一种中医分词算法的制作方法
本发明涉及自然语言处理的应用技术领域,具体是一种中医分词算法。
背景技术:
中文的特点是没有类似空格之类显示标示词的边界标志,因此,如何对词进行切分,即中文分词的研究,是中文信息处理的基础与关键。一个成熟的自动分词系统能够为语言的深入研究提供数据支持,也是句法分析、全文检索等复杂信息处理系统的前提。对于一般的文献,中文分词的算法已经比较成熟,已有多种开源中文分词软件,但对于专业领域的文献,中文分词的研究才刚起步。中医医案文献是诊疗过程的记录,是理法方药的具体体现,是继承、学习、研究中医的重要资料,信息含量大,属于专业领域的文献。
根据词组的统计,就会发现两个相邻的字出现的频率最多,那么这个词就很重要。就可以作为用户提供字符串中的分隔符,这样来分词。目前开源的分词对通用领域分词效果尚可,但是对于中医描述,偏古文的分词效果比较差。
技术实现要素:
本发明的目的在于提供一种中医分词算法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
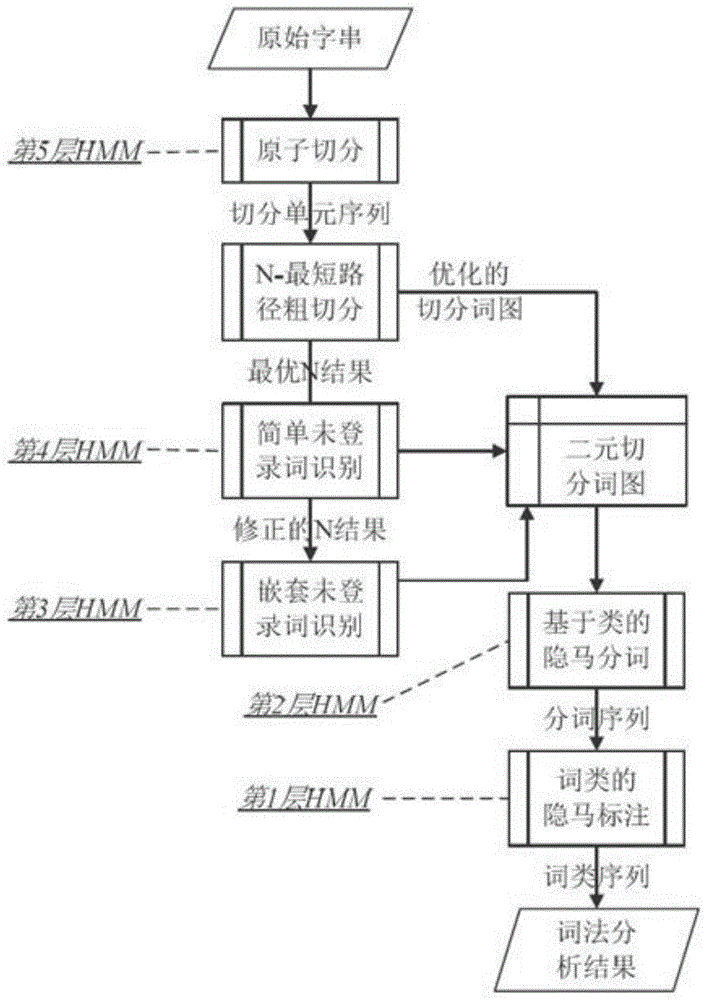
一种中医分词算法,具体步骤如下:首先是对中医医案的文本进行原子切分,其次引入中医领域词典和语料库完成n-最短路径的粗切分以覆盖尽可能多的歧义,然后通过多层隐马模型对未登录词进行识别,接着用基于类的隐马模型进行全局最优分词,最后对分词结果进行词性标注。
作为本发明的进一步方案:在完成原子切分的同时还需要完成大小写、简繁体、全角半角的规范。
作为本发明的进一步方案:所述语料库是基于实际使用中真实出现过的语言材料,是自然语言处理研究的基础资源。
作为本发明的进一步方案:所述语料库中文本的切分单位包括词、短语和中医术语。
作为本发明的进一步方案:所述人名标注为nr,地名标注为ns。
作为本发明的进一步方案:所述名词均标注为n,动词均标注为v。
作为本发明的进一步方案:所述语料库中对文本进行人工分词与词性标注部分为标注语料库。
与现有技术相比,本发明的有益效果是:本发明打破中医领域分词效果差的瓶颈,为健康领域的智能对话和中医知识图谱,中医辅助诊疗系统奠定基础,提升基础语义组件的效果。
附图说明
图1为本发明的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1:请参阅图1,汉语分词的主要瓶颈是切分排歧和未登录词识别,采用层叠隐马模型(hierarchicalhiddenmarkovmodel,hhmm)的词法分析框架较好地解决了这一问题。该模型是中国科学院计算技术研究所在传统隐马模型(hiddenmarkovmodel,hmm)基础上进行扩展及泛化后提出的,基于这一框架研制的汉语词法分析系统(instituteofcomputingtechnologychineselexicalanalysissystem,ictclas),将中文分词、词性标注、命名体识别、切分排歧等词法分析任务整合到一个相对统一的理论模型中,是目前最好的汉语词法分析系统之一,分词精度达到98.45%。
本研究基于python实现了ictclas的算法,本发明实施例中,一种中医分词算法,首先是对中医医案的文本进行原子切分,同时完成大小写、简繁体、全角半角的规范,其次引入中医领域词典完成n-最短路径的粗切分以覆盖尽可能多的歧义,然后通过多层隐马模型对未登录词进行识别,接着用基于类的隐马模型进行全局最优分词,最后对分词结果进行词性标注。
