可区分用户-项目协同聚类的制作方法
可区分用户-项目协同聚类
背景技术:
1.基于用户的行为历史推断用户偏好并向用户推荐偏好项目的能力是一门日益发展的技术,具有广泛的应用。改进推荐模型可以提高用户体验,并创造更高的收入。
附图说明
2.附图说明了本概念的实现。通过结合附图参考以下描述,可以更容易地理解所示实施方式的特征。在各种附图中使用相同的附图标记来指示相同的元件。附图不一定按比例绘制。在图中,参考符号的最左边的数字表示参考符号首次出现的图形。在说明书和附图中的不同实例中使用相似的附图标记可以指示相似或相同的项目。
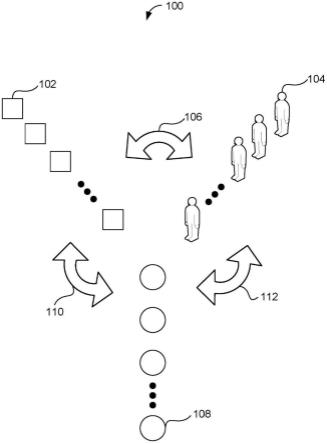
3.图1示出了与本概念一致的可区分用户-项目协同聚类环境的概念图。
4.图2示出了与本概念一致的可区分用户-项目协同聚类模型的架构图。
5.图3示出了与本概念一致的项集聚合器模块的架构图。
6.图4示出了与本概念一致的可区分潜在协同聚类模块的架构图。
7.图5示出了示出了与本概念一致的可区分用户-项目协同聚类方法的流程图。
8.图6示出了与本概念一致的可区分用户-项目协同聚类系统。
具体实施方式
9.本概念涉及可区分的用户-项目协同聚类(differentiable user-item co-clustering,“duicc”),其可以是一种推荐模型,可以检测用户和项目空间中的协同聚类结构以及向用户推荐项目。协同聚类(可以被视为社区)可以代表对一组项目有共同兴趣的一组用户。在协同聚类结构中检测用户和项目的共存可以提高推荐性能。
10.人们的消费行为(诸如,购买物品、访问网站、听歌曲或观看视频)可以用作激励推荐系统的信号。有相似兴趣的人倾向于与相似的内容交互。这一观察结果在(1)协作过滤(collaborative filtering)、(2)网络数据的社区检测和(3)协同聚类方面推动了大量研究和开发。协作过滤已经成为推荐算法的一种流行选择。
11.首先,协作过滤涉及挖掘用户和他们消费的项目之间的相关性。协作过滤的常用方法包括基于最近邻的方法、矩阵分解和深度神经网络。然而,这些算法主要是在实例级别查看单个用户和单个项目之间的相关性。这种方法可能效率低下,因为它没有将关于数据生成过程的先验知识应用到模型中,这有助于缓解数据稀疏性。其他现有技术将用户和项目嵌入群集在单独的事后处理中。这可能导致性能不理想,因为聚类步骤没有考虑推荐性能。
12.第二,社区检测是网络和图形背景下广泛研究的主题。现有的方法包括因子分解、深度学习、标签传播和光谱方法。然而,许多现有算法无法处理重叠的社区,或者无法扩展到大型数据集合(例如,十亿规模)。一种被称为大网络聚类关联模型(“bigclam”)的社区检测算法利用非负矩阵分解来大规模检测重叠社区。然而,bigclam发现的社区并不十分一致。这可能是因为bigclam没有充分利用用户交互数据的二部分结构。此外,目前还不清楚
如何将专门为社区检测设计的算法用于推荐任务。
13.第三,协同聚类(也称为双聚类、块聚类或双模聚类)是一种数据挖掘技术,它允许对矩阵的行和列进行协同聚类。用户-项目消费矩阵也可以被视为二部分图,用户节点和项目节点之间的边指示项目是否被用户消费。这种转换允许将协同聚类方法应用于该问题。然而,迄今为止开发的大多数协同聚类方法只能在最多数千行或列的中型数据上运行,因此不适用于大规模社区检测问题。此外,与传统的社区检测算法类似,协同聚类方法不提供推荐接口。
14.本概念涉及duicc,它可以在细粒度级别上标识内容项和人员的协同聚类成员资格,然后使用该协同聚类结构来高效地动态推荐项目。duicc可以利用这样一个想法,即相似的人与相似的项目之间的许多交互都是围绕用户-项目协同聚类或信息社区进行的,即共享共同行为的人的分组主要围绕相关内容(如信息源)。例如,多次访问某个网站参加数据挖掘会议的人可能会形成一种信息协同聚类,其成员可能会对其他数据挖掘相关网站感兴趣。因此,与仅关注用户和项目之间交互实例的传统短视技术相反,duicc可以解释围绕相似和相关项目集合共享共同消费行为的人群的协同聚类。此外,duicc可以在稀疏数据上提供显著改进的推荐性能,同时产生连贯和可解释的协同聚类。
15.图1示出了与本概念一致的示例duicc环境100的概念图。duicc环境100可以包括项目102。项目102可以表示人们可以交互过或消费的任何东西。例如,项目102可以包括产品、服务或信息内容,包括网页、电影、歌曲、商品、新闻、媒体、频道、播客、软件、书籍、流派、作者、运动队、名人、商店、专业组织、订阅、食品、服装、目的地、等等。这些只是一些示例,以说明可以包括在duicc环境100中的各种类型的项目102。令i是项目102,以及令i是所有项目102的集合。
16.duicc环境100可以包括用户104。用户104可以呈现个人、用户帐户、用户角色、企业或可以与项目102交互的任何实体。令u表示用户104,令表示所有用户104的集合。
17.duicc环境100可以包括用户-项目交互106,其可以包括表示特定用户104和特定项目102之间的历史交互的数据。用户-项目交互106的实例可以形成为:用户104浏览、查看、分享或购买商品的结果;订购或查看服务;打开、阅读或下载文章;访问或添加网站书签;预览、观看、下载或喜欢电影;购买、下载、收听、添加播放列表歌曲或不喜欢歌曲;查看、添加购物清单、检查商品价格或订购商品;订阅或喜欢某个频道;订阅、收听或分享播客;下载、安装或启动软件;购买、下载或阅读一本书;添加收藏夹、搜索或选择流派、点击或购买作者写的书;观看体育队比赛、购买体育队门票或购买与体育队有关的纪念品;访问或从商店购买(无论是实体实体店还是数字线上商店);加入或更新组织成员资格等。这些只是示例。实际上,用户104和项目102之间的任何活动或关联的任何实例都可以形成用户-项目交互106。因此,用户-项目交互106可以表示用户104相对于项目102的消费行为。在一个示例实现中,用户-项目交互106可以由项目102的集合表示,其中每一个项目集合102包括特定用户104交互过的项目102。令表示用户-项目交互106的集合,其中用户u与项目i交互。
18.与本概念一致,duicc模型可以形成协同聚类108(或信息社区)。令c表示协同聚类108,并令c表示所有协同聚类108的集合。协同聚类108可以对相似或相关的项目102进行分
组。此外,协同聚类108还可以对具有相似消费行为的相似或相关用户104进行分组。在一个实现中,项目102在协同聚类108中的成员资格和用户104在协同聚类106中的成员资格可以不是全部或全部。相反,每个项目102和每个用户104可以具有它们属于每个协同聚类108的程度(或亲和)。也就是说,每个用户104和每个项目102可以属于具有不同关联程度(或不同亲和)的多个协同聚类108。
