具有小占有面积算术逻辑单元的处理单元的制作方法
具有小占有面积算术逻辑单元的处理单元
1.相关申请的交叉引用
2.本技术要求于2020年6月26日提交的题为“具有小占有面积算术逻辑单元的处理单元(processing unit with small footprint arithmetic logic unit)”的临时专利申请第63/044,544号的优先权,该临时专利申请的全部内容以引用方式并入本文。
背景技术:
3.随着计算操作的增长,更复杂的处理器越来越多地采用专门设计和配置成代表处理器执行指定操作的处理单元。例如,为了有效地执行人工智能、机器学习和类似操作,一些处理器采用具有多个处理元件(通常也被称为处理器内核或计算单元)的一个或多个人工智能(ai)加速器,该多个处理元件同时对多个数据集执行单个程序的多个实例。处理器的中央处理单元(cpu)向ai加速器提供命令,并且ai加速器的命令处理器(cp)将这些命令解码成一个或多个操作。加速器的执行单元诸如一个或多个算术逻辑单元(alu)执行该操作以执行人工智能功能和类似操作。
附图说明
4.通过参考附图,本公开被更好地理解,并且其许多特征和优点对于本领域技术人员是显而易见的。在不同附图中使用相同的附图标记表示类似或相同的项目。
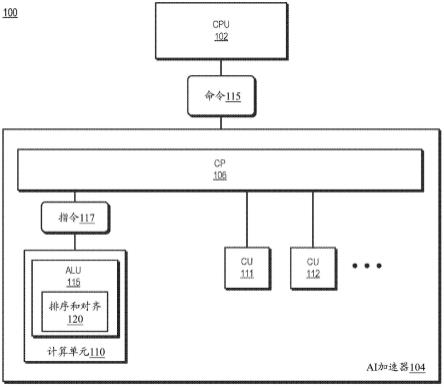
5.图1是根据一些实施方案的包括具有算术逻辑单元(alu)的处理单元的处理器的框图,该算术逻辑单元(alu)具有相对小的占有面积。
6.图2是根据一些实施方案的具有在将alu操作数传递到alu的另一级之前缩减该操作数的大小的排序和对齐级的图1的alu的框图。
7.图3是根据一些实施方案的图2的alu的框图,例示了在将alu操作数传递到alu的另一级之前该操作数的大小的示例性缩减。
8.图4是根据一些实施方案的缩减处理单元的alu处alu操作数的大小的方法的流程图。
具体实施方式
9.图1到图4例示了系统和技术,其中并行处理单元诸如人工智能(ai)加速器采用具有相对小占有面积的算术逻辑单元(alu),由此缩减处理单元的总功耗和电路面积。为了支持更小的占有面积,alu包括多个级用于执行对应于所接收指令的操作。alu以所接收指令所指示的精度执行至少一个操作,然后在将结果提供到alu的另一级以继续执行指令之前将该至少一个操作的所得数据(即,中间结果)缩减到更小的大小,并且对于每个连续级以此类推。因为这些中间结果的大小被缩减,所以alu的后续级能够采用相对小的寄存器和更少量的其它电路来支持其对应操作,由此缩减alu的总大小和功耗。
10.为了经由示例进行例示,在一些实施方案中,alu包括用于实施乘法-累加指令(诸如点积指令)的级,其中乘法器级将n组操作数相乘以生成n个乘积,并且加法器级将这n个
乘积加在一起以生成最终点积结果。alu包括位于乘法器级与加法器级之间的对齐级,其缩减这n个乘积的大小。例如,在一些实施方案中,对齐级标识这n个乘积中的最大乘积,并且通过移位对应的尾数将其他乘积与最大乘积对齐。在移位处理期间,尾数的较低有效位被丢弃,使得每个尾数被设置为指定大小(例如32位)。相比之下,常规alu在对齐级处采用相对大的尾数(例如,80位或更多的尾数)以确保最终点积结果的全精度,从而需要加法器级使用大的寄存器和更大数量的加法器元件,并且因此消耗更大量的功率和电路面积。
11.图1例示了根据一些实施方案的具有小占有面积alu的处理器100的框图。处理器100通常被配置为执行指令集(例如,计算机程序),以便代表电子设备执行指定任务。因此,在不同的实施方案中,处理器100是台式计算机、膝上型计算机、平板计算机、服务器、游戏机、智能电话等的一部分。为了支持代表电子设备的指令执行,处理器100包括中央处理单元(cpu)102和人工智能(ai)加速器104。在一些实施方案中,处理器100包括附加的模块和电路(未在图1中示出)用于支持指令执行,诸如存储器模块(例如,包括一个或多个高速缓存的存储器层级)、输入/输出(i/o)接口、附加的处理单元(诸如图形处理单元(gpu))等等。
