一种同步语义和视觉信息的并行LSTM图像描述生成方法
一种同步语义和视觉信息的并行lstm图像描述生成方法
技术领域
1.本发明主要涉及图像理解领域,涉及一种同步语义和视觉信息的并行lstm,以及基于该并行lstm的图像描述生成方法。
背景技术:
2.图像描述是计算机视觉的重要研究内容之一,是图像理解的基础,也是研究热点之一。其过程是对给定图像生成一个语句,该语句能准确描述图像内容。
3.图像描述的方法参考了机器翻译,基于编码器-解码器的框架,利用卷积神经网络作为编码器提取特征,然后利用递归神经网络解码生成图像的描述语句。
技术实现要素:
4.本发明的目的在于提出一种同步语义和视觉信息的并行lstm,以及基于该并行lstm的图像描述生成方法。该图像描述生成方法首先利用多示例多标签miml网络提取属性特征,然后通过卷积神经网络resnet101提取视觉特征,最后通过本文提出的并行lstm来生成图像的描述语句。
5.本发明的技术方案如下:
6.(1)动态语义特征提取:图像通过miml提取属性特征后,将该特征输入并行lstm中的属性lstm,将每个时间步的隐藏层状态作为动态语义特征;
7.(2)视觉特征提取:图像通过resnet101网络提取视觉特征;
8.(3)融合语义和视觉信息:将并行lstm结构中属性lstm在每一个时间步输出的动态语义特征通过注意力机制与相应时间步的视觉lstm的视觉特性相结合,得到加权的上下文特征;
9.(3)同步语义和视觉信息:属性lstm在首次输入属性特征后,其本身包含了语义特征,在随后每次输入单词时,结合自身信息和当前单词,改变自身信息,因此其输出的隐藏层状态可视为动态语义特征。此外,并行lstm结构中的属性lstm在时间步上领先视觉lstm一个时间步,使得为视觉lstm提供的动态语义特征恰好是视觉lstm当前时间步所需要的语义信息,以此达到同步。
10.(4)生成图像描述语句:将同步语义和视觉信息融合得到的上下文特征和上一时间步生成的单词作为并行lstm结构中的视觉lstm的输入,通过迭代得到语句中每个单词。
附图说明
11.图1同步语义和视觉信息的并行lstm图像描述生成方法流程图
12.图2同步语义和视觉信息的并行lstm图像描述生成方法框架图
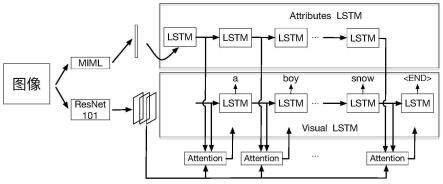
13.图3并行lstm的框架图
具体实施方式
14.下面结合附图对本发明作进一步详细说明。
15.本发明所述的同步语义和视觉信息的并行lstm图像描述生成方法流程图如1所示,图1包括4个单元:多示例多标签网络(miml)、卷积神经网络(resnet 101)、并行lstm和描述生成。
16.本发明所述的同步语义和视觉信息的并行lstm图像描述生成方法框架图如2所示,并行lstm的具体框架图如图3所示。
17.单元101为多示例多标签网络miml,如图2所示,其用于产生图像中的对象和属性信息作为属性特征。其输入为原始图像i,输出为属性特征v
att
(i),其维度为1024。
18.单元102为基于resnet101的卷积神经网络,如图2所示,用于产生图像的视觉特征。其输入为原始图像i,输出维度为[14,14,2048]的视觉特征。其中单元101的miml的基础网络部分和单元102的resnet101共享前两个瓶颈层(bottleneck)的参数。
[0019]
单元103为并行lstm,如图2所示,主要包括属性lstm和视觉lstm两个部分。其具体实现细节如图3所示,属性lstm用于产生动态的语义特征,视觉lstm用于融合语义特征和视觉特征,并产生单词。属性lstm的初始输入为属性特征v
att
(i),之后的每一步输入为上一步生成单词的词嵌入特征x
t
,提取其当前时间步的隐藏层状态h
t
