一种基于SCCNN网络的图片分类方法
一种基于sccnn网络的图片分类方法
技术领域
1.本发明涉及深度学习、孪生网络和ibs算法在图片分类方向的创新。
背景技术:
2.随着现代生活水平的提高以及疾病年轻化趋势的出现,人们越发关注自己的健康状态。病人需求的增加、计算机硬件能力的发展和ai医疗的普及,在这样的时代背景下借助神经网络来协助医生分析医疗数据中的患者的病情已经成为医学工作领域的火热趋势。
3.ibs(information-based similarity)算法能够较好地对比两个系统的相似程度。本发明利用改良的ibs算法——disibs算法,提出了一种新的孪生交叉对比网络结构,sccnn(siamese cross contrast neural networks)。该网络一定程度上降低了输入网络的数据选择的约束条件,从而能够让训练者在训练时可以更加轻松地预处理数据。disibs算法比传统的ibs算法在对两个系统的相似性的辨识度上更有效果,而且更加适应神经网络参数更新的节奏。经过实际测试,本网络在肝细胞癌(hcc)和肝内胆管癌(icc)的医疗图像分类上具有非常高的准确率。
技术实现要素:
4.本发明的目的在于克服传统的交叉对比神经网络在训练时的数据预处理阶段需要限制输入条件以及预测阶段需要和训练的数据一一对比的缺点,让数据的输入更有条理、预测的过程更为便利。针对这些问题,本发明提出了孪生对比神经网络结构以及能够衡量两个系统相似程度的disibs算法。经过测试,本发明在肝细胞癌和肝内胆管癌的医疗图像分类上效果良好。
5.本发明在图像分类问题上的解决方案主要分为三个部分:第一、利用孪生网络结构以及特殊的数据预处理策略优化网络的训练过程。第二、使用分类器对孪生网络输出的图片特征进行处理直接得到预测结果。第三、使用disibs算法并将其融入网络的损失函数。
6.本发明解决问题需要经过四个主要步骤。第一个是数据预处理步骤,本发明在训练时的数据预处理阶段,将采集两份数据,第一份数据的标签随机决定,第二份数据的标签类别由第一份数据的标签随机决定。处理完毕后,将两份数据分别放入孪生网络结构,孪生网络共享参数。第二个步骤是衡量孪生网络结构给出两份数据的特征向量组的相似程度并且将其量化,将量化好的结果用于损失函数的计算上。本发明使用的量化手段是使用disibs方法,它是传统ibs方法的改良方案。第三个步骤是将孪生网络输出的结果传给后置的分类器,通过分类器给出的预测结果计算给分类器的损失函数。然后通过分类器和孪生网络的损失函数分别更新分类器和孪生网络的网络参数。如此循环完成训练。最后一个步骤,在网络训练完成后,留下孪生网络的一半和分类器作为最终的网络结构。在预测时,用户直接输入图片,通过分类器的输出预测结果。
7.本发明的有益效果是该网络结构使得训练者在为网络的输入分配标签时能够减少工作量,同时又能保证网络的输入具有一定的随机性;而测试阶段可以直接根据分类器
的输出得到图片的分类结果,非常的高效且便利。另外,本发明提到的disibs方法是对传统ibs方法的改良,它比传统ibs方法更加能胜任交叉对比神经网络的优化工作。测试表明,本发明的网络结构在图像分类上具有更好的泛用性和精确性。
附图说明
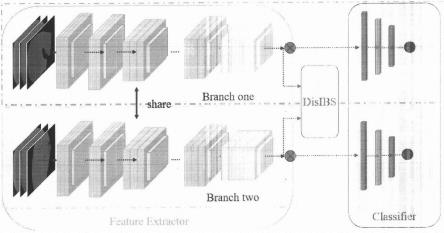
8.图1是本发明的整体网络结构。
9.图2是筛选输入网络数据使用的筛选策略。
10.图3是本发明网络结构中孪生网络的位置。
11.图4是本发明网络结构中disibs算法模块的位置。
12.图5是disibs算法模块的操作流程。
13.图6是disibs算法公式和传统modibs算法公式的对比。
14.图7是本发明网络结构中分类器模块的位置。
15.图8是本发明最终用于预测的模型结构。
具体实施方式
16.为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实例对本发明进行详细的描述。
17.先描述本发明的各个模块功能及具体实现,再结合实例具体描述训练和验证步骤分别如何使用这些模块。该网络模块整体结构如图1所示。
18.第一,数据预处理模块。如图2所示。该模块负责从数据集中取出两组合适的数据,将其传入孪生网络。具体的做法是,首先在数据集中随机选取一个批次的数据,然后对第一批次的每个数据使用随机算法决定第二批次中对应数据的标签类别。随后将这两组图片分别送入孪生网络结构进行计算。