12.为了有效地执行指令集,处理器100通常向cpu 102和ai加速器104分配不同类型的操作。因此,在一些实施方案中,cpu 102执行用于处理器100的通用操作,包括从存储器取指令集、将那些指令解码成操作集、执行该操作以及退返所执行的指令。这些通用操作的示例是执行操作系统以执行对电子设备的管理操作,诸如存储器管理、为电子设备提供用户界面等。
13.与由cpu 102执行的通用操作相反,ai加速器104包括用于有效地执行与人工智能操作相关联的操作(诸如与机器学习、神经网络、推理引擎、专家系统、深度学习等相关联的操作)的模块和电路。因此,在不同实施方案中,ai加速器104是用于执行与人工智能相关联的操作的多个处理单元中的一者,诸如矢量处理单元、图形处理单元(gpu)、通用gpu(gpgpu)、非标量处理单元、高度并行处理单元、ai处理单元、推理引擎、机器学习处理单元、神经网络处理单元、其它多线程处理单元等。
14.为了支持ai操作的执行,ai加速器104包括命令处理器(cp)106和多个计算单元,包括计算单元(cu)110、111和112。命令处理器106从cpu 102接收命令(例如,命令118),其中每个命令指示要在ai加速器104处执行的一个或多个ai操作。例如,在不同实施方案中,命令118指示神经网络操作(例如,用于神经网络训练的卷积操作、推理操作等)、机器学习操作、矢量处理操作等或其任何组合中的一者或多者。cp 106解释该命令以生成一个或多个指令(例如,指令117),其中该指令描绘要执行的ai操作。
15.计算单元110-112各自包括用于执行由cp 106生成的指令的电路。因此,在一些实施方案中,计算单元110、112中的每一者包括一个或多个矢量流处理器(vsp)、单指令多数据(simd单元)、或其他处理元件、或其任何组合以执行所接收的指令。在一些实施方案中,为了提高处理效率,cp 106将指令组织成指定的集(有时称为波前或翘曲),并且根据指定的调度标准将波前分配给计算单元110-112中的不同计算单元。每个计算单元与其它计算单元并行地执行该波前的其所分配部分。
16.例如,假设波前用于以相对大集合的数据元素(诸如表示神经网络的方面的大矩阵的元素)执行指定集合的数学操作。为了执行该波前,cp106将该矩阵的元素的不同子集分配给不同的计算单元,并且每个计算单元以对应的所分配的元素子集并行地执行该指定
集合的数学操作。计算单元由此对该大集合的数据元素有效地执行该数学操作。
17.为了执行数学操作,每个计算单元包括一个或多个alu,诸如计算单元110的alu 115。在一些实施方案中,计算单元110包括指令流水线(未示出),该指令流水线包括用于支持指令执行的附加级,包括用于从指令缓冲器取指令的取指级、解码级、除alu 115之外的执行单元、以及用于退返已执行指令的退返级。解码级包括用于将从取指级接收的指令(例如,指令117)解码成一个或多个操作并且根据操作的类型将该操作分派给执行单元中的一者的电路。在一些实施方案中,每个操作由对应的操作码标识,并且解码级基于操作码标识执行单元并将指示操作码的信息提供给执行单元。执行单元采用操作码或基于操作码的信息来确定要执行的操作的类型,并执行所指示的操作。
18.例如,一些操作以及相关联的操作码指示算术操作。响应于标识出所接收的指令指示算术操作,解码级确定用于该操作的操作码并将该操作码连同其它信息诸如要用于该算术操作的操作数一起提供给alu 115。alu115利用存储在寄存器文件或其它存储器位置处的所指示的操作数来执行由操作码指示的操作。在一些实施方案中,由alu 115提供的操作指示操作数的精度和要执行的操作。例如,在一些实施方案中,解码级提供利用16位操作数的16位乘法操作的一个操作(以及对应的操作码),并且提供利用32位操作数的32位乘法操作的另一操作(以及对应的操作码)。
