一种扩张部分重复码构造方法
本发明属于大数据处理领域,具体涉及一种扩张部分重复码构造方法。
背景技术:
近年来云计算技术的快速发展使得分布式云存储成为一种有效的数据存储解决方案。分布式存储系统采用云计算的理念,通过集群网格技术和分布式文件系统等功能,将分布在不同区域的独立存储设备(如磁盘、固态盘等)通过网络联合起来进行协同工作,共同为用户提供数据存储和访问服务。当前,分布式存储系统以其高效的存储性能,如高可用性、高可扩展性、低存储开销等,日益成为现代主流存储系统。
在大规模的集群部署过程中,出于存储成本的考虑,分布式存储系统通常采用商用硬件(如普通pc机、硬盘等)作为存储节点,价格低廉且具有良好的扩展性。然而,不断扩大的系统规模增加了故障发生的概率,如突发断电、节点离线以及硬件失效等故障,从而使得存储系统的可靠性面临严峻的考验。为了保证数据的可靠性,实际大规模文件系统需要引入数据冗余机制。传统基于数据拷贝的方案简单易于管理,并且支持高效的数据恢复。但是,数据备份机制的缺点在于存储开销大、存储效率低,特别是在存储大数据文件的时候,副本引起的开销是不可忽略的。
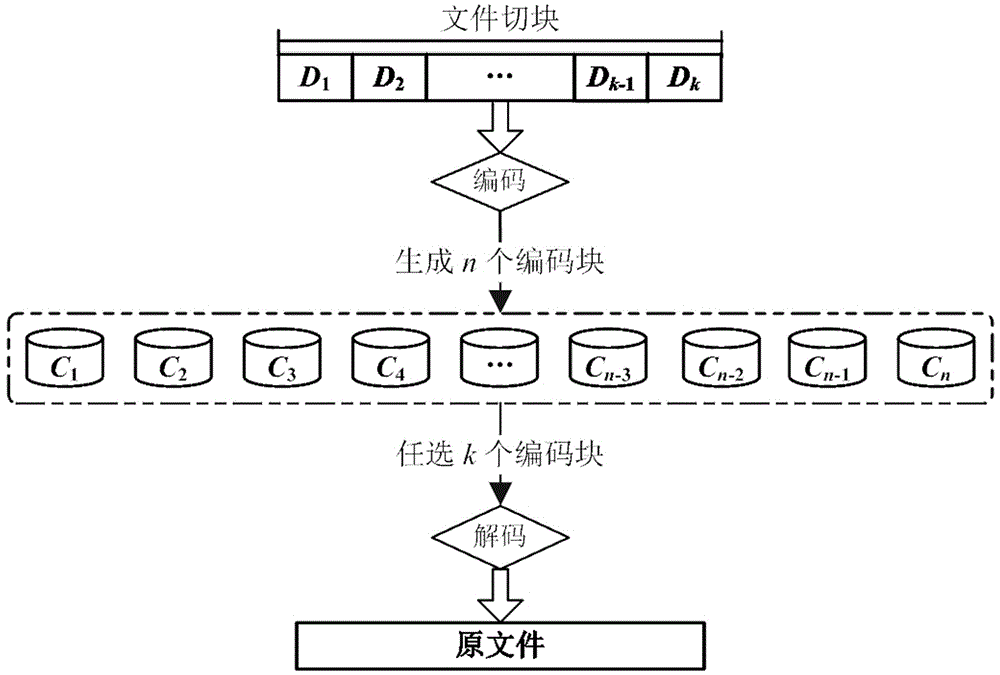
在相同冗余信息的情况下,纠删码技术可以大幅地提高系统的存储效率。分布式云存储系统通常采用最大距离可分(maximumdistanceseparable,mds)编码。具体来说,一个参数为(n,k)的mds码首先将原数据文件等分成k个大小相等的数据块,通过编码生成n个编码块并分别存储在n个不同节点上,其中系统中任意k个节点存储的数据就可以重构出原始文件,如图1为mds码的编解码方式示意图。这一过程称为数据重构过程,数据重构特性称为mds属性。reed-solomon码是一种典型的mds码。
当存储系统中出现节点失效时,为了维持系统既定的冗余度,需要恢复该失效节点的数据并将其存储到一个新引入的节点中,该过程称为节点修复过程。对传统的mds码来说,系统首先从k个存储节点下载数据并解码出原文件,重新编码再将生成的编码块存储到新的节点上,如图2为mds码的节点修复方式示意图。然而,为了恢复一个节点存储的数据而重构出整个原数据文件,对网络带宽来说是一种浪费。实际的网络存储环境中带宽资源比存储资源更加宝贵,因此这样的节点修复代价显然是不能接受的。
为了降低节点修复过程中的带宽消耗,研究人员在mds码的基础上提出了再生码(regeneratingcodes)的概念。再生码满足mds属性,即系统n个节点中任意k个节点存储的数据就可以重构出原数据文件;在节点修复过程中,替换节点需要在剩下的n-1个可用存储节点中随机连接d个并分别从这d个存储节点下载大小为β的数据,所以修复带宽为dβ。再生码的节点修复过程中下载的数据量小于原文件的大小,因此再生码的修复带宽优于传统的mds码。
然而,传统再生码的节点修复过程计算复杂度比较高,通常需要进行大量的有限域线性运算。每个参与修复的节点读出所存储的数据并进行特定的运算,再向替换节点传输组合后的数据块。考虑到实际系统中节点读写带宽小于网络带宽,因此读写带宽很容易成为系统性能瓶颈。