19.因此,与本概念一致,duicc模型可以确定表示项目102和协同聚类108之间的亲和的项目-协同聚类亲和得分110,并且还可以确定表示用户104和协同聚类108之间的亲和的用户-协同聚类亲和得分112。例如,重复访问与数据挖掘相关的多个网站的用户104可以被确定为对表示数据挖掘主题的协同聚类108具有强的用户协同聚类亲和得分112。此外,可以确定表示由多次访问多个数据挖掘相关网站的多个用户104访问的数据挖掘会议网站的项目102与数据挖掘协同聚类108具有强的项目-协同聚类亲和得分110。与之相反,表示与数据挖掘主题完全无关并且尚未被对数据挖掘协同聚类108具有强用户-协同聚类亲和得分112的用户104消费的网站的另一个项目102可以被确定为对数据挖掘协同聚类108具有弱项目-协同聚类亲和得分110。类似地,其消费历史(即该用户104的用户-项目交互106)对数据挖掘表现出零兴趣的另一用户104(即,与对数据挖掘协同聚类108具有强项目协同聚类亲和得分110的项目102的零交互)可以被确定为对数据挖掘协同聚类108具有弱用户协同聚类亲和得分112。
20.在一个示例实现中,用户和项目i可以被共同协同聚类为n重叠的协同聚类。协同聚类n的数目可以是预设的超参数。例如,协同聚类n的数目可以被预设为1000或2000。令表示用户u对协同聚类c的用户-协同聚类亲和得分112,以及令表示项目i对协同聚类c的项目-协同聚类得分110。用户-协同聚类亲和得分和项目协同聚类亲和得分两者的非负性可以确保它们的绝对值直接地反映用户u和项目i在协同聚类c中的成员资格强度。在该软分配范例下,任何用户104或项目102都可以属于多个协同聚类108。
21.在协同聚类108中形成的这些联系可以由用户104对项目102的消费来通知,并且因此优于社交网络中的联系。将消费行为(用户-项目交互106)提取到协同聚类108中的一个示例优点包括对大规模数据集合的改进的概括,因为直接地学习用户对用户、用户对项目或项目对项目的相关性可能是次优的,这是因为随着项目102和用户104的数目增加,这些信号之间的稀疏性和重叠性会降低。此外,duicc模型可以推断出不仅以推荐为中心,而且还可以捕捉潜在结构,如位置、专业和兴趣,而无需对每个维度进行显式建模。此外,在细粒度级别上标识项目102和用户104两者的协同聚类成员资格可以使duicc模型能够基于用户的长期兴趣而不是短期的话题峰值或流行项目趋势来做出更有效和透明的建议。
22.如上所述,duicc模型可以将用户104和项目102之间的用户-项目交互106作为输入并定义协同聚类108。因此,被指派给相同协同聚类108的用户104可以志同道合的,有共同的偏好,表现出类似的消费模式,和/或在该特定的协同聚类108的项目102方面有类似的兴趣。然后,duicc模型可以为用户104可能想要交互过的特定用户104生成项目102的推荐。推荐可以是为所有项目102计算的偏好得分的形式。然后,得分最高的项目102可以构成推
荐。也就是说,给定用户u过去交互过的项目集合duicc模型可以通过学习预测用户u对所有项目i的项目i偏好s的函数r来执行推荐任务。
23.公式1
24.s
ui
=r(iu,i),i∈{1,
…
,|i|}
25.在公式1中,令表示用户u对项目i的偏好得分。
26.由duicc模型输出的所有项目102的偏好得分可用于向用户104呈现推荐。例如,项目102可以由其对应的偏好得分来进行排序,然后一定数目的最高得分(最高排名)的项目102可以为推荐、建议、广告、提示等呈现给用户。例如,软件应用(例如,浏览器)可以在图形用户界面(“gui”)上向用户104呈现推荐项目(例如,url、电影、歌曲、书籍等)。在一个实现中,推荐项目102可以排除用户104已经交互过的项目集合iu。例如,推荐电影的列表可以排除用户104过去已经看过的电影集合。
27.图2示出了与本概念一致的示例duicc模型200的架构图。duicc模型200的输入可以包括项目102的集合、用户104的集合和/或用户104与项目102之间的用户-项目交互106。在一个实现中,duicc模型200可以把用户104交互过的项目102的集合作为输入。令iu={i,j,k}表示用户u交互过的项目集合{i,j,k}。
28.duicc模型200可以包括项目嵌入模块202,该项目嵌入模块可以将用户104交互的项目102集合转换为项目嵌入204。令{ei,ej,ek}表示项目嵌入204。在一个实现中,项目嵌入ei可以是表示具有维度d的项目i嵌入的密集向量。也就是说,项目嵌入向量ei可以包含d个实数列表。例如,如果d=3,则示例项目嵌入向量ei可以是[-0.2,0.5,1.0]。项目嵌入204{ei,ej,ek}可以被随机初始化,然后在训练期间被微调。在替代实现中,项目102可以被特征化,使得duicc模型200可以学习项目102的特征或属性到表示空间的映射,而不是学习每个项目102的一个项目嵌入204。
[0029]
duicc模型200可包括项目集合聚合器模块206。项目集合聚合模块206可根据项目嵌入204构建用户简档208(或用户嵌入)。也就是说,项目集合聚合程序模块206可以通过聚合用户104过去交互过的项目102的表示204来动态构建用户104的表示208。例如,项目集合聚合器模块206可以将项目嵌入204作为输入,然后输出用户简档208。令表示从项目嵌入{ei,ej,ek}生成的用户u的用户简档208(或用户嵌入)。下面将结合图3更详细地解释项目集合聚合模块206。
[0030]
duicc模型200可以包括可区分潜在协同聚类(“dlcc”)模块210。dlcc模块210可以从项目嵌入模块202中获取所有的项目嵌入204和由项目集聚合器模块206构建的所有用户简档208,在项目和用户中构建聚类结构(即,检测协同聚类108),并输出项目102的偏好得分212。为物品102计算的这些偏好分数212可用于提供推荐物品102的列表。为项目102计算的这些偏好得分212可用于提供推荐项目102的列表。如上文关于公式1所解释的,偏好得分s
ui
可指示用户u可能偏好消费项目i的程度。dlcc模块210将在下文结合图4进行更详细的解释。
[0031]
协同聚类108中的细粒度子组结构可以使duicc模型200能够检测和利用用户偏好空间中的复杂和潜在维度,例如位置或生活方式,而不必手动和显式地建模这些维度。也就是说,不需要手动明确地定义每个协同聚类。为了使协同聚类108与下游推荐性能对齐,可
以使用监督的推荐损失,这将在下面结合后续图进行详细解释。duicc模型200中的三个模块——项目嵌入模块202、项目集合聚合器模块206和dlcc模块210——可以是完全可区分的,并且可以进行端到端的训练。这三个模块可以用软件、硬件或组合来实现。