19.第二,孪生网络模块。如图3中红框部分所示。该模块负责给输入的图片组提取特征,将特征传给后面的disibs模块以及分类器模块。孪生网络使用的骨干网络可以是vgg、resnet等传统的网络结构,图2和3以resnet为例,根据测试这些网络结构都有较好的准确性。在训练过程中,孪生网络共享参数,方便网络参数的更新。在预测阶段,抛弃孪生网络的一半进行图片的特征提取。
20.第三,ibs计算模块。如图4中红框部分所示,其操作流程如图5所示。该模块衡量并且量化两组数据的差异性。ibs方法在衡量两个系统的相似程度方面有很好的效果,假设孪生网络最后一层有d个滤波器,每个滤波器输出一个的特征,一共d个特征。每个特征可以通过该特征在这d个特征中所占的权重计算出此特征在数据中出现的概率。这样,两个数据通过孪生网络后就会生成对应的长度为d的两组概率向量,向量中每个元素代表对应滤波器产生的特征在系统中出现的概率。ibs方法针对两个数据中每一个特征出现的概率的差异判断它们是否属于同一个系统。如果两个系统在每个特征上的概率都相近,则ibs的结果小。否则,ibs的结果大。本发明在传统的ibs算法的基础上,进行了一些改动。如图6所示。加入margin这一参数后,disibs的输出结果的范围被限定在了0到1之间,这个输出结果可以近似看作为两个系统不同的概率。在两个系统是完全随机去出的情况下,根据公式可以得出输出的结果是0.5。而noribs越大,两个系统就越不相似,输出结果就越接近于1,反之结
果越接近于0。基于disibs算法,本发明将disibs的量化差异策略以及孪生网络的损失函数的定义如下,结合图6中的计算公式,完整的ibs损失函数公式如下所示:
21.lossdisibs=(1-label
pair
)*log(1-disibs)-label
pair
*log(disibs)
22.其中,label
pair
和输入的两组数据的标签异同有关,0表示同源输入,1表示异源输入。
23.第四,分类模块。孪生网络后,接着一个分类器,如图7所示。分类器根据孪生网络给出的特征计算分类结果。分类器可以使用普通的交叉熵作为损失函数。在训练时,在每一轮的参数更新阶段,网络将根据分类器的损失函数和孪生网络的损失函数分别更新分类器和孪生网络的参数。最后的预测阶段单独拿出一侧的孪生网络以及分类器处理输入图片就可以得到预测的结果,最终用于预测的网络结构如图8所示。
技术特征:
1.本发明公开了一种孪生交叉对比神经网络模型,其特征在于对孪生网络模型双路输出的特征差异进行量化,基于量化结果定制损失函数。基于这个方法训练的网络在分类问题上具有很强的准确率。2.根据权利要求1所述的一种孪生交叉对比神经网络模型,其特征在于量化特征差异时使用disibs算法,它通过内置的参数,将输出范围限定在0到1之间,它既能够近似看成两个系统相似的概率,被其代入损失函数用其优化网络参数时又能提高优化的效率。3.根据权利要求1所述的一种孪生交叉对比神经网络模型,其特征在于在孪生网络的入口使用伪随机方法选择输入的两组数据,第一组数据随机选取,第二组数据根据第一组数据的标签状态随机选取。这能帮助训练者在训练阶段筛选输入数据时减少其工作量。
技术总结
本发明提出了一种全新的孪生交叉对比神经网络模型。该模型充分利用了孪生网络两路数据流并进的特点,根据两路输出的数据特征组的异同程度制作损失函数。同时提出了一种能够衡量、量化两个系统的相似程度的方法——DisIBS方法,这个方法相比传统的IBS方法对神经网络的适应性更强并且具有一定的物理意义。另外,该网络在训练的输入部分使用特殊的伪随机数据分类模式,减少了训练者在训练网络时筛选输入数据标签时的工作量。经过测试,该网络在图像分类方面有非常强的准确度与适用性。像分类方面有非常强的准确度与适用性。像分类方面有非常强的准确度与适用性。
技术研发人员:孙维宇 王琪元 陈颖
受保护的技术使用者:南京大学
技术研发日:2020.12.18
技术公布日:2022/7/9
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1