程
本发明涉及深度学习领域的文本分类模型的构建方法,具体涉及一种bert模型的改进方法及其在文本分类上的应用。
背景技术:
文本分类问题是nlp领域的一个经典问题,它积累了许多的方法。早期的文本分类主要是基于传统的机器学习方法,如基于tf-idf的文本分类等。随着深度学习的发展,也涌现出了许多的基于深度学习的文本分类模型,如fast-text,text-cnn等。直至2018年10月,google正式公开了一个迁移学习模型bert并获得了极好的效果,它彻底改变了预训练产生词向量和下游具体nlp任务的关系,使用迁移学习的方法来解决nlp领域的问题也成为一个重要方向。
然而,bert模型是通过字进行编码而没有考虑到字词之间的关系的问题,导致了其在文本分类上仍然存在效果不好的问题。
技术实现要素:
针对上述的bert模型分类中存在的不是通过词编码的向量的问题,因此本发明从通过加入词向量表示句子并重新训练模型最终实现模型的优化,以得到更好的模型分类效果。
技术方案是:
一种文本分类方法,包括如下步骤:
第1步,获得文本数据集;
第2步,对数据集数据分别进行字向量编码、文本向量编码和位置向量编码,并加入词向量编码方式;
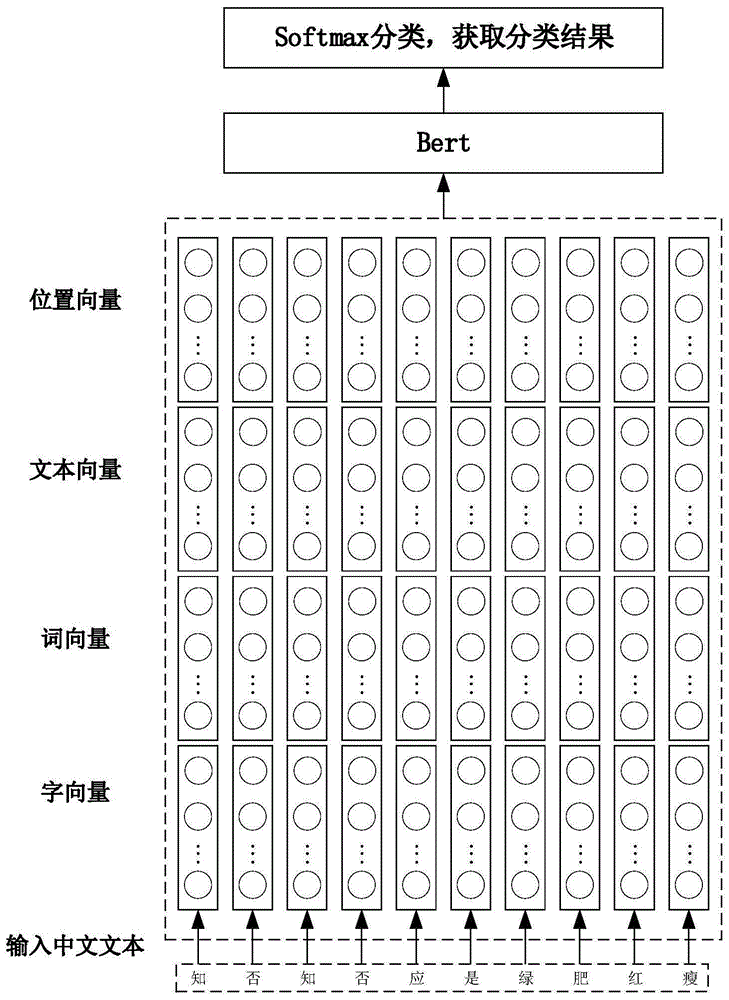
第3步,将第2步得到的字向量、词向量、文本向量和位置向量一起输入至bert模型中进行模型预训练,得到新的预训练模型;
第4步,采用实际分类数据对预训练模型进行迭代微调,得到实际分类模型;
第5步,采用第4步得到的实际分类模型对实际业务待分类文本进行分类处理。
在一个实施方式中,所述的第2步中的词向量的编码方式是:用1表示当前位置的字与前一个字是一个词,否则为0。
在一个实施方式中,所述的第1步中的文本数据集还需要经过数据清洗处理。
在一个实施方式中,第2步中对数据集数据编码后生成的向量中包括了:字向量、文本向量、位置向量以及词向量。
一种文本分类系统,包括:
数据集获取模块,用于获得文本数据集;
向量生成模块,用于根据文本数据集生成字向量、词向量、句向量和位置向量;
bert预训练模型模块,用于根据向量生成模块生成的字向量、词向量、句向量和位置向量共同输入到bert模型中进行模型的预训练;
bert模型微调模块,用于根据实际数据微调预训练模型,得到一个更为适合实际数据的分类模型。
分类模块,用于将需要分类的文本输入至训练好的bert模型模块中进行文本分类。
有益效果
本发明通过解决原来的bert模型未考虑字词关系的问题,得到更好的待分类句子的句向量表示,以获得更好的文本分类效果。本发明获得了一种改进的bert模型,并在公开数据集thucnews上进行文本分类,在3个epoch下,该模型的分类效果98.2%相比于原始的bert的96.8%有了1.4%的提升,模型微调效果更好。
附图说明
图1是本发明的方法图。
图2是本发明中使用的thucnews数据集。
具体实施方式
以下技术方案的介绍以中文文本分类领域中常用的thucnews数据集为例,但本发明获得的模型并不局限于中文文本分类领域,thucnews数据集的使用亦非本发明的特征。
第1步,准备预训练模型数据集。从互联网上下载公开中文数据集并进行数据清洗。
第2步,对数据集数据分别进行字向量编码、文本向量编码和位置向量编码,并加入词向量编码方式。
对上述获取的数据集,使用jieba分词或其它工具对文本进行分词,从而增加模型的词编码向量;另外,字编码、文本句子编码和位置编码方式等与原始的bert使用相同的方法进行处理,之后得到的向量中就包含了:字向量、词向量、文本向量、位置向量(如图1所示);本发明的改进点在于,在原始的bert模型使用的编码向量中再增加了一个词向量表示,用1表示当前位置的字与前一个字是一个词,否则为0,得到句子最终的词向量表示。词向量中的标引1或0,可以通过现有的其它文本处理工具转化生成得到。
