数据检索方法和装置与流程
1.本发明涉及计算机技术领域,具体而言,涉及一种数据检索方法和装置。
背景技术:
2.目前,现有的标签检索系统通常会遍历标签查询条件中的所有标签,查询出每个标签符合条件的标签数据,然后根据标签组合逻辑再将上述所有筛选出来的标签数据进行内存处理,最后再结果输出。但是,在金融领域中,由于标签查询条件中标签数量较多,而且满足单个条件的数据量较大,采用上述方案进行数据检索,将增加服务层和存储层之间数据传输、网络消耗,增加数据传输,同时加大了存储集群自身内存、cpu消耗,导致整体标签数据处理速度减慢。
3.针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
4.本发明实施例提供了一种数据检索方法和装置,以至少解决相关技术中数据检索效率较低的技术问题。
5.根据本发明实施例的一个方面,提供了一种数据检索方法,包括:获取多个目标标签,以及每个目标标签对应的目标筛选条件;将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件;基于标签查询条件进行查询,得到查询结果。
6.可选地,将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件的步骤包括:响应于接收到的组合操作指令,将多个目标标签进行组合得到标签组合;基于标签组合和目标筛选条件,构造标签查询条件,其中,标签查询条件包括:表达式和过滤器,表达式用于表征多个目标标签之间的逻辑关系,过滤器用于表征目标筛选条件。
7.可选地,基于标签查询条件进行查询,得到查询结果的步骤包括:确定多个目标标签对应的目标存储集群;将标签查询条件转换为目标存储集群对应的目标查询语句;利用目标查询语句,在目标存储集群中查询得到查询结果。
8.可选地,通过逆波兰表达式将标签查询条件转换为目标查询语句。
9.可选地,通过逆波兰表达式将标签查询条件转换为目标查询语句的步骤包括:对标签查询条件进行预处理,生成表达式链表;将表达式链表转换为逆波兰表达式;将逆波兰表达式转换为目标查询语句。
10.可选地,对标签查询条件进行预处理,生成表达式链表的步骤包括:初始化操作符队列、操作数队列和表达式链表,其中,操作符队列用于存储标签查询条件中的操作符,操作数队列用于存储标签查询条件中的操作数,表达式链表用于存储处理后的操作符和操作数;遍历标签查询条件包含的表达式,并基于当前遍历到的目标字符,对操作符队列、操作数队列和/或表达式链表进行处理。
11.可选地,将表达式链表转换为逆波兰表达式的步骤包括:初始化操作符栈和操作
值栈;遍历表达式链表,并基于当前遍历到的表达式链表中的元素,对操作符栈和/或操作值栈进行处理;在表达式链表遍历结束之后,将操作符栈中的所有操作符存储至操作值栈。
12.可选地,将逆波兰表达式转换为目标查询语句的步骤包括:初始化操作栈和过滤器映射表;遍历逆波兰表达式,基于当前遍历到的逆波兰表达式中的目标元素构造查询生成器对象,并对操作栈和/或过滤器映射表进行处理;在逆波兰表达式遍历结束之后,获取操作栈中存储的查询生成器对象,生成目标查询语句。
13.可选地,在目标存储集群包括:第一存储集群和第二存储集群的情况下,利用目标查询语句,在目标存储集群中查询得到查询结果的步骤包括:利用第一存储集群对应的第一查询语句,在第一存储集群中查询得到第一结果;利用第二存储集群对应的第二查询语句,在第二存储集群中查询得到第二结果;将第一结果和第二结果进行聚合,得到查询结果。
14.可选地,该方法还包括:获取用户数据和标签定义,其中,标签定义包括:数据源、数据加工逻辑和加工时间间隔;利用数据加工逻辑对用户数据进行处理,得到标签数据;基于加工时间间隔,将标签数据存储至数据源。
15.可选地,将标签数据存储至数据源的步骤包括:在数据源为第一存储集群的情况下,按照不同标签将标签数据存储至第一存储集群中的不同字段内;在数据源为第二存储集群的情况下,按照不同标签将标签数据存储至第二存储集群中的不同列内。
16.可选地,该方法还包括:基于查询结果,生成对象列表;推送目标信息至对象列表中的对象。
17.根据本发明实施例的另一方面,还提供了一种数据检索装置,包括:获取模块,用于获取多个目标标签,以及每个目标标签对应的目标筛选条件;组合模块,用于将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件;查询模块,用于基于标签查询条件进行查询,得到查询结果。
