信息处理程序、信息处理方法以及信息处理装置与流程
本发明涉及信息处理程序等。
背景技术:
1、在db(data base:数据库)中登记有大量的数据,要求从db适当地检索利用者所希望的数据。
2、对进行数据检索的以往的服务器的一个例子进行说明。在服务器执行数据检索的情况下,以文档、项、句子等各种粒度进行检索,但这里为了方便说明,对检索与检索查询类似的句子的服务器进行说明。
3、服务器预先使用定义了单词的矢量的静态词典等,计算db所包含的各句子的矢量,生成表示句子的矢量与句子在db上的位置的关系的转置索引。例如,服务器通过累计句子所包含的单词的矢量来计算句子的矢量。服务器若受理检索查询,则与计算句子的矢量的情况相同地计算检索查询的矢量,将检索查询的矢量与转置索引进行比较,确定出与检索查询类似的句子的位置。
4、这里,静态词典是定义规定的单词与和该单词对应的矢量的关系的词典。以往的服务器针对表示静态词典中未设定的单词的未知词使用cbow(continuous bag-of-words:连续词袋模型)等技术对未知词分配矢量。cbow是基于在对象单词的前后出现的单词,计算对象单词的矢量的技术。
5、专利文献1:日本特开2017-194762号公报
6、专利文献2:日本特开2018-060463号公报
7、专利文献3:日本特表2017-518570号公报
8、专利文献4:日本特开2021-005117号公报
9、然而,在上述的现有技术中,存在文档、句子等数据中设定的矢量的精度较低这样的问题。
10、例如,在现有技术中,在对静态词典中不存在的未知词分配矢量的情况下,能够使用cbow等技术,但在这样的技术中,存在不能对未知词分配适当的矢量的情况。
技术实现思路
1、在一个方面,本发明的目的在于,提供能够使对数据设定的矢量的精度提高的信息处理程序、信息处理方法以及信息处理装置。
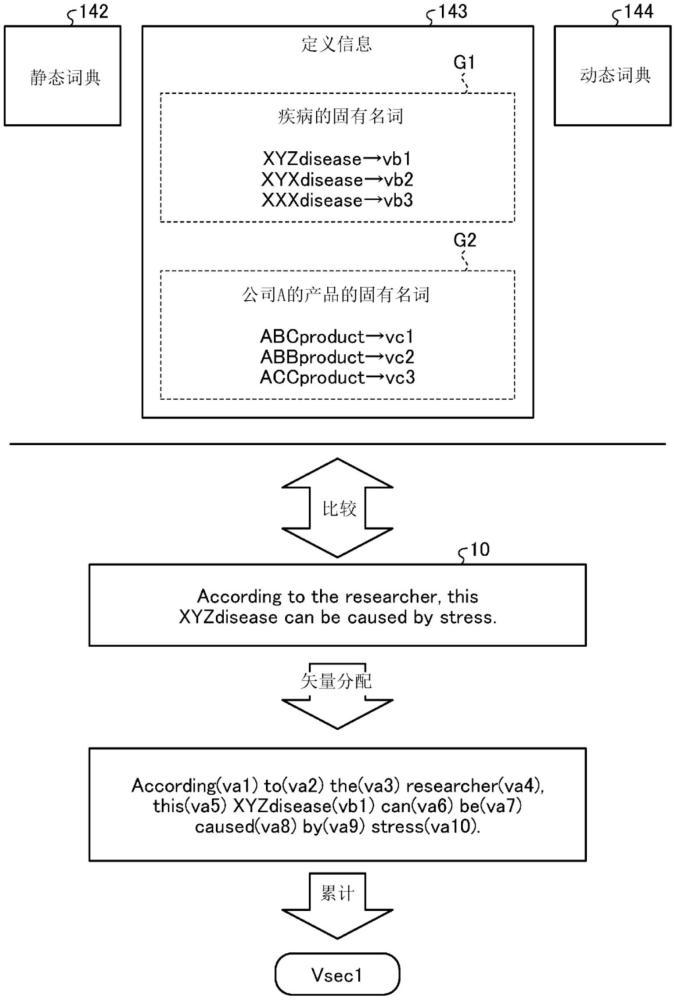
2、在第1方案中,使计算机执行如下的处理。计算机按每一单词分割文本数据。计算机基于定义了静态单词与矢量的关系的静态词典,确定出文本数据所包含的多个单词中的表示不与静态词典的静态单词对应的单词的未知词。计算机根据定义了基于类似的固有单词彼此设定有类似的矢量这样的条件生成的矢量与固有单词的关系的定义信息,来判定与未知词对应的固有单词是否包含于定义信息。计算机在与未知词对应的固有单词包含于定义信息的情况下,将与固有单词的定义信息对应的矢量分配至未知词。计算机在与未知词对应的固有单词不包含于定义信息的情况下,基于配置于未知词的前后的单词,对未知词分配矢量。
3、发明效果
4、能够使对数据设定的矢量的精度提高。
技术特征:
1.一种信息处理程序,其特征在于,使计算机执行如下处理:
2.根据权利要求1所述的信息处理程序,其特征在于,
3.根据权利要求2所述的信息处理程序,其特征在于,
4.根据权利要求3所述的信息处理程序,其特征在于,
5.根据权利要求4所述的信息处理程序,其特征在于,
6.一种信息处理方法,其特征在于,由计算机执行如下处理:
7.根据权利要求6所述的信息处理方法,其特征在于,
8.根据权利要求7所述的信息处理方法,其特征在于,
9.根据权利要求8所述的信息处理方法,其特征在于,
10.根据权利要求9所述的信息处理方法,其特征在于,
11.一种信息处理装置,其特征在于,
12.根据权利要求11所述的信息处理装置,其特征在于,
13.根据权利要求12所述的信息处理装置,其特征在于,
14.根据权利要求13所述的信息处理装置,其特征在于,
15.根据权利要求14所述的信息处理装置,其特征在于,
技术总结
信息处理装置按每一单词分割文本数据。信息处理装置基于定义了静态单词与矢量的关系的静态词典,确定出文本数据所包含的多个单词中表示不与静态词典的静态单词对应的单词的未知词。信息处理装置根据定义了基于类似的固有单词彼此设定有类似的矢量这样的条件生成的矢量与固有单词的关系的定义信息,来判定与未知词对应的固有单词是否包含于定义信息。信息处理装置在与未知词对应的固有单词包含于定义信息的情况下,将与固有单词对应的矢量分配至未知词。信息处理装置在与未知词对应的固有单词不包含于定义信息的情况下,根据配置于未知词的前后的单词对未知词分配矢量。
技术研发人员:片冈正弘,富山庆一,岩田彩
受保护的技术使用者:富士通株式会社
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!