一种结合帧间光流的表观运动联合弱小运动目标检测方法
1.本发明涉及一种结合帧间光流的表观运动联合弱小运动目标检测方法,属于计算机视觉技术领域。
背景技术:
2.目标检测是计算机视觉领域的基本任务之一,其目的是找出图像或视频中的感兴趣物体。近年来,随着深度学习技术的发展,目标检测算法取得了突破,深度神经网络提取的特征能更好地适应目标外观、姿态等的变化,在光照、遮挡等因素影响下也能更加鲁棒地检测到目标。基于深度学习的视觉目标分析已经在人脸检测识别、可控环境下视频目标检测跟踪等任务上取得了较好的效果,在一些公开数据集上人车等目标检测识别已超过了人类的平均识别能力。例如,在labeled faces in the wild(lfw)数据集上人脸识别精度超过99.7%(参考《circle loss:a unified perspective of pairsimilarity optimization》,刊于《proc of ieee conference on computervision and pattern recognition》,2020年;《towards universalrepresentation learning for deep face recognition》,刊于《proc of ieeeconference on computer vision and pattern recognition》,2020年),在kitti数据库上小汽车类别的识别精度达到96.1%(参考《radhaclocs: camera-lidar object candidates fusion for 3d object detection》,刊于《ieee/rsj international conference on intelligent robots andsystems》,2020年)。
3.然而,在面对弱小目标检测时,现有深度学习方法依然面临较大的问题,由于深度学习网络框架中往往有池化、卷积步长的限制,最终的目标表观特征图相对于原图经过了多次下采样,很多表观信息已经丢失,面对弱小目标时这些丢失的表观信息极大影响了检测精度。针对弱小目标难以被检测的问题,现有效果最明显的方法之一是fpn网络(参考《feature pyramid networksfor object detection》,刊于《proceedings of the ieee conference oncomputer vision and pattern recognition》,2017年)中提出的多层特征融合。该方法将浅层特征与深层特征相融合,用浅层特征补充深层丢失的特征。但是对于浅层表观特征本身就已经较少的情况,该方法依然不能很好地解决弱小目标漏检的问题。
4.考虑到单纯利用目标表观信息无法很好地检测到弱小目标,结合运动特征的视频运动目标检测作为一类重要的应用也开展了广泛的研究。其中,现有基于深度神经网络的运动目标检测算法基本采用两步式方法,即首先基于单帧图像深度神经网络检测目标,再采用光流加阈值分割的方式获取视频帧中的运动区域,从而判断单帧图像检测到的目标是否运动。这样的分步式方法存在以下问题:在单帧目标检测的基础上再过滤非运动目标,进而得到运动目标,其结果受单帧检测的精度影响较大。一旦单帧目标检测算法不能准确地检测到所有目标,后续的运动判断也无从谈起。当前,单帧目标检测算法中针对弱小目标的漏检现象仍然非常严重,当目标表观信息缺失时,基于表观深度网络的单帧目标检测算法极易漏检弱小目标。以单帧目标检测为基础的分步式方法中,运动信息的使用并没有有效
提升运动目标的检测准确率。人类对于较小目标进行检测时,更多关注的是目标的运动特征,相比表观特征,运动使得我们更容易发现目标。运动特征的利用是视频目标检测与单帧目标检测的根本区别。现有分步式方法首先利用表观特征发现目标,在该阶段摒弃了帧间信息,减少了深度神经网络对外界信息的获取量,不利于提升目标检测的准确率。