[0032]
与当前概念一致,duicc模型200可以基于协同聚类108可以驱动用户-项目交互106的动态的见解(insight)来统一推荐和协同聚类。也就是说,如果用户104和项目102属于同一个协同聚类108或更相似的一组协同聚类108,则用户104可能更可能与项目102交互。从建模的角度来看,这意味着用于计算用户u的偏好得分s的偏好函数r可以通过她的潜在协同聚类成员资格来表达。
[0033]
图3示出了与本概念一致的项目集聚合器模块206的架构图。如上所述,项目集聚合器模块206可以使用表示用户104已经交互过的项目102的项目嵌入204为每个用户104构建用户简档208。在一个实现中,项目集聚合器模块206可以使用协同聚类条件注意力(attention)层302将项目嵌入204聚合到用户简档208中在一个实现中,每个用户104可以由n个用户嵌入向量表示。每个用户嵌入向量可以包含d个实数列表,其中d表示维度。例如,如果d=3,则示例用户嵌入向量可以是[0.05,0.8,-0.2]。
[0034]
例如,给定用户u交互过的项目集合iu,项目嵌入模块202可以将这些项目的表示生成为项目嵌入(ei,i∈iu)。然后,项目集聚合器模块206可以采用协同聚类条件注意力机制302来构造用户表示例如,通过采用公式2中所示的n-头部点积注意力方法。
[0035]
公式2
[0036][0037]
在公式2中,d可以表示项目嵌入ei的维度,并且每个头hc可以通过向更多预测项目102指派更高的权重来构建协同聚类条件用户表示此外,可以添加缩放因子来解决潜在的消失梯度问题,并且可以添加线性投影304以对齐用户104和项目102的特征空间。分子可以计算项目对于协同聚类的重要性,softmax函数可以计算指派给每个项目嵌入ei的权重。因此,针对协同聚类c的用户嵌入可以是用户交互过的项目的项目嵌入的加权平均值(ei,i∈iu)。参数w和hc可以在训练过程中被优化。
[0038]
注意力机制302可以基于协同聚类108为条件。每个协同聚类108可以具有注意力头,并且注意力头可以确定哪些项目102将被指派更高的权重,哪些项目102被指派更低的权重。协同聚类条件注意力机制302可以被设计为学习每个项目102预测从该项目102到该协同聚类108的信号强度的程度。
[0039]
在一个实现中,用户简档208可以是给定用户104交互过的项目102的加权和。由项
目集聚合器模块206输出的用户嵌入208集合可由dlcc模块210用于对用户u进行协同聚类并将其分配给n个协同聚类。与使用全局注意力机制相比,与本概念一致的duicc模型200可以使用协同聚类条件注意力302,这可以允许预测项102在协同聚类108之间变化。
[0040]
与本概念一致的项目集聚合器模块206可以提供与具有显式用户表示相比的许多优点。除了消除适合这种单独用户表示的需要之外,项目集聚合器模块206可以消耗关于用户104的数目的常量存储器,因为项目集合聚合模块206的参数可以在所有用户104之间共享。因此,duicc模型200可以很容易地扩展到为大量的用户(如数十亿用户)提供服务,而传统的方法通常扩展为此外,项目集聚合器模块206可以允许duicc模型200快速地响应用户交互历史106中的任何变化(例如,从iu添加或删除项目),因为推断用户简档208可能只需要两个高度并行的线性操作。
[0041]
在一个实现中,通过将标量zc缓存为以下内容,可以降低构建协同聚类条件用户表示的计算成本:
[0042]
公式3
[0043][0044]
每当用户u与新项目j交互时,使得用户u交互过的项目集合iu被更新以包括新项目j,可以通过使用下面的公式4首先计算更新的标量z
′c,然后计算更新的用户表示而不重新计算所有项目i∈iu的新用户表示,来使用缓存的标量zc快速更新用户表示
[0045]
公式4
[0046][0047][0048]
因此,这种更新的计算成本可以保持常量并且不需要随着项目-用户交互历史的增加而增长。该范例可以应用于用户104有意或无意地改变其简档的情况(例如,从用户104交互过的项目集合中移除项目102)。
[0049]
因此,duicc模型200可以立即对用户与新项目102的新交互106做出反应(例如,用户104访问了新url或进行了新购买)。duicc模型200可以实时更新用户简档208。
[0050]
在一个示例实现中,可以允许用户104经由gui从她的历史中手动删除某些用户-项目交互106,例如出于隐私目的或调整未来的推荐。在另一示例实现中,用户-项目交互106可以包括指示何时发生用户-项目交互106的时间戳,从而可以自动移除旧的或过时的
用户-项目交互。也就是说,用户104很久以前(例如,长于某个阈值时间)交互过的一个或多个过时项目102可以自动从用户104的用户-项目交互集合106中修剪或移除,以保持用户-项目交互106的集合新鲜,并更好地反映用户的当前偏好和当前消费行为。如上所述,在从用户u的项目集合iu中修剪过时项目{i,j,k}之后更新用户简档可以按常量时间的顺序执行。
[0051]
图4示出了与本概念一致的dlcc模块210的架构图。在一个实现中,每个协同聚类c可以由具有维度d的协同聚类嵌入ec来表示,其可以是包含d个实数列表的向量。例如,如果d=3,则示例协同聚类嵌入向量ec可以是[1.2,-0.2,0.5]。与项目嵌入ei类似,协同聚类嵌入ec可以被随机初始化,然后在训练过程中被微调或优化。
[0052]
dlcc模块210可以学习项目表示ei和协同聚类表示ec,并计算项目i与协同聚类c的接近程度的项目-协同聚类亲和得分。此外,dlcc模块220可以使用由项目集聚合器模块206构建的用户表示来计算用户与协同聚类接近程度的用户-协同聚类亲和得分。因此,dlcc模块210可以将项目102关联到协同聚类108,以及将用户104关联到协同聚类108。
[0053]
dlcc模块210可以学习和构建n个协同聚类,并使用机器学习基于用户-项目交互输入数据106来建模协同聚类108中的项目成员资格110和用户成员112资格的分布和指派。在一个示例实现中,项目102和用户104的协同聚类指派和分布可以被随机初始化。协同聚类指派(即,到协同聚类108的用户和项目分布)可以被参数化。这些参数可以通过目标函数进行微调。因此,duicc模型200的目标之一可以是通过微调参数来最小化目标函数。使用反向传播算法,可以计算关于每个参数的梯度,然后用于更新每个迭代的参数。例如,变量w和公式2中的向量hc以及参数ei可以在训练期间进行微调。
[0054]