19.另外,解码级以对应的操作码生成用于混合精度数学操作的操作,其中混合精度操作采用不同大小的操作数。例如,在一些实施方案中,解码级基于对应的指令生成乘法-累加(macc)操作,该乘法-累加操作将一个大小(例如,16位)的操作数相乘并将结果与另一大小(例如,32位)的操作数累加。例如,在一些实施方案中,该操作包括混合精度点积操作(表示为dot4_f32_f16),其将四组两个16位浮点操作数相乘并且将乘法结果彼此相加并加到32位浮点操作数。
20.alu 115包括用于执行不同数学操作的不同级,诸如包括用于执行乘法操作的一个或多个乘法器的乘法级以及用于执行加法的加法级。对于更复杂的数学操作诸如dot4_f32_f16操作,alu采用不同的级来执行对应的操作并将结果从一级传递到另一级。例如,为了执行dot4_f32_f16操作,alu 115在乘法级处执行乘法操作并且在加法器级处执行加法操作。
21.常规地,为了维持数学操作的全精度,alu在每一级处维持相对大的操作数。例如,80位尾数用于乘法乘积以维持dot4_f32_f16操作的全精度。即,为了维持dot4_f32_f16操作的全精度,alu通常利用80位或更高尾数存储由乘法级生成的乘积。利用这些相对大的操作数消耗相对大量的电路面积和功率,诸如通过在alu 115的加法器级处需要更大的寄存器和更高数量的加法元件。然而,对于一些类型的操作,包括ai操作,维持这些相对大的尾数并不改善操作的总体结果。例如,在一些情况下,ai操作所采用的数据操作数为相对低精度操作数,从而以高精度维持操作数不会有意义地影响ai操作的总体结果。
22.为了降低功耗以及支持相对小的占有面积,alu 115包括排序和对齐级120,其在由alu 115的一个级生成的操作数被传递到下一级之前缩减那些操作数的大小。例如,在一些实施方案中,对于dot4_f32_f16操作,排序和对齐级120在将由乘法级生成的尾数提供给加法器级用于相加之前缩减那些尾数的大小。
23.为了例示,在一些实施方案中,排序和对齐级120从乘法级接收乘积,其中每个乘
积是由指定大小的尾数(例如,32位尾数)和对应的指数表示的浮点操作数。排序和对齐级120将每个尾数存储在对应于指定尾数大小的寄存器中(例如,32位寄存器用于存储32位尾数)。排序和对齐级120标识所接收乘积中的最大乘积。对于其它乘积,排序和对齐级120移位尾数并对对应的指数进行相应调节,直到每个乘积具有与最大乘积相同的指数。在移位过程期间,每个尾数被保持在尾数寄存器中,使得在一些情况下,尾数的较低有效位被移位出寄存器并且被组合以形成用于每个尾数的对应粘着位。换句话说,尾数中的至少一些在总体大小或位宽上被缩减,以将每个尾数维持在相对小的寄存器中。
24.在移位和指数调节之后,排序和对齐级120将操作数提供给加法器级以执行乘积的相加。如上所述,由于移位和指数调节,乘积的尾数被保持在相对小的寄存器中。因此,加法器级能够采用相对小数量的加法器元件来执行乘积的相加,由此支持alu 115的小占有面积。
25.图2是根据一些实施方案更详细地例示alu 115的框图。在所描绘的示例中,alu 115包括多个矩阵乘法器(“mm”)230、231、232和233、累加器234、排序和对齐级120、融合加法器238、以及归一化和舍入级239。矩阵乘法器230-233和累加器234形成alu 115的乘法级。特别地,对于浮点点积操作(例如,dot4_f32_f16操作),矩阵乘法器230-233中的每一者接收对应的一组浮点输入操作数并且以所接收的操作数执行浮点乘法以生成乘积(例如,乘积240)。