5.为此,本技术提出了一种结合帧间光流的表观运动联合弱小运动目标检测方法。基于yolov3目标检测网络框架(参考《yolov3:an incrementalimprovement》,刊于《arxiv e-prints》,2018年),构建表观运动联合网络实现弱小运动目标的准确检测。具体地,将帧间光流场作为一种低层次运动特征,与单帧图像中的目标表观特征融合到神经网络中作为通道信息,以运动特征增强rgb图像特征,将运动特征、表观特征在一个统一网络框架内训练,结合两者的优势,最终准确检测到运动目标。这种一步式检测的应用模式相比分步式检测的应用模式,对运动小目标有更好的适应性。表观运动联合网络在目标较小、表观网络易漏检目标的情况下,利用弱小目标依然存在运动、甚至可能运动速度较快的特点,通过额外输入帧间光流进行表观和运动特征的联合训练,可以更好地检测到表观特征较少的弱小运动目标。
技术实现要素:
6.本发明的目的是提供一种结合帧间光流的表观运动联合弱小运动目标检测方法。该方法不仅可以通过运动特征补充表观特征、提升弱小目标的检测准确率,还可以利用表观特征和运动特征联合预测运动目标,将运动目标和静止目标区分开来。
7.为实现上述目的,本发明采用的技术方案流程如下:
8.一种结合帧间光流的表观运动联合弱小运动目标检测方法,包括如下步骤:
9.(1)累积光流计算:利用深度神经网络光流计算方法计算当前帧与前一帧之间的光流,得到当前帧每个像素点的光流,所述光流包含运动方向和运动大小;按照上述方法计算n个连续帧中每相邻两帧的光流,得到n-1个光流,将所述n-1个光流叠加,形成多帧累积光流;
10.(2)表观运动联合网络构建:在yolov3单帧目标检测网络的基础上,通过用darknet-53骨干网络提取特征,在不同尺度的yolo层进行目标检测的结构构建表观运动联合网络,将所述多帧累积光流中包含的水平、垂直方向的运动信息作为双通道信息,连同当前帧图像的rgb三通道像素值,经过预处理后一同作为所述表观运动联合网络的输入;在yolo层每一个预测边界框输出结果中增加运动目标置信度;并在yolov3单帧目标检测网络的五类损失之外,增加运动目标预测损失,从而改进损失函数;在训练过程中对所述表观运动联合网络进行约束,使所述表观运动联合网络在目标检测的基础上,进一步区分运动目标和静止目标。
11.如上所述的方法,其特征在于:所述步骤(1)中多帧累积光流的计算过程包括:针对n个连续帧,利用深度神经网络光流计算方法pwc-net计算出每相邻两帧间的光流,得到n-1个光流结果,将所述每相邻两帧的光流结果以矩阵形式表示,所述矩阵中每个元素表示每个像素点的光流结果;将所述n-1个光流结果进行叠加,形成所述多帧累积光流,以增强慢速小目标的运动信息,所述相邻两帧的光流结果记为(ui→
i+1
,vi→
i+1
),从第1帧到第n 帧的n-1帧累积光流s1→n由下述公式(1)计算得到,
[0012][0013]
如上所述的方法,其特征在于:所述步骤(2)中表观运动联合网络的具体构建过程为:
[0014]
(2.1)以yolov3单帧目标检测网络为基础,将输入的图像经过darknet-53骨干网络提取特征,在yolo层进行目标检测,并将该yolo层中特征图经过上采样层,与darknet-53后两层中相应尺度的特征图进行维度拼接,实现多层特征的融合,作为下一个yolo层提供数据;
[0015]
(2.2)使用多个yolo层进行不同尺度的目标检测,每个yolo层将输入的特征图进行若干次darknetconv2d_bn_leaky,即dbl操作,所述dbl操作是在一个卷积层后跟一个batch normalization层和一个leakyrelu层,得到输入到下一个yolo层的特征图,再进行1次darknetconv2d_bn_leaky 操作,并经过1
×
1卷积运算,输出对应的s
×s×b×
(c+(4+1))维度的张量,其中,s
×