如上所述,可以基于馈送到duicc模型200中的用户-项目交互数据106,通过微调协同聚类指派和分布来训练duicc模块200。dlcc模块210可以将所有用户简档208以及所有项目嵌入204作为输入,并且可以输出偏好得分212。dlcc模块210可以学习协同聚类嵌入ec。在训练期间,社区嵌入ec可以隐含地或间接地受到项目嵌入ei和用户嵌入的影响。dlcc模块210可以计算用户嵌入208与协同聚类嵌入之间的点积、计算项目嵌入204与协同聚类嵌入(ei·
ec,c=1,
…
,n)之间的点积、,然后使用校正线性单元(“relu”)402对它们进行聚合。relu 402可用于强制用户-协同聚类亲和得分112和项目-协同聚类亲和得分110两者的非负性。此外,在一种实现方式中,dlcc模块210可使用relu402来计算亲和得分和并且使用最小和池化操作404来根据用户简档协同聚类嵌入ec和项目嵌入ei来预测或计算用户u对项目i的偏好得分s
ui
。
[0055]
因此,dlcc模块210可以通过将用户104和项目102的亲和(用户-协同聚类亲和得分112和项目-协同聚类亲和得分110)建模为潜在协同聚类108来定义用户104和项102的聚类。在一个实现中,社区嵌入ec和亲和得分和可以被一起优化。duicc模型200因此可以被端到端训练。例如,可以学习每个协同聚类c的协同聚类嵌入表示ec,并且用户-协同聚类亲和得分和项目-协同聚类亲和得分可以计算为:
[0056]
公式5
[0057][0058][0059]
例如,用户-项目交互106可以包括相似项目102的协同出现(例如,与项目i交互的许多用户104也与项目j交互)。可以利用这些协同出现信号来学习项目集合之间的相似性。
[0060]
在一个示例实现中,可以使用基于掩蔽的训练损失来训练duicc模型200。例如,用户104交互过的项目集合iu中的一个项目102可以被保留,然后duicc模型200可以使用其余的项目102来训练,以最佳地预测保留的项目102,则反向传播损失可能不会发生。否则,如果duicc模型200没有正确地预测保留的项102,则可以传播信号和损失以调整计算嵌入的每个层的参数。
[0061]
有许多可用于训练duicc模型200的损失函数的选择。在一个示例实现中,可以使用softmax分类损失来训练duicc模型200,这可能比二进制推荐中的逐点损失更可取,因为softmax分类损失可以鼓励对前n个排名进行更好的权重分配。在一个示例实现中,可以采用采样而不是计算全softmax损失,以能够处理大项目词汇表大小。此外,为了防止duicc模型200学习琐碎的关系,用户104已经交互过的项目iu={i,j,k}可以被屏蔽掉。
[0062]
例如,给定用户u已经交互过的项目集合iu,该项目集合iu中被随机选择的项目(即,k∈iu)可以在训练时间内被保留,其余项目102可以被馈送到duicc模型200中以计算表示和得分。给定表示和得分,以下公式可用于计算在精神上类似于采样的softmax的负训练示例的采样集上的损失在训练过程中最小化的每用户损失可以是:
[0063]
公式6
[0064][0065]
其中可以α是用于标签平滑的超参数,λ可以是用于控制交叉熵和l1正则化的权重平衡的超参数,可以是表示用户u对社区c的亲和得分,并且可以是表示项i对社区c的亲合得分。i
sp
可以是用户u未交互过的负面项目集合。k可以是用户u交互过的项集中被保留的项。
[0066]
duicc模型200可以被优化以预测保留的项目。其余的非保留的项目可以用于构建用户表示。交叉熵项术语可以推动duicc模型200预测用户交互过的项目(k)相对于负面项目(i
sp
)的更高得分(s)。l1正则化术语可以优化亲和得分和并使其稀疏,使得每个用户104和/或每个项目102仅属于协同聚类108的一个子集。这可以缓解过度拟合的问题并改善模型性能。
[0067]
在训练期间,可以优化和更新所有模型参数,包括项目嵌入ei、用户嵌入和协同聚类嵌入ec,以及其他模型参数(例如,w和hc)。在训练期间,可以使用这些参数计算s
uk
、s
ui
、
和并且当损失函数(公式6)最小化时,可以反向传播梯度以更新它们。duicc模型200可以是完全可区分的;也就是说,例如,可以使用链式规则来计算关于每个模型参数的梯度。在计算关于每个参数的梯度之后,可以使用随机梯度下降(sgd)算法(例如adam方法)来更新参数。损失函数可以计算关于每个模型参数的梯度,并且优化的目标可以是最小化损失函数
[0068]
为了创建负样本集i
sp
,可以采用掩蔽机制来防止duicc模型200寻求平凡的解决方案(例如,身份映射)。例如,用户u已经交互过的项集iu可以被排除。
[0069]
公式7
[0070]isp
=sample(i\iu)∪{k}
[0071]
换言之,duicc模型200可能不会因其对除保留的项目k之外的正数示例所做的预测而受到惩罚。此外,由于用户-项目交互106可能不完整或不确定,因此可以使用标签平滑术语α来软化公式6中的交叉熵术语中的目标。该交叉熵术语包括s
uk
,表示用户u与项目k的用户-项目交互106的用户交互106,其可以为所有用户104和项目102提供监督。
[0072]
此外,为了鼓励紧凑的协同聚类结构,可以另外使用关于用户104和项目102之间的亲和得分之和的l1正则化。最终,每个用户的损失可以在小批量中平均,以训练duicc模型200。
[0073]
训练之后,协同聚类分配可以反映在交互数据106中检测到的协同聚类结构。dlcc模块210可以利用协同聚类108来预测和输出用户偏好向量su,该用户偏好向量su包括用户u对所有项的偏好得分s
ui
。
[0074]
基于用户协同聚类亲和得分112和项目协同聚类亲和得分110,可以应用轻量级最小和池化操作404来弥合协同聚类108的结构和推荐之间的差距。也就是说,用户u对项i的偏好得分s
ui
可以被计算为:
[0075]
公式8
[0076][0077]
其中内部术语可以计算用户u和项目i之间在协同聚类c方面的协同聚类重叠量,并且可以被视为“软和(soft and)”运算符。然后,外部求和σ可以聚合跨所有协同聚类c上的这样的重叠。当前的概念可以允许隔离每个协同聚类c对偏好得分向量su的贡献,同时也可以完全区分以实现端到端优化。通常,如果用户u是协同聚类c的一部分,并且项目i也是协同聚类c的一部分,则用户u可能更倾向于偏好项目i。也就是说,如果用户u对协同集群c的用户-协同聚类亲和得分较高,并且如果项目i对协同集群c的项目-协同集群亲和得分较高,则偏好得分s
ui
可能较高。例如,如果协同聚类c与汽车相关,并且用户u对汽车具有很强的亲和得分并且项目i与汽车有很强的关联性,则偏好得分s
ui
将很高。
[0078]
