一种场景驱动的分层融合数据血缘分析方法与流程
本发明公开了一种场景驱动的分层融合数据血缘分析方法,属于数据科学领域,用于文档缺乏,设计不规范,导致数据溯源、清洗困难的多系统大数据分析应用场景。
背景技术:
1、数据血缘关系分析是对企业数据流和信息流的全面梳理,是实现数据整合与大数据应用的核心基础。能否准确、清晰、完整地描述数据血缘关系,非常显著地影响大数据应用的成效(金泳,2019)。数据血缘关系分析技术已成为大数据分析方面的研究重点,吸引越来越多研究者的关注。
2、数据血缘分析的过往报道不少,比如毛瑞雪等将现有数据血缘关系分析方法,概括性地分为基于业务信息的工作流溯源方法,以及基于查询反演的数据溯源方法两类(毛瑞雪,2012)。前者从业务层梳理信息系统的业务流,理清数据流和信息流,完成数据血缘关系分析;后者则借助信息系统设计文档等资源,从代码层梳理新系统的数据流和信息流,完成数据血缘关系分析。工作流溯源方法和数据溯源方法,从不同方面梳理数据流和信息流,实现数据血缘关系分析。但因工作流被各系统分割,系统随业务发展被大量整改、弃用或新建,系统人员流失、文档失散(李旭风,2016),以及数据表和字段信息不清晰(潘峰,2016)等原因,导致现有工作溯源和数据溯源的方法,难以满足大数据背景下的数据血缘关系分析需求。
3、本文发明提出一种基于业务场景驱动,以及数据分层融合的数据血缘关系自动分析技术,该技术基于业务场景特征,采用场景驱动策略梳理业务主题数据,同时采用分层融合方法分析系统间,以及数据表间的血缘关系,达到融合不同系统间数据的目的。
技术实现思路
1、本发明要解决的问题是提供一种场景驱动的分层融合数据血缘分析方法。
2、为实现上述目的,本发明采用的技术方案为:
3、一种场景驱动的分层融合数据血缘分析方法,包括如下3个步骤:
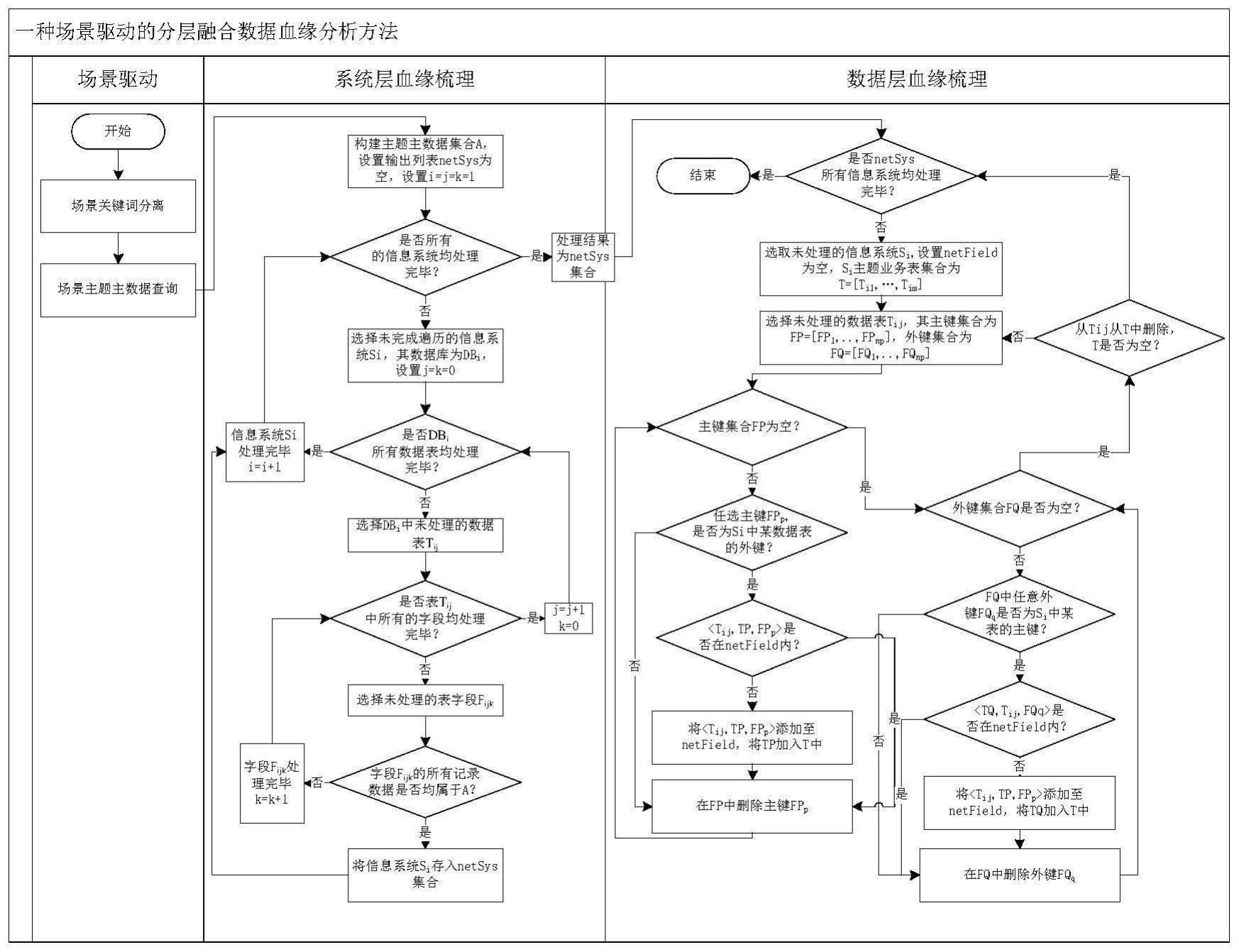
4、步骤1:提取数据分析场景主题关键词,构建sql查询语句,从主数据管理系统查询主题关键词的主数据编码,获得场景的主题关键词主数据信息。从业务层面分析数据分析应用的需求与目标,经过专家讨论确认,提取数据分析应用的主题关键词。构建sql查询语句,从主数据管理系统中查询主题关键词的主数据编码表,获得场景的主题关键词主数据信息集合a。
5、步骤2:系统层血缘关系分析,利用数据分析场景主题关键词的主数据信息,梳理覆盖分析场景主题的信息管理系统,明确基于分析场景主题的系统层血缘关系。系统层血缘关系分析过程中,通过如下的方式明确基于分析场景主题的系统层血缘关系:若某信息系统内至少存在一个数据表,在该数据表中某一列的数据值包含集合a中的元素,且除了集合a中元素外,全为null值,则表示该信息系统中,包含数据分析场景所需要的数据,则认为该系统中包含数据分析场景所需要的数据;否则,认为该数据不包含数据分析场景所需数据。包含数据分析场景所需数据的信息系统集合定义为netsys。在信息系统相关文档缺乏,数据表、数据字段信息不规范、不清晰的情况下,确定包含数据分析场景所需数据信息系统集合的具体流程如下:
6、1)step1:初始化,设置netsys=φ,i=j=k=1。
7、2)step2:判断当前所有信息系统s=[s1,…,sn]处理完毕,若均以处理完毕,则结束分析,netsys集合中的信息系统,即为包含数据分析场景所需数据的信息系统;否则执行step3。