s表示yolo层中划分的网格数量,b表示每一个网格上产生的边框个数,c表示网络支持识别的类别数;输出张量中包含每个预测边界框的所属类别概率、位置参数以及物体置信度,其中,所属类别概率表示在预测框存在目标的情况下,目标属于各个类别的对应概率,位置参数包括4个参数x、y、w、h,分别表示预测框的中心点相对网格的偏移量和相对于 s
×
s网格的宽、高,物体置信度表示预测框中存在目标的概率。
[0016]
如上所述的方法,其特征在于:所述步骤(2)中表观运动联合网络为了利用帧间运动特征来补充单帧表观特征,将多帧累积光流与当前帧图像的 rgb三通道像素值一同作为表观运动联合网络的输入的计算过程包括:将多帧累积光流和rgb三通道像素值经过预处理后,通过维度连接操作进行连接,作为表观运动联合网络的输入;所述多帧累积光流输入包含水平、垂直两个方向的运动信息,将yolov3单帧目标检测网络第一个卷积层中每一个卷积核的神经元权重参数从3个增加到5个,使得第一层的神经元能够使用新增的神经元权重参数在5个通道输入上计算得出第一层特征图,从而同时提取表观和运动特征;网络第一层特征f1可以用下述公式(2)表示,
[0017][0018]
其中表示预处理后的双通道多帧累积光流经过卷积操作的计算结果,表示rgb三通道像素值经过卷积操作的计算结果。
[0019]
如上所述的方法,其特征在于:所述步骤(2)中多帧累积光流和rgb 三通道像素值的预处理过程为:将多帧累积光流结果取绝对值,去除累积光流的方向信息,只使用累积光流的数值大小表示当前像素的运动快慢,从而减少表观运动联合网络训练过程中的噪声,加快收敛速度;同时,对所述rgb 三通道像素数据采用归一化处理,将数据范围限制在0到1之间,对所述多帧累积光流也采用归一化处理,使所述多帧累积光流的数据分布与表观特征的数据分布范围相同;对所述多帧累积光流采用如下述公式(3)进行归一化,
[0020][0021]
其中mean
|u|
表示u方向上累积光流绝对值的平均值,variance
|u|
表示u 方向上累积光流绝对值的标准差,mean
|v|
表示v方向上累积光流绝对值的平均值,variance
|v|
表示v
方向上累积光流绝对值的标准差。
[0022]
如上所述的方法,其特征在于:所述步骤(2)中表观运动联合网络为了区分运动目标和静止目标,在yolo层每一个预测边界框输出结果中增加运动目标置信度的具体过程包括:在yolov3单帧目标检测网络yolo层每一个预测边界框输出4个位置参数和1个物体置信度的基础上,增加1个运动目标置信度,该值是回归连续值,用来表示当前目标框中预测得到的目标是运动目标的置信度,其计算方式如公式(4)所示,
[0023]
output_dim=s
×s×b×
(c+(4+1+1))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0024]
其中output_dim表示yolo层输出的张量维度;表观运动联合网络将输入数据进行了yolov3中的编码操作,yolo层将该输出张量进行与输入时编码相应的解码操作得到最终输出结果。
[0025]
如上所述的方法,其特征在于:所述步骤(2)中表观运动联合网络在 yolov3单帧目标检测网络的五类损失之外,增加运动目标预测损失,该损失使用二分类交叉熵,具体计算如公式(5)所示,
[0026][0027]
其中loss表示yolov3单帧目标检测网络提出的损失函数,用来累计检测框位置损失和类别损失,求和符号中的s2表示yolo层中分割的网格数量,表示第i个网格的第j个预测边界框中是否存在目标,如果存在目标则为1,否则为0,mi(j)表示第i个网格的第j个预测边界框中预测得出的运动目标置信度,表示数据集中运动目标区域的真实标注,运动目标标注为1,静止目标标注为0,通过上述公式(5)在训练过程中对网络进行约束,令网络能够区分静止目标和运动目标;在测试时,根据网络输出的运动目标置信度判断该目标是否为运动目标,如果运动目标置信度大于th,则将其视为运动目标输出。
[0028]
如上所述的方法,其特征在于步骤(1)中多帧累积光流的累积帧数参数n,优选为n=3。