语料库是基于实际使用中真实出现过的语言材料,是自然语言处理研究的基础资源。标注语料库是对文本进行人工分词与词性标注的语料库,限于时间与精力,本研究所建立的中医医案文献标注语料库仅收录了医案20000例,涉及内、外、妇、儿各科,共174418字符。语料库的选材以正式出版的中医医案为语料来源,从各科医案文献中随机选取一定数量的医案,分别选取1911年以前的古代医案文献300例,1949年以后的现代医案文献300例。
语料库中文本的切分单位包括词、短语、中医术语和其他切分单位,词性标记依据《计算所汉语词性标记集(ictpos3.0)》,人名标注为nr,地名标注为ns,其他则仅取其第一级的词性标注,如名词均标注为n,动词均标注为v,对于其下一级的词性则未做区分标注,如名词下一级的机构团体名、名词性语素和动词下一级的副动词、名动词、趋向动词等,标点符号标注为w。此外,针对中医领域词典,增加了专门的中医术语词性标记中药名zym、中医症状zzz、中医方剂名zfm、中医病名zbm、中医其他术语zo。在标注时,词(切分单位)之间用空格分隔,词(切分单位)与词性标记间用“/”号分隔,标注语料样例如下:
患者/n男性/n。/w咽中痛/zzz,/w声/n瘖/zzz,/w吞咽困难/zzz。/w两寸脉/zo独/d浮/a虚/a。/w方/n用/v苦酒汤/zfm。/w取/v鸡子白/zym以/p清火/zo润肺/zo,/w半夏/zym破结/zo散邪/zo,/w合/v苦酒/zym散瘀/zo解毒/zo。/w仅/d服/v一/m剂/q,/w痛/zzz止/v,/w声/n开/v。/w。
实施例2,在实施例1的基础上,本发明通过以下4个基本指标对分词结果进行评测:准确率(precision)、召回率(recall)、f-评价(f-score,综合准确率和召回率的评价指标)、词性标注准确率(accuracy)。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
技术特征:
1.一种中医分词算法,其特征在于,具体步骤如下:首先是对中医医案的文本进行原子切分,其次引入中医领域词典和语料库完成n-最短路径的粗切分以覆盖尽可能多的歧义,然后通过多层隐马模型对未登录词进行识别,接着用基于类的隐马模型进行全局最优分词,最后对分词结果进行词性标注。
2.根据权利要求1所述的一种中医分词算法,其特征在于,在完成原子切分的同时还需要完成大小写、简繁体、全角半角的规范。
3.根据权利要求1所述的一种中医分词算法,其特征在于,所述语料库是基于实际使用中真实出现过的语言材料,是自然语言处理研究的基础资源。
4.根据权利要求3所述的一种中医分词算法,其特征在于,所述语料库中文本的切分单位包括词、短语和中医术语。
5.根据权利要求4所述的一种中医分词算法,其特征在于,所述人名标注为nr,地名标注为ns。
6.根据权利要求4所述的一种中医分词算法,其特征在于,所述名词均标注为n,动词均标注为v。
7.根据权利要求3所述的一种中医分词算法,其特征在于,所述语料库中对文本进行人工分词与词性标注部分为标注语料库。
技术总结
本发明公开了一种中医分词算法,具体步骤如下:首先是对中医医案的文本进行原子切分,其次引入中医领域词典和语料库完成N‑最短路径的粗切分以覆盖尽可能多的歧义,然后通过多层隐马模型对未登录词进行识别,接着用基于类的隐马模型进行全局最优分词,最后对分词结果进行词性标注,本发明打破中医领域分词效果差的瓶颈,为健康领域的智能对话和中医知识图谱,中医辅助诊疗系统奠定基础,提升基础语义组件的效果。
技术研发人员:安静梅;张凯文;钱小菲;魏宇涛
受保护的技术使用者:上海国民集团健康科技有限公司
技术研发日:2020.01.16
技术公布日:2020.06.09
- 还没有人留言评论。精彩留言会获得点赞!