与本概念一致,从duicc模型200可以有两个输出集合。第一输出集合可以包括协
同聚类结构,该协同聚类结构指示每个项目102和每个用户104属于特定协同聚类108的程度。来自duicc模块200的第二输出集合可以包括针对每个用户104的项目102的排序列表,其中项目102根据用户的偏好得分进行排序。也就是说,duicc模型200已经确定具有较高偏好得分212(即,被用户104更偏好)的某些项目102可以在列表中排名更高。对由dlcc模块210输出的项目102的排名列表可以被排序,并且多个排名靠前的项目102可以作为推荐被呈现到用户104。
[0079]
与本概念一致,当用户104继续与项目102交互时,duicc模型200可以继续更新参数。当新用户104被引入到duicc环境100时,duicc模型200可以基于新用户与项目102的交互106为新用户104动态构建用户简档208。当新项目102被引入到duicc环境100时,duicc模型200可以更新协同聚类结构,包括重新训练项目嵌入204,使得新项目对协同聚类108的亲和分数110可以被计算。因此,可以实时地推断单个用户104(包括新用户104或具有新交互106的现有用户104)的偏好212,但是重新训练duicc模型200以考虑新项目102可能需要一些时间。例如,根据需要或需要,duicc模型200可以每天或每周针对新项目102被再训练。
[0080]
duicc模型的存储器复杂度和时间复杂度可能比传统推荐模型更有效。下表比较了一些示例模型的模型复杂性。
[0081]
表1
[0082][0083]
例如,duicc模型可能会按的顺序消耗存储器。传统的推荐模型,诸如贝叶斯个性化排序(“bpr”)、加权正则化矩阵分解(“wrmf”)、神经协作过滤/神经矩阵分解(neumf)和统一协作度量学习(“ucml”),会按的量级消耗存储器。因此,duicc模型可能比传统推荐模型消耗更少的存储器因为duicc模式可能不会显式存储对于大规模数据集合来说难以处理的用户表示和协同聚类分配
[0084]
此外,duicc模型从头开始推断用户简档的时间复杂度可能为的量级,而duicc模式从用户简档中增量添加或删除交互记录的时间复杂程度可能为的量级。相比之下,推断用户简档或从用户简档中增量添加或删除交互记录的时间复杂度,针对bpr和ucml是针对wrmf和neumf是因此,当从头推断用户简表以及从用户简
表中增量添加和删除交互记录时,duicc模型可能比传统推荐模型显著更快。
[0085]
与当前的概念一致,duicc可能是端到端的推荐模型,其可以大规模检测和利用细粒度的协同聚类。此外,duicc可以拥有较低的在线服务成本,并可以动态更新用户简档,这针对需要快速适应新用户反馈的在线服务可能至关重要。
[0086]
duicc可以提供优于传统推荐算法的几个优点。首先,duicc可以提供推荐和协同聚类的统一方法。例如,duicc模型200可以包括dlcc模块210,以支持作为端到端推荐流水线的一部分的协同聚类。作为实体表示和监督之间的中间层,dlcc模块210可以学习与实体表示一起构建细粒度和重叠的用户-项目协同聚类。与要求单独且不可区分的聚类过程的传统方法不同,dlcc模块210可以提供统一的方式来联合优化推荐和协同聚类。来自实验(在下面被详细描述)的经验结果表明,dlcc模块210可以允许duicc模型200跨具有不同活动水平的用户显著提高在非常大和稀疏数据集合的准确性。具体而言,duicc在网络规模稀疏数据集合上的表现优于竞争基线47.5%(平均倒数排名(mrr)),同时在用户-项目交互更密集的数据集合上保持竞争性能。duicc即使在用户-项目交互稀疏的情况下也能够提供改进的推荐,因为潜在的协同聚类结构(即相似项目和相似用户的聚类)已经被检测到。
[0087]
其次,duicc可以在原生支持针对实时推荐的高效推理。duicc可以通过基于注意力的项目集聚合器模块206来实现这一点,该项集聚合器模块206可以通过在常量时间内聚合项目嵌入来构建用户简档。这可以在新信息可用时实现实时推荐,并且在用户从简档中删除项目时提供高效和即时的方式来尊重隐私和数据管理。
[0088]
第三,duicc在训练期间可能具有很高的存储器效率,因为duicc不要求存储针对用户和项目的显式表示和协同聚类分配。因此,例如,duicc可以扩展到数十亿用户和数百万项目。
[0089]
最后,除了生成有助于推荐的协同聚类之外,duicc还可以发现可解释和连贯的协同聚类。因此,duicc可以以更丰富的方式提供建议。例如,duicc可以针对建议提供理由或解释。也就是说,用户可能会被告知提出推荐的原因:“由于您对kdd 2020cfp感兴趣,我们推荐知识发现和数据挖掘(kdd)2021研究论文征集(cfp)网站。”此外,duicc可以针对推荐项目提供结构。例如,被呈现给用户的推荐项目可以根据它们的协同集群隶属关系来分组,这可能比仅仅呈现推荐项的平面列表更可取。此外,根据协同聚类成员资格对推荐项目进行分组可以允许用户在协同聚类级别而不是项目级别上控制推荐(或提供反馈)。例如,用户可以通过gui提供输入以指示她不希望看到类似于呈现给她的一个或多个推荐项目的推荐,这可能适用一个或更多个协同聚类。
[0090]
一个实验被实施,以评估示例duicc模型与传统基线模型在推荐任务和协同聚类任务上的性能。实验的具体细节和示例duicc模型的具体实现仅被提供用于说明目的。与本概念一致的duicc模型不一定局限于本文描述的特定实现。许多其他的备选实现是可能的。
[0091]
对于实验,三个测试数据集合(web-35m、lastfm-17m和movielens-10m)被获得。web-35m数据集合记录了用户访问的网站主机,lastfm-17m数据集合纪录了听众播放某些艺术家歌曲的次数,movielens-10m数据集合则记录了用户对电影的评分,并将评分大于或等于4视为正面反馈。这三个测试数据集合的大小、稀疏性和分布各不相同,如表2所示。稀疏性可以被计算为条目数(即交互)除以用户数和项目数的乘积。
[0092]
表2
[0093][0094]
为了使用离线测试数据集合评估模型的推荐任务性能,使用了通用的保持范式,通过保持每个数据集合的一组用户及其交互进行验证和测试。在本实验中,web-35m数据集合的用户数为10000,lastfm-17m数据集合和movielens-10m数据集合用户数为10%,因此在训练期间,模型不会看到验证和测试集合中的用户。对于hold one-out评估,每个用户的最新交互被用于预测,其余的被用作模型的输入。选择验证集合上表现最佳的模型,并根据平均倒数排名(“mrr”)和命中率报告所选模型在测试集上的性能ratio@50(“hr@50“),如下表3所示。