[0029]
如上所述的方法,其特征在于网络使用多个yolo层进行不同尺度的目标检测时,yolo层的数量优选为3个。
[0030]
如上所述的方法,其特征在于每个yolo层将输入的特征图进行若干次 darknetconv2d_bn_leaky时,若干次dbl操作优选为5次。
[0031]
如上所述的方法,其特征在于运动目标置信度阈值th,优选为th=0.5。
[0032]
与现有技术相比,本发明所提供的结合帧间光流的表观运动联合弱小运动目标检测方法,针对视频中弱小运动目标虽然表观特征少、但存在运动的特点,利用帧间运动信息对表观特征进行有效补充,从而提升弱小运动目标的检测准确率;针对光流运动矢量具有方向性、能描述运动大小的特点,利用取绝对值、归一化等操作对表观运动联合网络中新增加的多帧累积光流进行预处理,克服噪声干扰,提升深度神经网络中光流数据对模型的拟合能力;计算多帧累积光流,相比于两帧间光流能够更有效地突出慢速小目标的运动信息,当小目标存在运动甚至慢速运动时,可以有效地通过运动特征补充表观特征提升运动小目标的检测准确率;进一步针对运动目标检测任务,设计运动目标置信度和结合运动目标预测损失的损失函数,可以更加有效地利用表观和运动特征联合预测运动目标,将运动目标和静止目标准确区分开来,能较好地完成运动目标检测任务。
附图说明
[0033]
下面结合附图和具体实施方式对本发明作进一步的说明。
[0034]
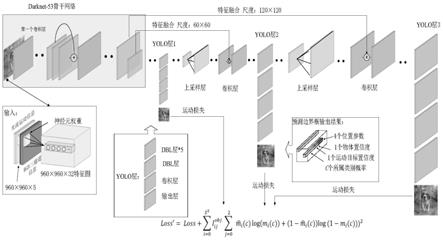
图1为结合帧间光流的表观运动联合网络框架图;
[0035]
图2为pwc-net网络结构。
具体实施方式
[0036]
前已述及,本发明提出一种结合帧间光流的表观运动联合弱小运动目标检测方法,下面结合附图说明本发明的具体实施方式。
[0037]
(1)整体流程
[0038]
本发明基于yolov3单帧目标检测网络来构建表观运动联合网络,如附图1所示。首先,将利用pwc-net计算得到的多帧光流累加作为累积光流,将累积光流作为低层次运动特征输入网络,作为表观特征的补充,结合单帧目标表观特征与视频目标的运动特征,提升弱小运动目标的检测准确率。具体实施方式分为两个部分:(1)多帧累积光流的计算;(2)表观运动联合网络的构建。
[0039]
首先,在当前帧图像中利用前面若干帧图像计算多帧累积光流:使用 pwc-net计算相邻两帧间的光流,再用视频中连续多个相邻帧计算出多帧光流,叠加得到多帧累积光流。
[0040]
然后,构建表观运动联合网络:在yolov3单帧目标检测算法的基础上构建表观运动联合网络。将多帧累积光流与rgb三通道数据一同输入表观运动联合网络,利用帧间运动特征弥补目标表观特征不足的缺陷,提高弱小运动小目标的检测准确率。同时,在yolo层每一个预测边界框输出结果中增加运动目标置信度,结合运动目标预测损失来改进损失函数,在训练过程中对网络进行约束,使网络可以在目标检测的基础上进一步区分运动目标和静止目标。
[0041]
(2)多帧累积光流场的计算
[0042]
使用pwc-net计算相邻两帧间的光流,再利用视频中连续多个相邻帧计算得到多帧光流,叠加这些光流得到多帧累积光流。
[0043]
(2.1)pwc-net计算相邻两帧光流
[0044]
pwc-net是nvidia在cvpr2018年论文中提出的光流预测网络,具有较快的运算速度以及较低的算力要求。如附图2所示,pwc-net主要由四部分结构组成,分别是金字塔特征提取器(pyramid feature extractor)、缩放层(warping layer)、损失量层(costvolumn layer)和光流估计器(opticalflow estimator)。
[0045]
金字塔特征提取器是一个6层的卷积神经网络,每次进行2倍下采样,对视频相邻两帧分别提取特征;假设当前帧为t,缩放层用t-1帧光流场结果矫正第t帧特征图,得到新特征图。如公式(1)所示,其中x表示像素索引,表示第w个特征金字塔的第l层的金字塔特征,up2(w