18.可选地,组合模块包括:组合单元,用于响应于接收到的组合操作指令,将多个目标标签进行组合得到标签组合;构造单元,用于基于标签组合和目标筛选条件,构造标签查询条件,其中,标签查询条件包括:表达式和过滤器,表达式用于表征多个目标标签之间的逻辑关系,过滤器用于表征目标筛选条件。
19.可选地,查询模块包括:确定单元,用于确定多个目标标签对应的目标存储集群;转换单元,用于将标签查询条件转换为目标存储集群对应的目标查询语句;查询单元,用于利用目标查询语句,在目标存储集群中查询得到查询结果。
20.可选地,转换单元还用于通过逆波兰表达式将标签查询条件转换为目标查询语句。
21.可选地,转换单元还用于对标签查询条件进行预处理,生成表达式链表,将表达式链表转换为逆波兰表达式,并将逆波兰表达式转换为目标查询语句。
22.可选地,转换单元还用于,初始化操作符队列、操作数队列和表达式链表,遍历标签查询条件包含的表达式,并基于当前遍历到的目标字符,对操作符队列、操作数队列和/或表达式链表进行处理,其中,操作符队列用于存储标签查询条件中的操作符,操作数队列用于存储标签查询条件中的操作数,表达式链表用于存储处理后的操作符和操作数。
23.可选地,转换单元还用于初始化操作符栈和操作值栈,遍历表达式链表,并基于当
前遍历到的表达式链表中的元素,对操作符栈和/或操作值栈进行处理,在表达式链表遍历结束之后,将操作符栈中的所有操作符存储至操作值栈。
24.可选地,转换单元还用于初始化操作栈和过滤器映射表,遍历逆波兰表达式,基于当前遍历到的逆波兰表达式中的目标元素构造查询生成器对象,并对操作栈和/或过滤器映射表进行处理,在逆波兰表达式遍历结束之后,获取操作栈中存储的查询生成器对象,生成目标查询语句。
25.可选地,在目标存储集群包括:第一存储集群和第二存储集群的情况下,查询单元还用于利用第一存储集群对应的第一查询语句,在第一存储集群中查询得到第一结果,利用第二存储集群对应的第二查询语句,在第二存储集群中查询得到第二结果,并将第一结果和第二结果进行聚合,得到查询结果。
26.可选地,该装置还包括:获取模块还用于获取用户数据和标签定义,其中,标签定义包括:数据源、数据加工逻辑和加工时间间隔;处理模块,用于利用数据加工逻辑对用户数据进行处理,得到标签数据;存储模块,用于基于加工时间间隔,将标签数据存储至数据源。
27.可选地,存储模块还用于在数据源为第一存储集群的情况下,按照不同标签将标签数据存储至第一存储集群中的不同字段内;在数据源为第二存储集群的情况下,按照不同标签将标签数据存储至第二存储集群中的不同列内。
28.可选地,该装置还包括:生成模块,用于基于查询结果,生成对象列表;推送模块,用于推送目标信息至对象列表中的对象。
29.根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,计算机可读存储介质包括存储的程序,其中,在程序运行时控制计算机可读存储介质所在设备执行上述实施例中的数据检索方法。
30.根据本发明实施例的另一方面,还提供了一种电子设备,包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器运行的程序,程序被至少一个处理器运行时执行上述实施例中的数据检索方法。
31.在本发明实施例中,在获取到多个目标标签以及每个目标标签对应的目标筛选条件之后,可以将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件,进一步基于标签查询条件进行查询,得到查询结果。容易注意到的是,数据查询所使用的标签查询条件是多个目标标签的组合结果,而不是单一目标标签,使得服务层和存储层之间传输的标签数量降低,而且加载到服务层内存进行计算的数据量降低,达到了提高数据检索效率的技术效果,进而解决了相关技术中数据检索效率较低的技术问题。
附图说明
32.此处所说明的附图用来提供对本发明的进一步理解,构成本技术的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
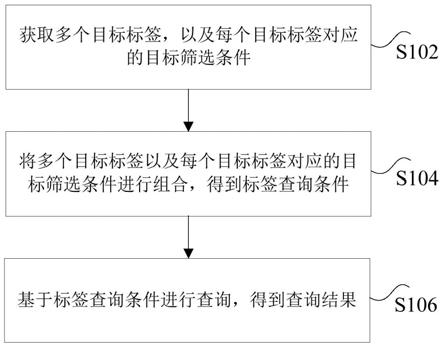
33.图1是根据本发明实施例的一种数据检索方法的流程图;
34.图2是根据本发明实施例的一种可选的标签组合的两种数据结构的示意图;
35.图3是根据本发明实施例的一种可选的逆波兰表达式转换query dsl的流程图;
36.图4是根据本发明实施例的一种可选的逆波兰表达式转换sql的流程图;
