一种基于变分自编码器的文本分类方法与流程
1.本发明涉及文本分类领域,尤其是涉及一种基于变分自编码器的文本分类方法。
背景技术:
2.变分自编码器(vae)是机器学习和大数据分析中一种非常重要的模型,在文本生成、图片生成、自动分类等领域扮演者极其重要的角色。但是在将vae应用文本分类的任务中时,标准vae汇面临后验坍塌的问题,从而无法正常工作。
技术实现要素:
3.本发明主要是解决现有技术容易出现后验坍塌问题的缺陷,提供一种基于变分自编码器的文本分类方法,解决了后验坍塌。
4.本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种基于变分自编码器的文本分类方法,包括以下步骤:
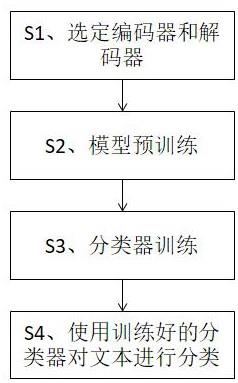
5.s1、选定编码器和解码器组成模型;
6.s2、对模型进行预训练;
7.s3、分类器训练:利用预训练得到的模型中的文本编码器提取已经采集到的分类标注数据的特征向量,在此基础上利用分类标注数据训练文本分类器;分类标注数据的采集一般由外部完成;
8.s4、使用训练好的文本分类器对文本进行分类。
9.作为优选,所述步骤s2具体为,先收集一个没有人工标注对的文本数据集,然后通过损失函数对于模型进行训练。
10.作为优选,所述损失函数为:
[0011][0012]
式中,θ和ф为编码器参数,τ为解码器参数,λ为常数,q
ф
(z|x)为编码器模型的输出概率,p
τ
(x|z)为解码器模型的输出概率;
[0013]
损失函数由文本选择函数和普通vae结合得到,普通vae为:
[0014][0015]
式中,q(x|z)为编码器模型的输出概率,p(x,z)为联合概率,e为求期望值操作,d
kl
为k
‑
l散度,p(z)为z的边际概率;
[0016]
文本选择函数为:
[0017][0018]
x为文本,t为文本x的长度,z为空间向量(隐变量),p(x|z)为条件分布,e为自然常数,g
τ
为文本编码器,将文本x
i
映射到向量空间f
τ
是第二编码器,将向量空间z投射到同样的向量空间a为选择样本的范围数量,i为文字数据序号,k为当前选中的文本。第二编码器是一个单独的模型,主要目的是将对向量空间z进行转换,向量大小和编码器维度一样。
[0019]
作为优选,步骤s2中,训练方法为sgd优化算法。
[0020]
本发明带来的实质性效果是,通过加入新的增强损失函数,来解决后验坍塌的难题,提高vae针对文本数据的分类性能。
附图说明
[0021]
图1是本发明的一种流程图。
具体实施方式
[0022]
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
[0023]
实施例:普通vae的实现方法通过优化如下elbo损失函数实现:
[0024][0025]
标准vae在编码文本数据时,会出现著名的后验坍塌现象,导致vae编码无法包含有意义的文本内容信息。为了解决这个问题,我们提出了一种新颖的辅助函数:“文本选择辅助函数”来解决上述问题,获得包含丰富语义信息。通过文本选择辅助函数,从而让隐变量z包含更多的语义信息。正常情况下,一个自回归解码器将条件分布p(x|c,z)分解为一连串的下一个词的乘积:
[0026][0027]
其中t是文字x的长度。这样的链式结构让解码器很容易的忽略掉隐变量z的信息,这是因为自然语言中强烈的顺序关系会减弱全局隐变量中信息的重要。与此相反的是,假如任务是要从多个文本中干扰项中选择正确的文本,那隐变量就必须包含全局的语义信息。文本选择函数可以被表达为:
[0028][0029]
其中g
r
是文本编码器,它将文本x
i
映射到向量空间而f
τ
是另一个编码器,将向量空间的z转换到同样的向量空间
[0030]
但是,由于自然语言的广阔空间,我们无法枚举出分母中所有可能的文本,因为a有无穷的可能性。因此,我们通过负采样对其进行近似。也就是说,我们从训练数据中的所有话语中随机抽取k分散注意力的响应,并将训练目标修改为:
[0031][0032]