26.累加器234存储或生成恒定值c,该恒定值c将被加到由矩阵乘法器230-233生成的乘积。在一些实施方案中,恒定值c是由点积操作标识的操作数,累加器234是存储所标识的操作数的寄存器。在其他实施方案中,恒定值c是基于在计算单元110处执行的其他操作的累加值,并且累加器234包括用于执行恒定值c的累加的电路。
27.排序和对齐级120接收来自矩阵乘法器230-233的乘积和来自累加器234的恒定值c,并且经由排序和对齐过程准备这些操作数以进行相加。为了支持排序和对齐过程,排序和对齐级120包括操作数大小模块222和操作数移位模块224。操作数大小模块222包括用于标识所接收乘积和恒定值c中哪一者具有最大值的电路。操作数移位模块224包括用于移位所接收操作数并且对对应的指数进行相应调节使得每个操作数与由操作数大小模块222标识的最大操作数对齐的电路。
28.为了经由示例进行例示,在一些情况下,操作数大小模块222将乘积240标识为是最大操作数,具有指数值n。操作数大小模块222还将被指定为乘积a的另一乘积标识为小于乘积240,具有指数值n-2。操作数移位模块224将乘积a的指数调节为值n,并且相应地将乘积a的尾数向右移位两位,使得两个最低有效位被移位出尾数。在一些实施方案中,操作数移位模块224经由逻辑“或”操作组合被移位出的位以生成用于被移位的尾数的粘着位。
29.操作数移位模块224的移位结果是所有乘积和恒定值c被对齐以用于相加。如上所述,在移位过程期间,至少一些乘积的较低有效位被丢弃,使得所有乘积被维持在指定大小的寄存器(例如,32位寄存器)中。在一6些情况下,移位导致乘积具有比点积操作所要求的精度更低的精度。例如,在一些实施方案中,为了符合指定的指令集架构(例如,x86指令集架构),点积操作指示与操作相关联的精度,诸如指定单精度操作或双精度操作。为了确保指定的精度,传统的alu在排序和对齐级处采用大的寄存器,使得在排序和对齐过程期间不丢弃尾数位。相反,排序和对齐级120允许在移位和对齐过程期间丢弃尾数位,使得尾数被
保持在相对小的寄存器中。
30.融合加法器238从排序和对齐级120接收经对齐的乘积241(包括经对齐的恒定值c)。融合加法器238将经对齐的乘积241的尾数值相加以生成用于结果尾数的临时值。为了将尾数值相加,融合加法器238包括多个加法器元件,其中每个加法器元件将对应尾数的至少两个位相加。如上所述,因为经对齐的乘积241的尾数被保持在相对较小的寄存器中,所以融合加法器238采用相对较少的加法器元件,由此支持alu 115的缩减的占有空间和较低的功耗。
31.融合加法器238将临时尾数值提供给归一化和舍入级239,其归一化临时尾数值。例如,在一些实施方案中,归一化和舍入级239移位临时尾数值以移除尾数中的任何前导零。在一些实施方案中,归一化和舍入级239调节临时尾数以迫使临时尾数的整数部分为指定值(例如,1)。基于对尾数进行的调节,归一化模块调节所提供的临时指数值以保留浮点结果值的总值。
32.在归一化之后,归一化和舍入级239基于指定的舍入规则对结果进行舍入,诸如将结果舍入到最接近的偶数值,由此生成最终结果245。
33.图3例示了排序和对齐级120对齐由矩阵乘法器230-233生成的乘积的尾数的示例。在所描绘的示例中,每个尾数被存储在对应的寄存器处,被指定为寄存器350、351、352、353和354。尾数从上到下按操作数大小的降序示出。因此,由矩阵乘法器232生成的操作数是最高操作数(即,具有最大值),并且对应的尾数(指定为m结果3)被存储在寄存器350处。由矩阵乘法器230生成的操作数是下一最高操作数,并且对应的尾数(指定为m结果1)被存储在寄存器351处。由矩阵乘法器233生成的操作数是下一最高操作数,并且对应的尾数(指定为m结果4)被存储在寄存器352处。由矩阵乘法器232生成的操作数是下一最高操作数,并且对应的尾数(指定为m结果2)被存储在寄存器353处。最后,由累加器234生成的操作数是最低操作数(具有最小值的操作数),并且对应的尾数(指定为acc结果)被存储在寄存器354处。