37.图5是根据本发明实施例的一种可选的elasticsearch中每个字段的示意图;
38.图6是根据本发明实施例的一种可选的数据检索方法的流程图;
39.图7是根据本发明实施例的一种可选的数据检索方法应用于金融信贷场景的流程图;
40.图8是根据本发明实施例的一种可选的elasticsearch中标签存储格式的示意图;
41.图9是根据本发明实施例的一种可选的标签检索条件的示意图;
42.图10是根据本发明实施例的一种数据检索装置的示意图。
具体实施方式
43.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
44.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
45.首先,对本发明实施例中出现的技术名称或技术术语进行如下解释说明:
46.标签:可以是用户属性数据,例如姓名、年龄、性别等。
47.逆波兰表达式:可以是指运算符运于运算对象之后的表达方式。
48.队列:是一种先进先出的数据结构,可以在队首删除,队尾增加。
49.链表:是一种物理存储单元上非连续、非顺序的存储结构,由一系列的节点组成。
50.栈:是一种在一端进行插入和删除操作的特殊线性表。
51.根据本发明实施例,提供了一种数据检索方法,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
52.图1是根据本发明实施例的一种数据检索方法的流程图,如图1所示,该方法包括如下步骤:
53.步骤s102,获取多个目标标签,以及每个目标标签对应的目标筛选条件。
54.上述步骤中的目标标签可以是需要进行数据检索的标签,由用户自行输入,例如,以金融信贷场景为例,目标标签可以是信贷流失环节标签、信贷流失时间标签等,但不仅限于此。
55.上述步骤中的目标筛选条件可以是为了实现数据检索对数据进行筛选的条件,由用户自行输入,例如,仍以金融信贷场景为例,对于信贷流失环节标签,目标筛选条件可以是该标签的取值为某个值;对于信贷流失时间标签,目标筛选条件可以是该标签的取值小
于等于某个时间戳。
56.在一种可选的实施例中,为了方便用户进行数据检索,可以给用户提供一个交互界面,用户可以在该交互界面上输入多个目标标签,并针对每个目标标签输入相应的目标筛选条件;或者,可以在该交互界面中提供数据库中已经存储的所有标签,由用户进行选择,用户选中的标签为目标标签,进而针对每个目标标签由用户输入相应的目标筛选条件。在此基础上,系统可以获取到上述多个目标标签,以及每个目标标签对应的目标筛选条件。
57.步骤s104,将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件。
58.例如,仍以金融信贷场景为例,标签数据的存储引擎可以是elasticsearch和greenplum,存储引擎中存储的数据量较大,在千万级左右,而且目标标签的数量较多。为了提高数据检索效率,在一种可选的实施例中,在获取到多个目标标签以及每个目标标签对应的目标筛选条件之后,可以将目标标签及目标筛选条件进行逻辑组合,得到标签查询条件,也即,通过“与”、“或”、“非”等逻辑关系将不同目标标签和目标筛选条件进行组合,得到标签组合。
59.步骤s106,基于标签查询条件进行查询,得到查询结果。
60.在一种可选的实施例中,在得到标签查询条件之后,可以将标签查询条件整体转换为查询语句,将查询语句提交到存储引擎中进行查询,存储引擎输出的结果即为最终的查询结果,无需进行额外处理。
61.通过上述步骤,在获取到多个目标标签以及每个目标标签对应的目标筛选条件之后,可以将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件,进一步基于标签查询条件进行查询,得到查询结果。容易注意到的是,数据查询所使用的标签查询条件是多个目标标签的组合结果,而不是单一目标标签,使得服务层和存储层之间传输的标签数量降低,而且加载到服务层内存进行计算的数据量降低,达到了提高数据检索效率的技术效果,进而解决了相关技术中数据检索效率较低的技术问题。
62.可选地,将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件的步骤包括:响应于接收到的组合操作指令,将多个目标标签进行组合得到标签组合;基于标签组合和目标筛选条件,构造标签查询条件,其中,标签查询条件包括:表达式和过滤器,表达式用于表征多个目标标签之间的逻辑关系,过滤器用于表征目标筛选条件。