为了降低修复过程运算复杂度,研究人员在再生码的基础上进一步提出了部分重复(fractionalrepetition,fr)码的概念,指出了fr码可以提供精确有效的修复。如图3为部分重复码的编码过程示意图,fr码包含两个部分:一个外部mds码和一个内部重复码。原数据块经过mds编码后,将输出的编码块复制ρ倍再分散到各存储节点。当系统中发生节点失效时,可以通过从其它节点直接下载数据并存储到替换节点来完成修复。与mds码和再生码相比,fr码大幅提升了节点失效修复速度。
目前构造出的fr码一般采用基于表格的节点修复方式,系统中的失效节点具有较多的修复选择方案。但是,现有的fr码构造方式通常采用特定的正则图和组合设计,参数要求比较严格,并不适用于实际动态的分布式存储环境。
技术实现要素:
本发明的目的在于提供一种扩张部分重复码构造方法,该方法构造过程简单,是一种支持参数变化的扩张部分重复码构造方法。
本发明提供的这种扩张部分重复码构造方法,包括如下步骤:
s1.获取原数据文件;
s2.选择特定参数的可嵌入拟剩余设计;
s3.根据选择的可嵌入拟剩余设计的参数,对原数据文件进行mds编码;
s4.结合选择的可嵌入拟剩余设计,得到基础部分重复码;
s5.生成选择的可嵌入拟剩余设计对应的对称设计;
s6.通过生成的对称设计,得到扩张部分重复码。
所述的步骤s2具体为,选择一个参数为2-(θ,φ,λ)的可嵌入拟剩余设计,其中θ为可嵌入拟剩余设计中点的个数,φ为区组的大小;同时,满足θ个点中任意两个点出现在λ个不同的区组中,并且λ(θ-1)=(φ-1)(φ+λ)。
所述的步骤s3具体为,将原数据文件划分成大小相同的m份,通过参数为(θ,m)的mds编码后,获得θ个编码块。
所述的步骤s4具体为,将步骤s3中的θ个编码块与步骤s2中的可嵌入拟剩余设计的θ个点建立对应关系,并将每个区组当作一个存储节点,得到一个参数为(θ(φ+λ)/φ,φ,θ,φ+λ)的基础部分重复码。
所述的步骤s5具体为,根据步骤s2中选择的可嵌入拟剩余设计,增加若干点和区组,得到一个参数为2-(θ+φ+λ,φ+λ,λ)的对称设计,其中θ+φ+λ表示对称设计中点的个数,φ+λ表示区组的大小,满足θ+φ+λ个点中任意两个点出现在λ个不同的区组中。
所述的增加若干点和区组具体为,在可嵌入拟剩余设计θ个点的基础上,新增φ+λ个不同的点并将这φ+λ点存入一个新的区组,同时在原拟剩余设计中的每个区组增加λ个新引入的点。
所述的步骤s6具体为,将步骤s5中的对称设计的每个点当作一个编码块,每个区组当作一个存储节点,构造一个参数为(θ+φ+λ,φ+λ,θ+φ+λ,φ+λ)的扩张部分重复码。
本发明提供的这种扩张部分重复码构造方法,能够根据存储环境变化动态调整参数,增加系统的存储容量,具有很好的实用价值。
附图说明
图1为mds码的编解码方式示意图。
图2为mds码的节点修复方式示意图。
图3为部分重复码的编码过程示意图。
图4为本发明的扩张部分重复码构造方法的流程示意图。
图5为本发明实施例的扩张部分重复码构造方法示意图。
具体实施方式
如图4为本发明的扩张部分重复码构造方法的流程示意图:本发明提供的这种扩张部分重复码构造方法,包括如下步骤:
s1.获取原数据文件;
s2.选择特定参数的可嵌入拟剩余设计;