同样的,将我们提出的文本选择函数和普通vae损失结合之后,我们可以得到一个新的损失函数:
[0033][0034]
针对本发明提出的两个新颖损失函数,我们使用如下流程实现对于文本的分类和理解。
[0035]
1.选定编码器和解码器:vae架构对于具体编码器或者解码器的选择非常灵活,针对文本数据选择包括lstm(long
‑
short term memory)或者transformer。
[0036]
2.模型预训练:选定模型后,首先我们要对其进行训练。具体来说,我们先收集一个没有人工标注对的文本数据集,里面包含着大量和业务相关的文本数据,例如新闻、聊天等等。然后给定训练数据后,我们通过损失函数对于模型进行训练。训练方式一般采用sgd优化算法。
[0037]
3.分类数据采集:首先制定要分类的标签集,并且对于一个数据集进行人工标注,注意此处标注的数据量可以远远小于上一步的预训练数据量,此步骤可由外部完成,直接采用现成的分类标注数据。
[0038]
4.分类器训练:我们现在可以抛弃解码器,利用预训练得到的文本编码器作为文本的特征向量,在此基础上利用上一步获得的分类标注数据训练文本分类器,分类器的选择可以采用svm(support vector machine),lr(logistic regression)等常见分类模型。
[0039]
5.其他应用:此外,本方面得到的文本向量z,除了可以支持文本分类之外,还可以被用于文本聚类和数据可视化等其他应用场景,对于城市驾驶舱,商业智能等场景有着巨大意义。
[0040]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
[0041]
尽管本文较多地使用了编码器、预训练、损失函数等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
技术特征:
1.一种基于变分自编码器的文本分类方法,其特征在于,包括以下步骤:s1、选定编码器和解码器组成模型;s2、对模型进行预训练;s3、分类器训练:利用预训练得到的模型中的文本编码器提取已经采集到的分类标注数据的特征向量,在此基础上利用分类标注数据训练文本分类器;s4、使用训练好的文本分类器对文本进行分类。2.根据权利要求1所述的一种基于变分自编码器的文本分类方法,其特征在于,所述步骤s2具体为,先收集一个没有人工标注对的文本数据集,然后通过损失函数对模型进行训练。3.根据权利要求2所述的一种基于变分自编码器的文本分类方法,其特征在于,所述损失函数为:式中,θ和ф为编码器参数,τ为解码器参数,λ为常数,q
ф
(z|x)为编码器模型的输出概率,p
τ
(x|z)为解码器模型的输出概率;损失函数由文本选择函数和普通vae结合得到,普通vae为:式中,q(x|z)为编码器模型的输出概率,p(x,z)为联合概率,e为求期望值操作,d
kl
为k
‑
l散度,p(z)为z的边际概率;文本选择函数为:x为文本,t为文本x的长度,z为空间向量,p(x|z)为条件分布,e为自然常数,g
τ
为文本编码器,将文本x
i
映射到向量空间f
τ
是第二编码器,将向量空间投射到向量空间a为选择样本的范围数量,i为文字数据序号,k为当前选中的文本。4.根据权利要求3所述的一种基于变分自编码器的文本分类方法,其特征在于,步骤s2中,训练方法为sgd优化算法。
技术总结
本发明公开了一种基于变分自编码器的文本分类方法,其包括以下步骤:S1、选定编码器和解码器组成模型;S2、对模型进行预训练;S3、分类器训练;S4、使用训练好的分类器对文本进行分类。步骤S2具体为,先收集一个没有人工标注对的文本数据集,然后通过损失函数对于模型进行训练。通过加入新的增强损失函数,来解决后验坍塌的难题,提高VAE针对文本数据的分类性能。能。能。
技术研发人员:赵天成
受保护的技术使用者:宏龙科技(杭州)有限公司
技术研发日:2021.09.30
技术公布日:2021/12/23
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1