第3步,将词向量与字向量、位置向量、文本向量共同用于bert模型的预训练,得到基于字、词、句子、位置等四个维度的预训练模型;本实施例中所采用的bert模型中的一些主要参数设置为:输入句子最大长度为128,学习率(lr)为5e-5,每次训练的数据量batch_size为32,训练数据训练的总次数epoch为3,并采用了softmax进行分类。
第4步,准备thucnews中文分类公开数据集,并将数据集划分出部分用于后续模型效果测试。
第5步,基于改进后的bert预训练模型,根据thucnews数据进行模型微调,模型迭代,直至达到收敛条件,得到最终的实际分类模型。
第6步,使用改进后的模型进行分类。采用的验证数据是thucnews原始数据集中划分出来的未进行模型训练的数据集。
本发明中,通过在输入的字向量、位置向量、文本向量中增加文本的词向量表示的方法重新进行模型预训练,解决了原来的bert模型未考虑字词关系的问题,既考虑了文本字词之间的关系,又保证了文本句向量表示更为准确,从而实现提升文本分类效果的目的。
分类模型的效果对比:
该模型的分类效果:精确率98.2%,相比于原始的bert的96.8%有了1.4%的提升;召回率98.8%,相比于原始的bert的96.2%有了2.6%的提升,模型微调效果更好。
技术特征:
1.一种文本分类方法,其特征在于,包括如下步骤:
第1步,获得文本数据集;
第2步,对数据集数据分别进行字向量编码、文本向量编码和位置向量编码,并加入词向量编码方式;
第3步,将第2步得到的字向量、词向量、句向量和位置向量一起输入至bert模型中进行模型预训练,得到新的预训练模型;
第4步,采用实际分类数据对预训练模型进行迭代微调,得到实际分类模型;
第5步,采用第4步得到的实际分类模型对实际业务待分类文本进行分类处理。
2.根据权利要求1所述的文本分类方法,其特征在于,在一个实施方式中,所述的第2步中的词向量的编码方式是:用1表示当前位置的字与前一个字是一个词,否则为0。
3.根据权利要求1所述的文本分类方法,其特征在于,在一个实施方式中,所述的第1步中的文本数据集还需要经过数据清洗处理。
4.根据权利要求1所述的文本分类方法,其特征在于,在一个实施方式中,第2步中对数据集数据编码后生成的向量中包括了:字向量、文本向量、位置向量以及词向量。
5.一种文本分类系统,其特征在于,包括:
数据集获取模块,用于获得文本数据集;
向量生成模块,用于根据文本数据集生成字向量、词向量、句向量和位置向量;
bert预训练模型模块,用于根据向量生成模块生成的字向量、词向量、句向量和位置向量共同输入到bert模型中进行模型的预训练;
bert模型微调模块,用于根据实际数据微调预训练模型,得到一个更为适合实际数据的分类模型;
分类模块,用于将需要分类的文本输入至训练好的bert模型模块中进行文本分类。
技术总结
本发明公开了一种文本分类方法及系统。本发明考虑到Bert基于字编码的局限性,它严重的损失了词中字的内在关系信息,本发明在Bert的基础上增加了词的位置编码方式,因此得到的句向量由字向量、句向量、词向量和位置信息四个部分组成,获取包含了词的信息的句向量表示,用这样的句向量训练模型进行分类模型训练,最后将该模型用于中文句子分类。
技术研发人员:陈旋;吕成云;蔡栩
受保护的技术使用者:江苏艾佳家居用品有限公司
技术研发日:2019.11.29
技术公布日:2020.05.08
- 还没有人留言评论。精彩留言会获得点赞!