63.在一种可选的实施例中,用户可以通过交互界面进行操作,将多个目标标签进行组合,然后调用标签筛选结果接口进行标签筛选;后端接收传输的标签组合,将其构造成如图2所示的两种数据结构,分别是表达式和过滤器,表达式由不同逻辑符将多个目标标签连接,过滤器包含每个目标标签对应的目标筛选条件,其中,s标识标签,s后面的数字标识标签个数,&&表示且,||表示或,!表示非,code表示标签码,type表示标签类型(如字符串string、数字number、布尔boolean等),operator表示操作符(如等于eq、小于lt、小于等于lte、大于gt、大于等于gte、不等于neq等)。
64.可选地,基于标签查询条件进行查询,得到查询结果的步骤包括:确定多个目标标签对应的目标存储集群;将标签查询条件转换为目标存储集群对应的目标查询语句;利用目标查询语句,在目标存储集群中查询得到查询结果。
65.在本发明实施例中,需要查询的数据可以存储在多个不同类型的存储集群中,不同存储集群中能够存储的标签的类型不同,而且不同存储集群使用的查询语句不同,例如,仍以金融信贷场景为例,存储集群可以包括elasticsearch和greenplum,elasticsearch支持标签的类型包括:date、string、number、bool,目标筛选条件支持==、《、》、《=、》=、in、between,使用的查询语句为query dsl;greenplum支持标签的类型包括:date、varchar、int、tinyint、bigint,目标筛选条件支持==、《、》、《=、》=、in、between,使用的查询语句为sql(structured query language,结构化查询语言)。
66.在一种可选的实施例中,可以根据用户输入的目标标签,确定相应的数据所存储的存储集群,得到目标存储集群,进而将标签查询条件转换为相应的目标查询语句,并提交到目标存储集群进行检索,当目标存储集群是elasticsearch时,可以将标签查询条件转换为query dsl,构造resthighlevelclient对象,通过该对象提交es请求,使用resthighlevelclient.scroll()方法分页获取查询结果,将返回结果进行标准输出;当目标存储集群是greenplum时,可以将标签查询条件转换为sql,构造greenplumclient对象,通过该对象将sql提交greenplum集群,将返回结果进行标准输出。
67.可选地,通过逆波兰表达式将标签查询条件转换为目标查询语句。
68.在一种可选的实施例中,为了方便标签查询条件转换为适用于不同存储集群的查询语句,可以首先将标签查询条件转换为逆波兰表达式,然后通过逆波兰表达式转换为目标查询语句。
69.可选地,通过逆波兰表达式将标签查询条件转换为目标查询语句的步骤包括:对标签查询条件进行预处理,生成表达式链表;将表达式链表转换为逆波兰表达式;将逆波兰表达式转换为目标查询语句。
70.在一种可选的实施例中,对于elasticsearch,目标查询语句的转换过程如图3所示,首先可以对标签查询条件进行预处理,去除空格,并将操作符和操作数重组,生成表达式链表,然后将表达式链表转换为逆波兰表达式reversestack,最后将逆波兰表达式opvaluestack转换为es查询语句query builder。对于greenplum,目标查询语句的转换过程如图4所示,首先将标签查询条件转换为where表达式,拼接where表达式生成greenplum查询语句。
71.可选地,对标签查询条件进行预处理,生成表达式链表的步骤包括:初始化操作符队列、操作数队列和表达式链表,其中,操作符队列用于存储标签查询条件中的操作符,操作数队列用于存储标签查询条件中的操作数,表达式链表用于存储处理后的操作符和操作数;遍历标签查询条件包含的表达式,并基于当前遍历到的目标字符,对操作符队列、操作数队列和/或表达式链表进行处理。
72.在一种可选的实施例中,首先初始化操作符队列curoptag(存放当前操作符)、操作数队列curopvalue(存放当前操作数)、表达式expression链表(按顺序存放经过处理的操作数和操作符);从左到右依次扫描标签查询条件包含的表达式字符串。
73.其中,遇到空格,直接跳过。
74.遇到操作符,判断curopvalue中是否存在数据,若存在,将curopvalue数据加入exression链表,清空curopvalue;判断当前操作符是否为&、|,若相等,则当前操作符加入curoptag,否则,抛异常。