,相关计算为:h1=lstm(v
att
(i),h0,m0)h
t
=lstm(x
t
,h
t-1
,m
t-1
)其中h0和m0为lstm的初始化隐藏层状态和细胞状态,由于首次输入了属性特征以及在后续的时间步都会输入和文本相关的单词信息,因此当前生成的隐藏层状态包含了动态的语义特征。对于视觉lstm,使用注意力机制将动态语义特征和视觉特征融合得到上下文特征,动态语义特征领先视觉特征一个时间步骤,能够提供当前时间步骤所需信息,达到同步功能。上下文特征的计算公式如下:α
t
=softmax(z
t
)其中v为视觉特征,为动态语义特征,为视觉lstm的隐藏层状态,wz、wv、为训练参数,αh为调节因子,c
t
为上下文特征。加权因子α
t
的计算由视觉特征、动态语义特征和视觉lstm的隐藏层状态决定,因此经过加权的视觉特征和经过调节的动态语义特征融合后,能够关注当前时间步应该关注的重要信息。
[0020]
单元104为单词生成模块,在t时刻,获取到视觉lstm的隐藏层状态后,生成的单词概率分布可由如下公式表示:概率分布可由如下公式表示:其中f为非线性映射函数,输出维度为词典大小。p(y
t
∣y1,
…
,y
t-1
,i)为t时刻生成的单词概率分布,取最大值的索引并在词典中找到其位置,所对应的单词即为生成单词。
技术特征:
1.一种同步语义和视觉信息的并行lstm图像描述生成方法,其特征包括以下步骤:(1)通过多示例多标签miml网络提取属性特征;(2)通过resnet101网络提取视觉特征;(3)将属性特征和视觉特征分别输入并行lsmt的属性lstm和视觉lstm;(4)利用注意力机制,结合属性lstm每个时间步输出的动态语义特征和视觉lstm的视觉特征得到上下文特征;(5)将上下文特征和上一步生成的单词输入到并行lsmt的视觉lstm得到当前时间步生成的单词。2.根据权利要求1所述的方法,其特征在于步骤(1)和(2)中,miml的基础网络部分和resnet101网络共享前两个瓶颈层(bottleneck)的参数,从而保证底层特征相同,使得属性和视觉特征所表示的图像内容基本一致,并减少网络参数。3.根据权利要求1所述的方法,其特征在于步骤(3)和(4)中,动态语义特征和视觉特征的同步以及上下文特征的构建,属性lstm输出的动态语义特征领先视觉特征一个时间步,能够提供当前视觉lstm时间步所需语义信息,并利用注意力机制融合动态语义特征和视觉特征得到上下文特征。4.根据权利要求1所述的方法,其特征在于步骤(5)中,将上下文特征和上一时间步生成的单词输入视觉lstm得到当前时间步生成的单词。
技术总结
本发明公开了一种同步语义和视觉信息的并行LSTM,以及基于该并行LSTM的图像描述生成方法。该方法提出一种同步语义和视觉信息的并行LSTM,通过MIML和ResNet101分别提取属性特征以及视觉特征,并将属性特征和视觉特征作为并行LSTM的输入,在此基础上生成图像的描述语句。并行LSTM结构包含同步进行数据处理和信息传递的属性LSTM和视觉LSTM。属性LSTM的初始化输入为属性特征,通过迭代得到每一个时间步的隐藏层状态,将其视为动态语义特征。视觉LSTM则通过注意力机制,在每一个时间步动态融合属性LSTM输出的语义特征和自己产生的视觉特征,为下一个时间步提供更丰富的信息。这种同步的信息融合方式,使得该方法能在每个时间步同步关注重要的语义和视觉信息,从而产生更为准确的图像描述语句。的图像描述语句。的图像描述语句。
技术研发人员:张静 李康康 刘刚 王占全
受保护的技术使用者:华东理工大学
技术研发日:2020.11.30
技术公布日:2022/6/4
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1