l+1
)(x)表示将第w个特征金字塔的第l+1层的像素x两倍上采样。
[0046][0047]
损失量是3d深度预测的一个概念,在pwc-net中用来评估两个特征图之间的变化。损失量层计算两帧图像经过特征提取和形变之后的损失量,如公式(2)所示,其中n表示当
前层特征像素个数。
[0048][0049]
光流估计器也是一个6层的卷积神经网络,利用之前计算出来的损失量、第一张图片的特征和上采样的光流联合预测当前两帧最终的光流结果。使用损失量来预测光流是pwc-net的最大改进,可以更好地通过这种方式加强网络对于输入数据的适应,相当于在更高维度加强了特征。
[0050]
pwc-net计算得出的光流采用双通道方式表示,双通道的第一个通道表示光流场矢量在x轴(水平方向)上的大小和方向,第二个通道表示光流场矢量在y轴(垂直方向)上的大小和方向,其中数值表示大小,正负表示方向。整体光流场矢量是x轴和y轴矢量的和矢量,这些数据有足够的特征表征运动信息。
[0051]
(2.2)多帧累积光流计算
[0052]
本发明利用(2.1)中pwc-net网络结构计算相邻两帧间的光流,再利用视频中连续多个相邻帧计算得到多帧光流,将这些光流进行叠加,形成多帧累积光流场,有助于突出慢速小目标的运动信息。因此本发明提出利用多帧累积光流代替两帧光流作为表观运动联合网络的输入,在运动信息的补充上相比于仅利用相邻两帧光流能更好地提升慢速小目标的检测准确率。
[0053]
假设视频相邻两帧计算的光流结果为(ui→
i+1
,vi→
i+1
),则从第1帧到第n 帧的n-1帧累积光流场s1→n可以由下述公式(3)表示。
[0054][0055]
多帧累积光流的累积帧数参数n,优选为n=3。
[0056]
(3)表观运动联合网络的构建
[0057]
附图1描述了本发明构建的表观运动联合网络的网络结构。首先将多帧累积光流与rgb三通道数据进行预处理,然后将预处理后的数据作为表观运动联合网络的输入,以darknet-53作为骨干网络提取特征,在yolo层进行目标检测,并将该yolo层中特征图经过上采样,与darknet-53中相应尺度的特征图进行维度拼接,实现多层特征的融合,为下一个yolo层提供数据。网络共使用多个yolo层(优选为3个)进行不同尺度的目标检测,每个yolo 层将输入的特征图进行若干次(优选为5次)darknetconv2d_bn_leaky(dbl)操作,dbl即在一个卷积层后跟一个batch normalization层和一个leakyrelu层,得到输入到下一个yolo层的特征图,再进行1次 darknetconv2d_bn_leaky操作,并经过1
×
1卷积运算,输出对应的 s
×s×b×
(c+(4+1))维度的张量,其中,s
×
s表示yolo层中划分的网格数量,b表示每一个网格上产生的边框个数,c表示网络支持识别的类别数;输出张量中包含每个预测边界框的所属类别概率、位置参数以及物体置信度,其中,所属类别概率表示在预测框存在目标的情况下,目标属于各个类别的对应概率,位置参数包括4个参数x、y、w、h,分别表示预测框的中心点相对网格的偏移量和相对于s
×
s网格的宽、高,物体置信度表示预测框中存在目标的概率。三个yolo层分别利用对应大小的预测框进行目标检测,并结合运动目标预测损失来计算损失函数,损失函数包括了yolov3的损失和运动目标损失。
[0058]
(3.1)输入数据预处理:实际生活中,人眼并不一定需要目标运动的方向才可以识别出运动物体。因此,本发明将光流数据取绝对值,去除光流中的方向信息,只使用光流的
数值大小表示当前像素运动的快慢,从而减少表观运动联合网络训练过程中的噪声,加快收敛速度。此外,rgb三通道像素数据采用了归一化预处理,将数据范围限制在0到1之间,而光流数据也采用归一化操作,使光流的数据分布与表观特征数据的分布相同,从而解决数据范围不一致产生的问题。对光流取绝对值、归一化如下述公式(4)所示,其中mean