75.遇到
‘
(’字符,判断curopvalue中是否存在数据,若存在,则抛异常(左括号中左侧不应该存在操作数);判断curoptag中是否存在数据,若存在,则将curoptag数据加入exression链表,清空curopta。
76.遇到
‘
)’字符,判断curoptag中是否存在数据,若存在,则抛异常(右括号中左侧不应该存在操作符);判断curopvalue中是否存在数据,若存在,则将curopvalue数据加入exression链表,清空curopvalue。
77.遇到
‘
s’字符,判断curoptag中是否存在数据,若存在,则将curoptag数据加入exression链表,清空curoptag。
78.遇到
‘
0-9’字符,判断curopvalue中是否存在数据,若不存在,则抛异常;若存在,则将curopvalue数据加入exression链表,清空curopvalue。
79.可选地,将表达式链表转换为逆波兰表达式的步骤包括:初始化操作符栈和操作值栈;遍历表达式链表,并基于当前遍历到的表达式链表中的元素,对操作符栈和/或操作值栈进行处理;在表达式链表遍历结束之后,将操作符栈中的所有操作符存储至操作值栈。
80.在一种可选的实施例中,首先初始化操作符栈optagstack和操作值栈opvaluestack,然后从左到右依次扫描expression链表(中缀表达式)。
81.遇到操作数,将操作数直接入栈到opvaluestack。
82.遇到操作符
‘
(’,将操作符直接入栈optagstack。
83.遇到操作符为运算符(&&、||、!),先判断optagstack栈顶元素,若栈顶元素为空或者栈顶元素操作符优先级大于当前操作符优先级,则直接将操作符入栈optagstack;否则将栈顶元素出栈,并入栈到操作数栈opvaluestack。
84.遇到操作符
‘
)’,将操作符栈循环出栈,并入栈到操作数栈opvaluestack,直到遇见
‘
(’操作符。
85.遍历expresion链表结束后,将optagstack剩余操作符依次出栈,并入栈到opvaluestack。
86.可选地,将逆波兰表达式转换为目标查询语句的步骤包括:初始化操作栈和过滤器映射表;遍历逆波兰表达式,基于当前遍历到的逆波兰表达式中的目标元素构造查询生成器对象,并对操作栈和/或过滤器映射表进行处理;在逆波兰表达式遍历结束之后,获取操作栈中存储的查询生成器对象,生成目标查询语句。
87.在一种可选的实施例中,首先初始化stack《querybuilder》为操作栈opstack,includefilter转换为过滤器映射表filtermap(key为操作数,value为操作数对应的筛选条件(可转换为map)),然后遍历逆波兰表达式opvaluestack。
88.遇到操作数(标签code:s1),获取filtermap中对应key值的筛选条件;根据筛选条件,获取标签code、标签type、标签value、标签筛选操作符operator;判断标签type:
89.若为date,构造rangequerybuilder对象rangebuilder;将value拆分为start时间戳和end时间戳,操作符operator转换为gte和lte,使用rangebuilder.gte(start)和rangebuilder.lte(end)方法获取querybuilder对象。
90.若为string,构造termquerybuilder对象termbuilder;若筛选操作operator为in,则value拆分为数组,使用querybuilders.termsquery(code,values)方法获取querybuilder对象。
91.若为number,构造querybuilder对象querybuilder;若筛选操作operator为《、》、《=、》=,value转换为数字,并使用querybuilders.rangequery().lt()、querybuilders.rangequery().gt()、querybuilders.rangequery().lte()、querybuilders.rangequery().gte()方法获取querybuilder对象;若筛选操作operator为==,使用querybuilders.termquery()方法获取querybuilder对象。
