一种基于迁移学习的音频分类方法与流程
本发明具体涉及到一种基于迁移学习的音频分类方法。
背景技术:
音频分类是音频平台重要组成部分之一。音频分类首先需要人工标注一批分类数据。如果标注大量数据,标注成本高,模型效果好;如果标注少量数据,标注成本低,模型效果差,因此音频分类的方法需要进一步的改进。
技术实现要素:
针对上述现有技术存在的缺陷,本发明要解决的技术问题是:可以不需要大量标注数的低成本情况下,达到好的模型效果。
一种基于迁移学习的音频分类方法,包括如下步骤:
人工标注音频分类数据,建立音频分类数据集;
收集公开的文本分类数据,建立公开数据集;
筛选出公开数据集中分类在音频分类数据集类别中的数据并与音频分类数据集组成训练集;
利用训练集训练分类模型;
利用分类模型对音频进行分类。
进一步地,所述分类模型的loss为交叉熵loss。
进一步地,所述分类模型的交叉熵loss的公式为:
l=ld+lc;
data是训练数据集合,d是其中一条样本;dc是它对应的分类,如果是二分类则dc是[0,1]或者[1,0];如果是多分类,则dc是某一维度为1,其他维度为0的k维数组,k是分类数据量;pj(d)表示模型预测的d属于第j个分类的概率。
进一步地,所述lc用于区分音频的类别。
进一步地,所述ld用于区分数据来自音频分类数据集还是公开数据集。
与现有技术相比,本发明的至少包括以下有益效果:
1.成本低,不需要大量标注数据;
2.集合公开数据集和音频分类数据集,保证模型效果。
附图说明
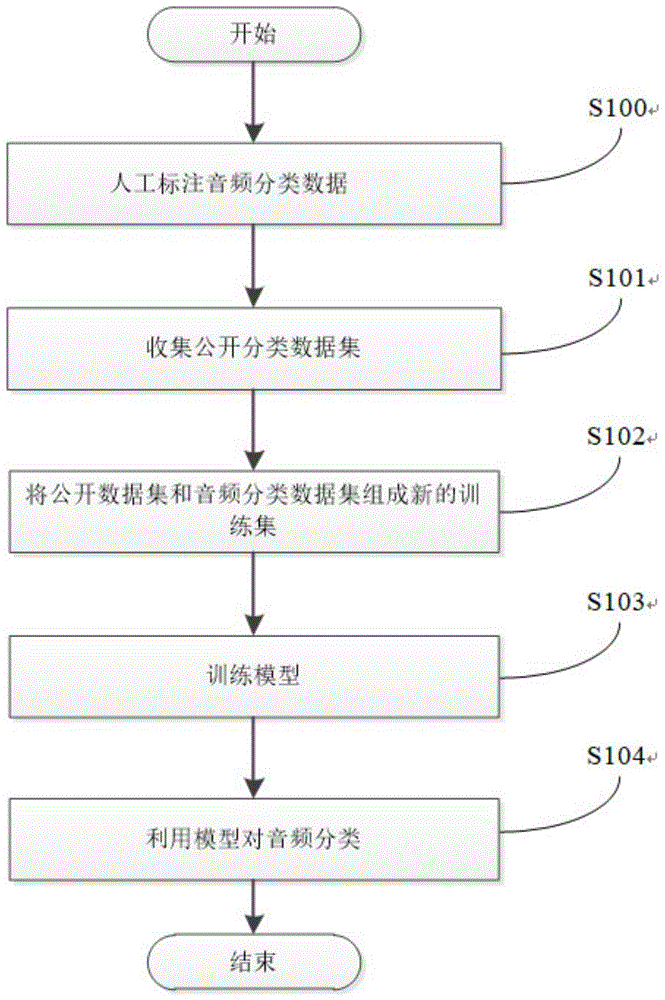
图1为本发明一种基于迁移学习的音频分类方法的流程图。
具体实施方式
以下实施例对本发明进行说明,但本发明并不受这些实施例所限制。对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换,而不脱离本发明方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
如图1所示,一种基于迁移学习的音频分类方法,包括如下步骤:
步骤s100:人工标注音频分类数据,建立音频分类数据集,先通过人工标注定量的音频分类数据;
步骤s101:收集公开的文本分类数据,建立公开数据集;
步骤s102:筛选出公开数据集中分类在音频分类数据集类别中的数据并与音频分类数据集组成训练集;
步骤s103:利用训练集训练分类模型;
步骤s104:利用分类模型对音频进行分类。
不需要大量标注数据有效降低成本,通过集合公开数据集和音频分类数据集,保证模型效果。
本发明所述分类模型的loss为交叉熵loss,交叉熵loss的公式为:
l=ld+lc;
data是训练数据集合,d是其中一条样本;dc是它对应的分类,如果是二分类则dc是[0,1]或者[1,0];如果是多分类,则dc是某一维度为1,其他维度为0的k维数组,k是分类数据量;pj(d)表示模型预测的d属于第j个分类的概率。
本发明所述lc用于区分音频的类别。
本发明所述ld用于区分数据来自音频分类数据集还是公开数据集。
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
技术特征:
1.一种基于迁移学习的音频分类方法,其特征在于,包括如下步骤:
人工标注音频分类数据,建立音频分类数据集;
收集公开的文本分类数据,建立公开数据集;
筛选出公开数据集中分类在音频分类数据集类别中的数据并与音频分类数据集组成训练集;
利用训练集训练分类模型;
利用分类模型对音频进行分类。
2.根据权利要求1所述一种基于迁移学习的音频分类方法,其特征在于:所述分类模型的loss为交叉熵loss。
3.根据权利要求2所述一种基于迁移学习的音频分类方法,其特征在于:所述分类模型的交叉熵loss的公式为:
l=ld+lc;
data是训练数据集合,d是其中一条样本;dc是它对应的分类,如果是二分类则dc是[0,1]或者[1,0];如果是多分类,则dc是某一维度为1,其他维度为0的k维数组,k是分类数据量;pj(d)表示模型预测的d属于第j个分类的概率。
4.根据权利要求3所述一种基于迁移学习的音频分类方法,其特征在于:所述lc用于区分音频的类别。
5.根据权利要求3所述一种基于迁移学习的音频分类方法,其特征在于:所述ld用于区分数据来自音频分类数据集还是公开数据集。
技术总结
本发明公开了一种基于迁移学习的音频分类方法,包括如下步骤:人工标注音频分类数据,建立音频分类数据集;收集公开的文本分类数据,建立公开数据集;筛选出公开数据集中分类在音频分类数据集类别中的数据并与音频分类数据集组成训练集;利用训练集训练分类模型;利用分类模型对音频进行分类。不需要大量标注数据,有效降低成本,集合公开数据集和音频分类数据集,保证模型效果。
技术研发人员:杜春河;丁宁
受保护的技术使用者:广州荔支网络技术有限公司
技术研发日:2019.12.26
技术公布日:2020.05.22
- 还没有人留言评论。精彩留言会获得点赞!