s3.根据选择的可嵌入拟剩余设计的参数,对原数据文件进行mds编码;
s4.结合选择的可嵌入拟剩余设计,得到基础部分重复码;
s5.生成选择的可嵌入拟剩余设计对应的对称设计;
s6.通过生成的对称设计,得到扩张部分重复码。
步骤s2具体为,选择特定参数为2-(θ,φ,λ)的可嵌入拟剩余设计,其中θ为可嵌入拟剩余设计中点的个数,φ为区组的大小;同时,满足θ个点中任意两个点出现在λ个不同的区组中,并且λ(θ-1)=(φ-1)(φ+λ)。更进一步地,所选择的特定参数的可嵌入拟剩余设计总共包含θ(φ+λ)/φ个不同的区组,其中每个点出现在φ+λ个不同的区组中。
步骤s3具体为,将原数据文件划分成大小相同的m份,通过参数为(θ,m)的mds编码后,获得θ个编码块。
步骤s4具体为,将步骤s3中的θ个编码块与步骤s2中的可嵌入拟剩余设计的θ个点建立对应关系,并且将每个区组当作一个存储节点,得到一个参数为(θ(φ+λ)/φ,φ,θ,φ+λ)的基础部分重复码。
步骤s5具体为,根据步骤s2中选择的可嵌入拟剩余设计,增加若干点和区组,得到一个参数为2-(θ+φ+λ,φ+λ,λ)的对称设计,其中θ+φ+λ表示对称设计中点的个数,φ+λ表示区组的大小,满足θ+φ+λ个点中任意两个点出现在λ个不同的区组中。
增加若干点和区组具体为,在可嵌入拟剩余设计θ个点的基础上,新增φ+λ个不同的点并将这φ+λ点存入一个新的区组,同时在原拟剩余设计中的每个区组增加λ个新引入的点。
步骤s6具体为,将步骤s5中的对称设计的每个点当作一个编码块,每个区组当作一个存储节点,构造一个参数为(θ+φ+λ,φ+λ,θ+φ+λ,φ+λ)的扩张部分重复码。
在具体实施方式中,一个参数为(n,α,θ,ρ)的部分重复码c=(ω,φ),是指特定的n个子集集合φ={v1,v2,…,vn},其中每个子集中的元素均来自于符号集ω={1,2,…,θ},并且满足每个子集均包含α个元素,同时ω中的每个元素属于φ中ρ个不同的子集。此外,参数n,α,θ,ρ之间满足如下数值关系:nα=θρ。
一个参数为(n,α,θ,ρ)的部分重复码c=(ω,φ)可以将θ个不同的编码块复制ρ倍后存储到一个包含n个节点的存储系统中,其中每个节点存储α个编码块。具体来说,每个编码块对应ω中的一个元素,每个存储节点对应集合φ中的一个子集,该节点存储子集中的元素所对应的编码块。由于每个子集包含α个元素,所以每个节点存储α个编码块;由于每个元素属于ρ个不同的子集,因此每个编码块的复制倍数为ρ。上述θ个编码块由一个mds编码生成,即原数据文件通过mds编码后生成θ个编码块。
更进一步地,一个参数为(n,α,θ,ρ)的部分重复码的存储容量,是指系统n个节点中任意k个所能解码出的数据大小,其中参数k称为文件重构度。由于系统存储的编码块是由mds编码得到的,因此根据mds特性,任意k个节点包含的不同编码块个数,即为系统的存储容量。
给定一个参数为(n’,α’,θ’,ρ’)的部分重复码c’=(ω’,φ’),如果存在一个参数为(n,α,θ,ρ)的部分重复码c=(ω,φ),并满足以下条件
(1)
(2)对集合φ’中的任意一个子集v’,集合φ中都存在唯一的子集v,使得