34.为了对齐操作数,排序和对齐级120移位每个操作数的指数,使得每个指数匹配最高操作数的指数。排序和对齐级120然后移位每个尾数以考虑对应的指数的变化。因此,例如,如果操作数的指数增加2,则移位和对齐模块120将对应的尾数向右移位两位位置。
35.用于不同尾数的对齐点中的分界由线359表示。即,线359表示所有尾数对齐的点。比最大操作数的尾数小的每个尾数被向右移位,使得尾数的某个部分位于线359的右侧。这些部分以灰色填充示出,并且表示用于形成尾数的粘着位并且然后被丢弃的尾数的位。因此,在所例示的示例中,对于m结果1操作数,排序和对齐级120将操作数向右移位,使得位355被提供给粘着位生成模块360以生成m结果1的粘着位。位355然后被丢弃,并且在相加期间不被融合加法器238使用。类似地,对于m结果4,位356用于形成对应的粘着位,然后被丢弃,对于m结果2,位357用于形成对应的粘着位,然后被丢弃,并且对于acc结果,位358用于形成对应的粘着位,然后被丢弃。
36.如图所示,表示位355-358的阴影区域具有不同的大小,指示对于每个对应的尾数,不同数量的位被移位出并丢弃。例如,在一些实施方案中,位355表示一个位,位356表示3个位,位357表示4个位,并且位358表示8个位。此外,在一些情况下,多于一个操作数具有最高指数,从而对应的尾数中多于一者在排序和对齐过程期间不被移位。
37.图4示出根据一些实施方案的通过在操作期间丢弃一个或多个操作数的一部分来在算术逻辑单元处执行点积操作的方法400。方法400是关于在图1的alu 115处的示例性具体实施来描述的。在框402处,alu 115接收指定精度的浮点操作数,诸如单精度或双精度操作数。在框404处,乘法器230-233将对应的操作数相乘以生成相应的乘积。另外,累加器234执行累加以生成恒定值c。
38.在框406处,排序和对齐级120确定乘积和恒定值c中的哪一者具有最大值。在框408处,排序和对齐级120调节每个乘积和恒定值c的指数,使得所有乘积和恒定值c具有匹配最高值的指数的指数。排序和对齐8级120然后移位每个尾数以对应于相应指数中的任何改变。如上所述,在移位期间,尾数中一者或多者的较低有效位被移位出,用于形成尾数的粘着位,然后被丢弃。在框410处,融合加法器238将经对齐的尾数相加,其然后被归一化和舍入级239归一化和舍入,以生成结果245。
39.如本文所述,在一些实施方案中,一种方法包括:响应于指令,在处理单元的算术逻辑单元(alu)处利用多个操作数经由该alu的对应的多个级执行多个数学操作;以及在该多个级中的第一级和第二级之间缩减该多个操作数中的第一操作数,其中缩减该第一操作数包括丢弃该第一操作数的至少一部分。在一个方面中,该方法包括:在该多个级中的该第一级和该第二级之间缩减该多个操作数中的第二操作数,其中缩减该第二操作数包括丢弃该第二操作数的至少一部分。在另一方面中,该第一操作数的被丢弃部分具有与该第二操作数的被丢弃部分不同的大小。在又一方面中,该指令是乘法-累加指令。在再一方面中,缩减该第一操作数包括在该alu的排序和对齐级处缩减该第一操作数。
40.在一个方面中,缩减该第一操作数包括通过移位该第一操作数的尾数以与第二操作数的尾数对齐来缩减该第一操作数。在另一方面中,移位该第一操作数的该尾数包括响应于确定该第二操作数是该多个操作数中的最大操作数而移位该第一操作数的该尾数以与该第二操作数的该尾数对齐。在又一方面中,该方法包括:基于该第一操作数的被丢弃部分而生成该第一操作数的粘着位。在再一方面中,该方法包括:将该第一操作数的经移位尾数加到该第二操作数。