92.若为bool,构造termquerybuilder对象termbuilder,使用querybuilders.termsquery(code,values)方法将标签value转换为字符串,获取querybuilder对象。
93.将querybuilder对象入栈opstack。
94.遇到操作符,初始化querybuilder对象,判断操作符:
95.若为&&,opstack出栈两次,获取leftquerybuilder和rightquerybuilder;querybuilder构造为boolquerybuilder对象,使用querybuilder.filter().add(leftquerybuilder),querybuilder.filter().add(rightquerybuilder)方法添加不同筛选条件。将querybuilder入栈opstack。
96.若为!,opstack出栈两次,获取rightquerybuilder和leftquerybuilder;querybuilder构造为boolquerybuilder对象,使用querybuilder.filter().add(leftquerybuilder),querybuilder.mustnot().add(rightquerybuilder)方法添加不同筛选条件。将querybuilder入栈opstack。
97.若为||,opstack出栈两次,获取rightquerybuilder和leftquerybuilder;querybuilder构造为boolquerybuilder对象,使用querybuilder.should().add(leftquerybuilder),querybuilder.should().add(rightquerybuilder),querybuilder.minimumshouldmatch(leftquerybuilder)方法添加不同筛选条件。将querybuilder入栈opstack。
98.以上遍历结束之后,opstack里面只有一个querybuilder对象,为最终构造的querybuilder对象。
99.可选地,在目标存储集群包括:第一存储集群和第二存储集群的情况下,利用目标查询语句,在目标存储集群中查询得到查询结果的步骤包括:利用第一存储集群对应的第一查询语句,在第一存储集群中查询得到第一结果;利用第二存储集群对应的第二查询语句,在第二存储集群中查询得到第二结果;将第一结果和第二结果进行聚合,得到查询结果。
100.不同类型的标签可以存储于不同的存储集群,同一个类型的标签也可以存储于不同的存储集群,例如,对于date类型的标签,可以存储于elasticsearch和greenplum中。因此,上述的第一存储集群可以是elasticsearch,第一查询语句可以是query dsl;第二存储集群可以是greenplum,第二查询语句可以是sql。
101.在一种可选的实施例中,可以将第一查询语句向第一存储集群提交检索任务,并将返回结果进行标准数据,将第二查询语句向第一存储集群提交检索任务,并将返回结果进行标准数据,最后将两个存储集群的筛选结果进行聚合,得到最终的查询结果。
102.可选地,该方法还包括:获取用户数据和标签定义,其中,标签定义包括:数据源、数据加工逻辑和加工时间间隔;利用数据加工逻辑对用户数据进行处理,得到标签数据;基
于加工时间间隔,将标签数据存储至数据源。
103.在一种可选的实施例中,业务人员可以将标签定义以及加工逻辑输入到系统中,标签定义包含数据源、数据加工逻辑、加工时间间隔(天级、小时级、秒级),定时任务捞取标签定义,产出标签对应值(不同用户标签值不同),并根据数据源以及加工时间间隔存入elasticsearch、greenplum中(小时级和秒级存入elasticsearch、天级存入greenplum)。
104.可选地,将标签数据存储至数据源的步骤包括:在数据源为第一存储集群的情况下,按照不同标签将标签数据存储至第一存储集群中的不同字段内;在数据源为第二存储集群的情况下,按照不同标签将标签数据存储至第二存储集群中的不同列内。
105.例如,仍以金融信贷场景为例,第一存储集群可以是elasticsearch,第二存储集群可以是greenplum。其中,elasticsearch为单索引存储,每个字段(即mapping中每个映射)代表一个标签,其中,字段名为标签code,字段值为标签value,如图5所示。greenplum为宽表存储,每个标签对应宽表一列。