那么称c是c’的扩张。为方便起见,称c’为基础部分重复码,c为扩张部分重复码。如果一个部分重复码存在扩张,那么则称它为可扩张的。
在上述实施例中,通过在可嵌入拟剩余设计的每个区组增加若干点,同时增加一个新的区组,可以得到一个对称设计。对于上述拟剩余设计的每个区组b’,对称设计中都存在唯一的区组b,其中b包含了b’中的所有的点。
一个参数为2-(θ,φ,λ)的可嵌入拟剩余设计总共包含θ(φ+λ)/φ个不同的区组,其中每个点出现在φ+λ个不同的区组中。同时,一个参数为2-(θ+φ+λ,φ+λ,λ)的对称设计包含θ+φ+λ个不同的区组,其中每个点出现在φ+λ个不同的区组中。
通过将上述组合设计中的点集看作符号集ω,区组集看作是节点集φ,因而可以得到一个部分重复码c=(ω,φ)。具体来说,一个参数为2-(θ,φ,λ)的可嵌入拟剩余设计可以构造一个参数为(θ(φ+λ)/φ,φ,θ,φ+λ)的部分重复码,而一个参数为2-(θ+φ+λ,φ+λ,λ)的对称设计可以构造一个参数为(θ+φ+λ,φ+λ,θ+φ+λ,φ+λ)的部分重复码。如果将上述可嵌入拟剩余设计构造出的码字称为基础部分重复码,结合可嵌入拟剩余设计和对称设计之间的关系,那么上述对称设计构造出的码字即为扩张部分重复码。
如图5为本发明实施例的扩张部分重复码构造方法示意图。在本实施例中,给出一个参数为2-(6,3,2)的可嵌入拟剩余设计和对应的码字构造实施例,具体说明如下:
步骤1):现取一个参数为2-(6,3,2)的可嵌入拟剩余设计,该设计包含6个点,依次记为1,2,3,5,6,8,同时包含如下10个区组:{1,2,3},{1,2,6},{1,3,5},{1,5,8},{1,6,8},{2,3,8},{2,5,6},{2,5,8},{3,5,6},{3,6,8};
步骤2):取一个原文件等分为5个数据块,对其进行参数为(6,5)的mds编码,从而得到6个编码块;
步骤3):将步骤2)中的6个编码块与步骤1)中的可嵌入拟剩余设计的6个点一一对应,并且将每个区组当作一个存储节点,得到一个参数为(10,3,6,5)的基础部分重复码;
步骤4):增加5个新的点4,7,9,10,11,并将这5个点当作一个区组,同时从这5个点中分别选出2个,依次添加到步骤1)的10个区组中,得到如下11个新的区组:{1,2,3,7,10},{1,2,6,9,11},{1,3,4,5,9},{1,5,8,10,11},{1,4,6,7,8},{2,3,4,8,11},{2,4,5,6,10},{2,5,7,8,9},{3,5,6,7,11},{3,6,8,9,10},{4,7,9,10,11};根据定义,上述11个区组构成一个参数为2-(11,5,2)的对称设计;
步骤5):将步骤4)中对称设计的每个点当作一个编码块,将每个区组当作一个存储节点,进而得到一个参数为(11,5,11,5)的扩张部分重复码。
通过上述构造方法,可以得到如图5中的基础部分重复码和扩张部分重复码,其中,ni表示存储节点,
上述可嵌入拟剩余设计构造的基础部分重复码,其每个节点存储的数据均唯一地包含在对称设计构造的扩张部分重复码的一个节点中,因此,上述可嵌入拟剩余设计构造的部分重复码是可扩张的。
- 还没有人留言评论。精彩留言会获得点赞!