[0095]
为了评估模型的项目协同聚类任务性能,使用人类判断测量项目-协同聚类一致性。人们从协同聚类和随机入侵者中得到一组三个项目,并被要求标识不属于其他项目的项目。每个协同聚类由五个不同的人标记。为了报告每种方法的总体精度,将每个协同聚类的平均精度计算为正确地标识入侵者的人的百分比,然后在所有100个协同聚类中对平均精度进行平均。
[0096]
本实验中使用的推荐任务基线包括流行度、基于用户的k最近相邻(“userknn”)、bpr、wrmf、neumf和ucml。本实验中使用的协同聚类任务基线包括x聚类与bpr、wrmf和neumf以及bigclam的组合。
[0097]
所有模型均训练了150个周期,学习率为0.001,并提前停止。也就是说,通过验证集合选择最佳训练迭代次数。为了控制表达能力,针对duicc模型和基线模型中嵌入,维度参数改变,d={32,64}。
[0098]
针对duicc模型,每个1024个最小批次的1000个负数项被采样,并且每50个轮次学习率除以10。针对模型选择的超参数如下:α∈{0.1,0.05}、λ∈{1e-6,1e-4}和n={512,1024,2048}。duicc模型使用tensorflow实现,并在四张nvidia tesla p100显卡上进行了训练,这一过程花费不到两天完成。
[0099]
包括bpr、wrmf、neumf和ucml的基线模型,使用openrec库实现,并且用不同级别的l2正则化(0,1e-6、1e-5、1e-4)进行了试验。在推断中,除用户嵌入外,所有模型参数都被冻结,并且使用验证或测试数据集针对150个轮次被微调。
[0100]
对于x-聚类,最小批次k平均被用于将用户和项联合分组到2048个聚类中。k平均被运行三次,并且根据惯性选择最佳结果。对于bigclam,原始实现和建议的参数设置被采用来检测2048个协同聚类。
[0101]
下表3呈现了留出一个推荐任务的实验结果。每列的最佳结果用斜体表示。该参数d表示项目嵌入ei的维度。
[0102]
表3
[0103][0104][0105]
duicc模型在web-35m和lastfm-17m数据集合上的显著优于基线模型,在movielens-10m数据集合的表现具有竞争力。在mrr和hr@50指标下,并且与潜在表示的维度大小d无关,duicc模型在web-35m和lastfm-17m数据集合上显著优于的所有基线,随着交互信号变得更稀疏,增益变得更大(见上文表2中三个数据集合的稀疏性)。此外,duicc模型在推断过程中实现了每个用户的常量时间的提升,而其他基线则要慢得多。然而,在movielens-10m数据集合上,userknn、bpr、wrmf和duicc模型表现接近(差异小于1%)。这可能表明,高级方法(诸如,神经架构)不一定能提高密集数据集合的性能,并且可能会出现过度拟合。
[0106]
为了评估模型在推理过程中在不同的数据可用性级别下的表现,在测试过程中使用的交互次数针对交互次数超过20次的用户是不同的。结果表明,duicc模型在被观察到的针对用户交互的各种数量上优于所有基线,并且随着更多交互数据可用(d=64),duicc模型的性能被改善。因此,随着更多交互数据可用(即,随着推理时用户交互次数的增加),duicc模型的推荐性能会提高。
[0107]
此外,当协同聚类的数量(n)增加时,duicc模型的性能提高,从而使模型具有更大的细粒度聚类能力。因此,duicc模型的推荐性能将随着协同聚类数量(n)的增加而提高。
[0108]
duicc模型在实验中的出色推荐性能表明,其被检测到的协同聚类对推荐非常有用。实验结果表明,duicc模型具有最高的平均精度一致性,同时也生成了大量有效的项目协同聚类。
[0109]
关于协同聚类任务,duicc模型和wrmf是精度方面表现最好的两个模型,指示这两个模型产生了语义上有意义的项目嵌入,并且在所有被测试模型中产生了最连贯的项目协同聚类。然而,尽管wrmf聚类善于发现连贯的项目协同聚类,但与duicc模型相比,它检测到的有效协同聚类数量(约三分之一)要少得多。(有效的协同聚类被定义为至少有20个用户和20个项目。)与wrmf相比,duicc模型检测到的有效协同聚类数量更高,这可以被解释为duicc模式在保持可比精度的同时标识出更多细粒度的协同聚类。这种更细粒度的协同聚类可能是解释duicc模型在推荐方面优于wrmf的一个因素。
[0110]
图5示出了说明与本概念一致的duicc方法500的流程图。此示例duicc方法500是为了说明目的而被呈现的并且不意味着是穷举的或限制性的。duicc方法500中的动作可以按被呈现的顺序、以不同的顺序、或者并行或同时执行,或者可以被省略。
[0111]
在动作502中,用户和项目之间的交互可以被接收。交互可以包括针对每个用户的项目集合,指示特定用户过去曾与该项目集合交互。在一个实现中,交互可以是duicc模型的输入。
[0112]
在动作504中,项目嵌入可以被生成。项目嵌入可以基于在动作502中接收的交互中的项目而生成。项目嵌入可以是项目的向量表示。在一个实现中,项目嵌入可以被随机初始化以在训练期间被微调。
[0113]
在动作506中,可以生成用户嵌入。对于每个用户,可以基于用户已经与之交互的项目的项目嵌入来生成用户嵌入(或用户简档)。例如,在一种实现方式中,如上文结合图3和公式2所解释的,协同聚类条件注意力机制可以被使用来通过聚合项目嵌入来针对用户构建用户嵌入。
[0114]
在动作508中,协同聚类可以被检测。也就是说,可以通过确定每个项目和每个用户对预设数量的协同聚类的亲和来学习协同聚类结构。例如,在一个实现中,如上文结合图4和公式5-公式7所解释的,用户和项目的协同聚类指派可以被随机初始化,然后使用依赖于项目-协同聚类亲和得分和用户-协同聚类亲和得分两者的损失函数进行微调。可选地,项目对协同聚类的的亲和得分和用户对协同聚类的亲和得分(即,潜在协同聚类结构)可以由duicc模型作为协同聚类任务输出来输出。
[0115]
在动作510中,针对项目的偏好得分可以被计算。也就是说,针对一个用户或所有用户每个项目的偏好得分(即,用户希望与项目交互的可能性)被计算。例如,在一个实现中,如上文结合图4和公式8所解释的,用户的协同聚类成员资格和项目的协同聚类成员资
格之间的重叠量可以针对所有协同聚类被聚合,以计算针对用户和项目的偏好分数。可选地,由duicc模型输出的针对一个用户或所有用户的偏好得分作为推荐任务被输出。
[0116]
在动作512中,推荐的项目可以被提供给用户。在一个示例实现中,基于在动作508中针对用户计算的偏好得分项可以被排序或被排名。所有排名的项或项的排名靠前的子集可以作为推荐项被发送给用户(或用户的设备)。推荐的项目可以在gui上被呈现给用户用于消费或交互。