41.在一些实施方案中,一种处理单元包括:包括多个级的算术逻辑单元(alu),该多个级用于基于所接收的指令并利用多个操作数执行对应的多个数学操作;并且其中该alu用于在该多个级中的第一级和第二级之间缩减该多个操作数中的第一操作数,其中缩减该第一操作数包括丢弃该第一操作数的至少一部分。在一个方面中,该alu用于在该多个级中的该第一级和该第二级之间缩减该多个操作数中的第二操作数,其中缩减该第二操作数包括丢弃该第二操作数的至少一部分。在另一方面中,该第一操作数的被丢弃部分具有与该第二操作数的被丢弃部分不同的大小。
42.在一个方面中,该指令是乘法-累加指令。在另一方面中,该alu包括排序和对齐级,用于缩减该第一操作数。在又一方面中,该排序和对齐级用于通过移位该第一操作数的尾数以与第二操作数的尾数对齐来缩减该第一操作数。在再一方面中,该排序和对齐级用于响应于确定该第二操作数是该多个操作数中的最大操作数而移位该第一操作数的该尾数以与该第二操作数的该尾数对齐。在另一方面中,该排序和对齐级用于基于该第一操作数的被丢弃部分而生成该第一操作数的粘着位。在又一方面中,该排序和对齐级包括用于将该第一操作数的经移位尾数加到该第二操作数的加法器。
43.在一些实施方案中,一种处理单元包括算术逻辑单元(alu),该算术逻辑单元包括:用于执行第一数学操作的第一级;用于通过丢弃由该第一级生成的第一操作数的一部分来缩减该第一操作数的第二级;和用于利用经缩减的该第一操作数执行第二数学操作的第三级。在一个方面中,该第一数学操作是乘法操作,并且该第二数学操作是加法操作。
44.在一些实施方案中,上述技术的某些方面由执行软件的处理系统的一个或多个处理器实现。软件包括可执行指令的一个或多个集合,该可执行指令存储在或以其他方式有形地体现在非暂态计算机可读存储介质上。软件可包括指令和某些数据,这些指令和数据在由一个或多个处理器执行时操纵一个或多个处理器以执行上述技术的一个或多个方面。非暂态计算机可读存储介质可包括例如磁盘或光盘存储设备、固态存储设备诸如闪存存储器、高速缓冲存储器、随机存取存储器(ram)或其他一个或多个非易失性存储器设备等。存储在非暂态计算机可读存储介质上的可执行指令能被实施在源代码、汇编语言代码、目标代码、或者被一个或多个处理器解释或能以其他方式执行的其他指令格式中。
45.应当注意,并非以上在一般描述中描述的所有活动或元件都是必需的,特定活动或设备的一部分可能不是必需的,并且可以执行一个或多个另外的活动,或者除了所描述的那些之外还包括元件。更进一步地,列出活动的顺序不一定是执行它们的顺序。另外,已经参考具体实施方案描述了这些概念。然而,本领域普通技术人员理解,在不脱离如以下权利要求中阐述的本公开的范围的情况下,可以进行各种修改和改变。因此,说明书和附图被认为是说明性的而非限制性的,并且所有此类修改旨在被包括在本公开的范围内。
46.上文已经关于具体实施方案描述了益处、其他优点和问题的解决方案。然而,益处、优点、问题的解决方案以及可以导致任何益处、优点或解决方案出现或变得更显著的任何特征不应被解释为任何或所有权利要求的关键的、必需的或基本的特征。此外,上文公开的特定实施方案仅是说明性的,因为所公开的主题可以以受益于本文中的教导内容的本领域的技术人员显而易见的不同但等效的方式来修改和实践。除了以下权利要求书中所描述的之外,不旨在对本文所示的构造或设计的细节进行限制。因此,显而易见的是,可以改变或修改上文公开的特定实施方案,并且所有此类变化被认为是在所公开的主题的范围内。因此,本文寻求的保护如以下权利要求中所阐述。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1