106.可选地,该方法还包括:基于查询结果,生成对象列表;推送目标信息至对象列表中的对象。
107.上述步骤中的对象列表可以是用户列表,目标信息可以是根据实际业务配置的经营活动,例如,仍以金融信贷场景为例,目标信息可以是营销短信、优惠卷、召回电话等。
108.在一种可选的实施例中,在查询到符合标签查询条件的查询结果之后,可以根据查询结果确定符合要求的用户列表,然后根据业务同学配置的经营活动,进行信贷类用户经营。例:标签筛选为半小时内流失用户,经营活动便为流失用户的相关召回。
109.下面结合图6至图9以金融信贷场景为例,对本发明一种优选的实施例进行详细说明。如图6所示,该方法主要分为:标签加工、标签检索和信贷应用三个部分,该方法的具体流程如下:
110.步骤s601,业务创建标签定义,其中,标签定义包含数据源、数据加工逻辑、加工时间间隔(天级、小时级、秒级)。
111.步骤s602,标签数据跑批入elasticsearch和greenplum,系统跑批任务根据标签定义、数据源、加工逻辑将用户的标签数据产出,获取到该标签当前时间点的数值,并按照数量、加工时间间隔等存入不同存储集群中。
112.上述步骤s601至步骤s602为标签加工部分。
113.步骤s603,调用方输入多个目标标签,组合标签查询条件。
114.步骤s604,标签查询条件预处理,去除空格,并将操作符和操作数重组。
115.步骤s605,标签查询条件转换为逆波兰表达式。
116.步骤s606,存储集群分类,将逆波兰表达式转换为查询语句,并查询存储集群,其中,对于greenplum,将逆波兰表达式转换为greenplum查询语句,并查询greenplum;对于mysql,将逆波兰表达式转换为mysql查询语句,并查询mysql;对于elasticsearch,将逆波兰表达式转换为elasticsearch查询语句,并查询elasticsearch。
117.步骤s607,将全部结果进行聚合,得到查询结果。
118.上述步骤s603至步骤s607为标签查询部分。
119.步骤s608,调用方获取用户列表,并将查询结果用于流失召回或信贷经营。
120.上述步骤s608为信贷应用部分。
121.下面结合图7至图9以信贷流失环节标签、信贷流失时间标签为例,简要阐述流失相关标签加工、存储、检索、数据产出整体流程。
122.信贷流失环节标签即信贷用户截止到当前时间访问应用程序的最新位置,信贷流失时间标签即信贷用户在信贷流失环节值修改时对应的时间值。每个信贷用户均存在一个信贷流失环节标签和一个信贷流失时间标签。
123.如图7所示,标签加工流程如下:
124.流失环节和流失时间值通过监听场景端信贷用户埋点日志kafka获取。kafka监听器拉取到一条场景端埋点日志时,会进行埋点日志筛选,判断埋点日志格式、埋点页面key值等是否符合要求,并将符合要求的埋点更新到es中对应文档的流失环节、流失时间字段。
125.elasticsearch中标签存储格式如图8所示。其中,一个文档代表一个信贷用户,文档下对应的一个映射字段代表一个用户标签,文档id代表用户id值,loss_step代表流失环节标签,loss_step对应标签值即当前用户id在应用程序的最新位置(即页面key值),loss_time代表流失时间标签,loss_time对应标签值即当前用户id对应的流失时间值。
126.标签检索流程如下:
127.流失环节标签和流失时间标签一般联合使用,调用方会将两种标签值进行条件组合成系统需要的入参,并将入参传入标签筛选系统中。其中,入参具体格式如图9所示,其代表含义为:查询流失环节标签值为key1且流失时间小于等于时间戳为1627873865的所有用户id列表。
128.系统接收到入参请求后,会先将expression和includefilter转换成逆波兰表达式,然后根据逆波兰表达式转换成对应的es query dsl语句。生成resthighlevelclient对象,并将es query dsl语句提交到es集群中获取查询结果。
129.查询结果产出流程如下:
130.系统获取到查询结果文档列表时,会将查询结果文档列表中的id字段单独筛选出来汇总成用户id列表,然后将用户id列表异步回传给调用方。
131.根据本发明实施例,还提供了一种数据检索装置,该装置可以执行上述实施例中的数据检索方法,具体实现方案和应用场景与上述实施例相同,在此不做赘述。
132.图10是根据本发明实施例的一种数据检索装置的示意图,如图10所示,该装置法包括:
133.获取模块102,用于获取多个目标标签,以及每个目标标签对应的目标筛选条件。
134.组合模块104,用于将多个目标标签以及每个目标标签对应的目标筛选条件进行组合,得到标签查询条件。
135.查询模块106,用于基于标签查询条件进行查询,得到查询结果。
136.可选地,组合模块包括:组合单元,用于响应于接收到的组合操作指令,将多个目标标签进行组合得到标签组合;构造单元,用于基于标签组合和目标筛选条件,构造标签查询条件,其中,标签查询条件包括:表达式和过滤器,表达式用于表征多个目标标签之间的逻辑关系,过滤器用于表征目标筛选条件。
137.可选地,查询模块包括:确定单元,用于确定多个目标标签对应的目标存储集群;转换单元,用于将标签查询条件转换为目标存储集群对应的目标查询语句;查询单元,用于利用目标查询语句,在目标存储集群中查询得到查询结果。
138.可选地,转换单元还用于通过逆波兰表达式将标签查询条件转换为目标查询语句。
139.可选地,转换单元还用于对标签查询条件进行预处理,生成表达式链表,将表达式链表转换为逆波兰表达式,并将逆波兰表达式转换为目标查询语句。
140.可选地,转换单元还用于,初始化操作符队列、操作数队列和表达式链表,遍历标签查询条件包含的表达式,并基于当前遍历到的目标字符,对操作符队列、操作数队列和/或表达式链表进行处理,其中,操作符队列用于存储标签查询条件中的操作符,操作数队列用于存储标签查询条件中的操作数,表达式链表用于存储处理后的操作符和操作数。
141.可选地,转换单元还用于初始化操作符栈和操作值栈,遍历表达式链表,并基于当前遍历到的表达式链表中的元素,对操作符栈和/或操作值栈进行处理,在表达式链表遍历结束之后,将操作符栈中的所有操作符存储至操作值栈。
142.可选地,转换单元还用于初始化操作栈和过滤器映射表,遍历逆波兰表达式,基于当前遍历到的逆波兰表达式中的目标元素构造查询生成器对象,并对操作栈和/或过滤器映射表进行处理,在逆波兰表达式遍历结束之后,获取操作栈中存储的查询生成器对象,生成目标查询语句。
143.可选地,在目标存储集群包括:第一存储集群和第二存储集群的情况下,查询单元还用于利用第一存储集群对应的第一查询语句,在第一存储集群中查询得到第一结果,利用第二存储集群对应的第二查询语句,在第二存储集群中查询得到第二结果,并将第一结果和第二结果进行聚合,得到查询结果。
144.可选地,该装置还包括:获取模块还用于获取用户数据和标签定义,其中,标签定义包括:数据源、数据加工逻辑和加工时间间隔;处理模块,用于利用数据加工逻辑对用户数据进行处理,得到标签数据;存储模块,用于基于加工时间间隔,将标签数据存储至数据源。
145.可选地,存储模块还用于在数据源为第一存储集群的情况下,按照不同标签将标签数据存储至第一存储集群中的不同字段内;在数据源为第二存储集群的情况下,按照不同标签将标签数据存储至第二存储集群中的不同列内。
146.可选地,该装置还包括:生成模块,用于基于查询结果,生成对象列表;推送模块,用于推送目标信息至对象列表中的对象。
147.根据本发明实施例,还提供了一种计算机可读存储介质,计算机可读存储介质包括存储的程序,其中,在程序运行时控制计算机可读存储介质所在设备执行上述实施例中的数据检索方法。
148.根据本发明实施例,还提供了一种电子设备,包括:至少一个处理器;以及与至少一个处理器通信连接的存储器;其中,存储器存储有可被至少一个处理器运行的程序,程序被至少一个处理器运行时执行上述实施例中的数据检索方法。
149.在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
150.在本技术所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或
者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
151.所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
152.另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
153.所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
154.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1