[0117]
图6示出了与本概念一致的示例duicc系统600。出于解释的目的,duicc系统600可以包括设备602。设备602的示例可以包括个人计算机、台式计算机、服务器、笔记本计算机、蜂窝电话、智能电话、个人数字助理、平板电脑或板式电脑、移动计算机、相机、电器、虚拟现实耳机、视频游戏主机、控制器、智能设备、物联网(iot)设备、车辆、手表、可穿戴设备、机顶盒、游戏系统、汽车娱乐或导航控制台等,和/或各种不断发展或尚未开发的电子设备。
[0118]
在图6所示的示例中,设备602可以包括服务器设备602(1)(或服务器集合)、笔记本计算机602(2)、平板电脑602(3)和智能手机602(4)。出于解释的目的,设备602(1)可以被视为服务器端设备604(或基于云的资源),并且设备602(2)-602(4)可以被视为客户端设备606(或客户端设备)。所描述和所描绘的设备602的数目以及设备602的客户端对服务器端旨在是说明性的和非限制性的。设备602可以经由一个或多个网络608彼此通信和/或可以通过一个或多个网络608访问互联网。
[0119]
本文中使用的术语“设备”、“计算机”或“计算设备”可以指具有一定处理能力和/或存储能力的任何类型的设备。处理能力可以由一个或多个硬件处理器提供,该硬件处理器可以读取计算机可读指令形式的数据以提供功能。数据,诸如计算机可读指令和/或用户相关数据,可以被存储在存储上,诸如可以在设备内部或外部的存储。存储可以包括易失性或非易失性存储器、硬盘驱动器、闪存设备、光学存储设备(例如,cd、dvd等)和/或远程存储(例如,基于云的存储)等中的任何一个或多个。如本文所用,术语“计算机可读介质”可以包括瞬时传播信号。相反,术语“计算机可读存储介质”不包括瞬时传播信号。计算机可读存储介质可以包括计算机可读存储设备。计算机可读存储设备的示例可以包括易失性存储介质(诸如ram)以及非易失性存储器介质(诸如硬盘驱动器、光盘和闪存等)。
[0120]
在一些实现中,服务器端设备604、客户端设备606和/或组合可以执行duicc方法500的全部或部分以及本文描述的其他动作。例如,用户-项目交互数据可以由用户用来与一个或多个项目交互或消费一个或多个项目的客户端设备606收集。服务器端设备604可以接收用户的标识并且将推荐项目列表发送到客户端设备606以呈现给用户。推荐项列表可以伴随着由duicc模型确定的偏好得分和/或那些推荐项的协同聚类分配。在一个示例实现中,服务器端设备604可以执行duicc模型的训练,并且客户端设备606可以执行推断(提供推荐)。在另一示例实现中,duicc模型可以在客户端设备606上运行。例如,客户端设备606可以从服务器端设备604传输duicc模型的子集。取决于客户端设备604的存储和处理能力,可以通过针对较小的嵌入设置较小的维度来使用较小的duicc模型。客户端设备604上的duicc模型可被用于推断推荐。
[0121]
图6示出了可以由任何或所有设备602采用的两个示例设备配置610(1)和610(2)。单个设备602可以使用配置610(1)或610(2)中的任何一个,也可以使用备选配置。每个配置610的一个实例如图6所示。配置610(1)可以表示以操作系统(“os”)为中心的配置。配置610
(2)可以表示片上系统(“soc”)配置。配置610(1)可以被组织成一个或多个应用612、操作系统614和硬件616。配置610(2)可以被组织成共享资源618、专用资源620和它们之间的接口622。
[0122]
在任一配置610中,设备602可以包括存储设备624和处理器626。设备602还可以包括duicc模型628。例如,duicc模型628可以是上述duicc200模型或类似模型。
[0123]
如上所述,配置610(2)可以被认为是soc型设计。在这种情况下,设备602提供的功能可以集成在单个soc或多个耦合的soc上。一个或多个处理器626可以被配置为与共享资源618(诸如存储器624等)和/或一个或更多个专用资源620(诸如被配置为执行特定功能的硬件块)协调。因此,本文中使用的术语“处理器”还可以指中央处理单元(cpu)、图形处理单元(gpu)、控制器、微控制器、处理器核或其他类型的处理设备。
[0124]
来自duicc模型200的输出可以例如由客户端设备606使用gui以图形形式被呈现给用户。例如,由duicc模块200确定的项目102的协同聚类108可以作为项目102的分组被呈现给用户。类似地,由duicc模型200确定的用户104的协同聚类108可以作为用户104的分组被呈现给用户。如上所述,由duicc模型200确定的项目102和/或用户104的分支比由传统技术确定的分组更准确、更可靠和更类似,因为与当前概念一致的协同聚类是基于实际的过去消费行为。也就是说,与项目有相似交互的用户倾向于被分组在一起,而由相似用户消费的项目倾向于被组合在一起。此外,如上所述,与传统技术相比,客户端侧设备606可以生成图形内容并呈现项目102和/或用户104的分组即使只有稀疏数据,即,即使只具有项目102和用户104之间的少量交互。此外,如上所述,duicc模型200的时间复杂度优于传统技术,这使得能够更有效地使用计算资源,并且能够更快地提供项目102和用户104的协同聚类。
[0125]
此外,项目102的排名列表(或排名靠前的项目102的子集)可以在gui中被呈现给用户。例如,客户端设备606可以生成包括排名靠前的项目102的集合的图形内容。与本概念一致,这些排名项目102是使用基于许多用户和项目的实际过去消费行为计算的亲和得分来确定的,因此比传统技术推荐的项目更准确,更可能是首选。因此,由客户端设备606呈现的排名靠前的项目102更可能导致用户交互。此外,客户端设备606可以体验与呈现的甚至更少的项目102的用户交互,并且因此可以从服务器端设备604请求更少的项目,这节省了带宽使用并防止了网络拥塞。此外,能够以更高的用户交互置信度呈现项目意味着需要呈现的项目更少,从而节省了屏幕空间。或者,可以通过在屏幕上更突出地调整排名最高的项目102的大小来利用保存的屏幕空间,以进一步鼓励用户与那些项的交互。
[0126]
通常,本文描述的任何功能都可以使用软件、固件、硬件(例如,固定逻辑电路)或这些实现的组合来实现。本文中使用的术语“组件”或“模块”通常表示软件、固件、硬件、整个设备或网络或其组合。例如,在软件实现的情况下,这些可以表示在处理器(例如,cpu或多个cpu)上被执行时执行指定任务的程序代码。程序代码可以被存储在一个或多个计算机可读存储设备中,诸如计算机可读存储介质。组件或模块的特征和技术与平台无关,这意味着它们可以在具有各种处理配置的各种商业计算平台上被实现。