|u|
表示u方向上光流绝对值的平均值,variance
|u|
表示u方向上光流绝对值的标准差,mean
|v|
表示v方向上光流绝对值的平均值,variance
|v|
表示v方向上光流绝对值的标准差。
[0059][0060]
(3.2)表观运动联合网络的输入:yolov3单帧目标检测网络的输入是图像rgb三通道像素值,本发明将多帧累积光流和rgb三通道像素值经过预处理后的结果通过维度连接操作进行连接,作为表观运动联合网络的输入。如附图1表观运动联合网络框架示意图中输入部分所示,前两层为水平和垂直光流场结果,后三层表示rgb三通道图像。
[0061]
在yolov3单帧目标检测网络中,第一个卷积层通过32个3
×
3大小、步长为1的卷积核进行卷积操作,对原图像提取特征并生成第一层特征图。本发明针对加入的累积光流输入,将第一个卷积层中每一个卷积核的神经元权重参数从3个增加到5个,使得第一层的神经元能够使用新增的神经元权重参数在5个通道输入上计算得出第一层特征图,从而同时提取表观和运动特征。网络第一层特征f1可以用下述公式(5)表示,其中表示双通道光流场经过卷积操作的计算结果,表示rgb三通道数据经过卷积操作的计算结果。
[0062][0063]
(3.3)运动目标置信度和损失函数设计:上述表观运动联合网络能够依靠表观特征检测到较大的静止目标,也能依靠运动特征检测到运动较快的弱小目标,本发明进一步对表观运动联合网络进行改进,使得网络可以区分运动目标和静止目标,并输出运动目标。
[0064]
表观运动联合网络的输入已经包含了目标的运动特征,如果要使其区分运动目标和静止目标,需要对输出部分增加损失函数约束。本发明提出在现有yolo层每一个预测边界框输出4个位置参数和1个物体置信度的基础上,增加1个运动目标置信度,该值是回归连续值,用来表示当前目标框中预测得到的目标是运动目标的置信度。如下述公式(6)所示,s
×
s表示yolo层中划分的网格数量,b表示每一个网格上产生的边框个数,c表示网络支持的的识别类别个数,output_dim表示yolo层输出的张量维度。输出张量中包含每个预测边界框的所属类别概率、位置参数、物体置信度以及增加的运动目标置信度。其中,所属类别概率表示在预测框存在目标的情况下,目标属于各个类别的对应概率;位置参数包括4个参数x、y、w、h,分别表示预测框的中心点相对网格的偏移量和相对于s
×
s网格的宽、高;物体置信度表示预测框中存在目标的概率。因网络将输入数据进行了yolov3中的编码操作,所以yolo层将该输出张量进行相应的解码操作得到真实输出。
[0065]
output_dim=s
×s×b×
(c+(4+1+1))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0066]
在损失函数部分,本发明在yolov3单帧目标检测网络的五类损失之外,增加运动目标预测损失,该损失使用二分类交叉熵,具体公式表示如(7)所示,其中loss表示yolov3单帧目标检测网络中定义的损失函数,用来累计检测框位置损失和类别损失;求和符号中
的s2表示yolo层中分割的网格数量,表示第i个网格的第j个预测边界框中是否存在目标,如果存在目标则为1,否则为0;mi(j)表示第i个网格的第j个预测边界框中预测得出的运动目标置信度,表示数据集中运动目标区域的真实标注,运动目标标注为1,静止目标标注为0。
[0067][0068]
上述公式中新加项在训练过程中对网络进行约束,令网络能够进一步区分静止目标和运动目标。在测试时,根据网络输出的运动目标置信度判断该目标是否为运动目标,如果运动目标置信度大于阈值th,则将其视为运动目标输出。
[0069]
运动目标置信度阈值参数th,优选为th=0.5。
[0070]
以上公开的仅为本发明的具体实例,根据本发明提供的思想,本领域的技术人员能思及的变化,都应落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1