[0127]
图6所示的duicc系统600仅仅是一个示例。duicc系统600不需要包括结合图6描述的所有示例性元件,并且duicc系统600还可以包括结合图6未显示描述的附加元件。
[0128]
本概念具有非常广泛的应用,因为项目的类型和交互的类型不受限制或约束。除了上面提供的示例项目和示例交互的列表之外,另一示例应用可以包括duicc模型,其接收
表示用户已经点击的广告的交互数据以推荐用户最有可能想要与之交互的附加广告。这样的duicc模型可以帮助增加广告收入以及增强用户体验。作为另一个示例,duicc模型可以处理组织(例如,公司)中的员工已经与之交互的内容(文档、文件、url、联系人、门户、网页等),以学习员工和内容的聚类或组,并且向员工提供他们可能想要查看的内容推荐。这样的duicc模型可以帮助提高组织的生产率。
[0129]
本概念提供了可以统一推荐和协同聚类的duicc。duicc可以利用这样的观察,即用户的消费行为可以通过将相关用户和相关项目联系在一起的底层协同聚类集来解释。实验结果表明,duicc在计算上是有效的,并且在稀疏数据集合上表现出很强的推荐性能。因此,duicc可以实现在线推理,并产生可解释的并且连贯的项协同聚类。duicc还可以允许使用协同聚类用于解释、直接在协同聚类级别上获取偏好以及检测协同聚类中的信息孤岛(即,协同聚类中广为人知的信息,但其他地方的受限知识)。
[0130]
以上已经描述了各种示例。尽管已经用特定于示例结构特征和/或方法行为的语言描述了主题,但所附权利要求中定义的主题不一定限于上述特定特征或动作。相反,上述特定特征和动作被呈现为实现权利要求的示例形式,并且本领域技术人员将认识到的其他特征和动作旨在权利要求的范围内。
[0131]
以上描述了各种示例。其他示例如下所述。一个示例包括:系统,该系统包括处理器和存储指令的存储设备,当指令由处理器执行时,这些指令使处理器:接收用户和项目之间的交互,基于该交互,训练机器学习模型以通过以下方式来检测所述用户和所述项目的协同聚类:生成表示项目的项目嵌入,生成表示用户的用户嵌入,以及基于项目嵌入、用户嵌入以及表示协同聚类的协同聚类嵌入来计算项目对协同聚类的项目-协同聚类亲和得分以及用户对协同聚类的用户-协同聚类亲和得分,以及输出项目-协同聚类亲和得分和用户-协同聚类亲和得分。
[0132]
另一示例可以包括上面和/或下面的示例中的任何一个,其中指令还使处理器:通过以下方式来生成表示特定用户的特定用户嵌入:根据交互,聚合表示特定用户已经交互过的特定项目的特定项目嵌入。
[0133]
另一个示例可以包括上面和/或下面的示例中的任何一个,其中用于聚合特定项目嵌入的计算时间是按常量时间的量级。
[0134]
另一个示例可以包括上面和/或下面的任何示例,其中特定用户嵌入是特定项目嵌入的加权和。
[0135]
另一个示例可以包括上面和/或下面的示例中的任何一个,其中机器学习模型使用针对协同聚类中的每个协同聚类的注意力头来生成用户嵌入。
[0136]
另一个示例可以包括上面和/或下面的任何示例,其中用户嵌入是使用线性投影生成的。
[0137]
另一个示例可以包括上面和/或下面的任何示例,其中机器学习模型通过将项目嵌入和用户嵌入协同聚类到协同聚类中来检测协同聚类。
[0138]
另一个示例可以包括上面和/或下面的示例中的任何一个,其中机器学习模型通过以下方式来检测协同聚类:基于项目嵌入和协同聚类嵌入来计算项目-协同聚类亲和得分,以及基于用户嵌入和协同聚类嵌入来计算用户-协同聚类亲和得分。
[0139]
另一示例可以包括以上和/或以下示例中的任何一个,其中计算针对特定项目和
特定协同聚类的特定项目-协同聚类亲和得分包括:计算表示特定项目的特定项目嵌入和表示特定协同聚类的特定协同聚类嵌入的点积,以及计算针对特定用户和特定协同聚类的特定用户-协同聚类亲和得分包括:计算表示特定用户的特定用户嵌入和特定协同聚类嵌入的点积。
[0140]
另一个示例可以包括上面和/或下面的任何示例,其中使用softmax分类损失函数训练机器学习模型。
[0141]
另一示例可以包括上面和/或下面的示例中的任何一个,其中通过留出特定用户已经交互过的项目集合中的单个项目,以及使用尚未留出的项目集合来使用softmax分类损失函数来训练机器学习模型,以正确地预测已经留出的单个项目。
[0142]
另一示例包括存储指令的计算机可读存储介质,当由处理器执行时,该指令使得处理器:接收与特定用户相关联的用户标识,基于由机器学习模型确定的用户-协同聚类亲和得分和项目-协同聚类亲和得分来计算与特定用户的项目相关联的偏好得分,该机器学习模型接收项目和用户之间的交互,提供表示项目的项目嵌入,通过聚合项目嵌入来生成表示用户的用户嵌入,以及基于用户嵌入和项目嵌入来检测项目和用户的协同聚类,并且基于偏好得分来输出针对特定用户的项目集合。
[0143]
另一示例可以包括上面和/或下面的示例中的任何一个,其中指令还使处理器接收特定用户和特定项目之间的新交互;以及使用机器学习模型、基于特定项目来更新表示特定用户的特定用户嵌入。
[0144]
另一示例可以包括上面和/或下面的示例中的任何一个,其中用于更新特定用户嵌入的计算时间是按常量时间的量级。
[0145]
另一示例可以包括以上和/或以下示例中的任何一个,其中指令还使处理器基于与特定项目相关联的时间值从与特定用户相关联的特定交互中移除特定项目,以及使用机器学习模型、基于特定项目的移除来更新表示特定用户的特定用户嵌入。
[0146]
另一示例包括一种方法,该方法包括接收特定用户的标识,基于用户和项目的协同聚类来计算与特定用户的项目相关联的偏好得分,协同聚类由机器学习模型根据用户和项目之间的交互来检测,机器学习模型计算用户对协同聚类的用户-协同聚类亲和得分和项目对协同聚类的项目-协同聚类亲和得分,并基于所述偏好得分输出特定用户的项目集合。
[0147]
另一示例可以包括以上和/或以下示例中的任何一个,其中基于特定用户对协同聚类的特定用户-协同聚类亲和得分和项目-协同聚类亲和得分来计算偏好得分。
[0148]
另一示例可以包括上面和/或下面的示例中的任何一个,其中计算偏好得分包括基于特定用户-协同聚类亲和得分和项目-协同聚类亲和得分使用最小和池化操作。
[0149]
另一示例可以包括上面和/或下面的任何示例,其中计算与针对特定用户的特定项目相关联的特定偏好得分包括计算特定项目和特定用户之间关于协同聚类的重叠。
[0150]
另一个示例可以包括上面和/或下面的示例中的任何一个,其中该方法还包括基于协同聚类在组中重新呈现该项目集合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1