8、3)step3:判断是否所有的信息系统梳理完毕,若有还未梳理完毕的信息系统,则选择未进行梳理的信息系统si,其数据库为dbi,其数据表集合为ti=[ti1,…,tij,…,tim],设置j=k=1;否则结束信息系统的梳理,输出netsys集合为数据分析场景所需数据的信息系统集。
9、4)step4:判断信息系统si是否有未处理的数据表,若有还未处理的数据表,则选择未处理的数据表tij,其字段集合为fij=[fij1,…,fijp];否则,i=i+1,转到步骤step3。
10、5)step5:判断字段fijk中数据值包含集合a中的元素,且除了集合a中元素外,全为null值?若是,则将信息系统si放入集合netsys内,且i=i+1,转到步骤step3;否则,继续判断数据表tij的所有数据列是否全部处理完毕,若还有未处理的数据列,则k=k+1,转到步骤step5;若还有未判断的数据列,则j=j+1,转到步骤step4。
11、步骤3:数据层血缘关系分析,基于信息管理系统内数据表的主键、外键信息,进一步梳理与数据分析场景相关信息系统内的数据表间血缘关系。
12、netsys表示与数据分析场景相关的信息系统集合,信息系统si∈netsys内的数据表间血缘关系网络构建流程如下:
13、1)step1:设置netfield=φ,信息系统si中的主题业务管理表集合为 t=[ti1,…,tim]。
14、2)step2:任选其中数据表tij∈t,设数据表tij的主键集合为其外键集合为
15、3)step3:判断fp=φ?若是,则跳转至step6;否则针对任意的主键 fpp∈fp,判断主键fpp是否为si中任意数据表(假设为tp)的外键,若是则执行step4,否则跳转至step5。
16、4)step4:判断三元组<tij,tp,fpp>∈netfield?若是,则跳转至step5;否则将三元组<tij,tp,fpp>添加至集合netfield,并将数据表tp添加至集合t中。
17、5)step5:从集合fp中删除主键fpp,跳转至step3。
18、6)step6:判断fq=φ?若是则执行step9;否则,针对任意的外键fqq∈fq,判断外键fqq是否为si中任意数据表(假设为tq)的主键,若是则执行step7,否则跳转至step8。
19、7)step7:判断三元组<tq,tij,fqq>∈netfield?,若是,则跳转至step8;否则将三元组<tq,tij,fqq>添加至列表netfield,并将数据表tq添加至集合t中。
20、8)step8:从集合fq中删除外键fqq,跳转至step6。
21、9)step9:将tij从集合t中删除,判断t=φ?若是则执行step10;否则循跳转至step2。
22、10)step10:输出netfield。
23、与现有技术相比,本发明一种场景驱动的分层融合数据血缘分析方法具有以下优异效果:解系统间的业务流和信息流信息,亦无需明确知道数据表字段的定义,无需借助信息管理系统的相关开发文档,仅需分析数据表记录信息,即可明确信息系统是否包含数据分析应用所需数据,适用于业务场景繁杂、数据流紊乱、信息系统文档资源不详尽的大数据应用场景。
技术特征:
1.一种场景驱动的分层融合数据血缘分析方法,其特征在于:由数据分析场景驱动,分层梳理业务场景相关的业务信息系统与数据,解决由于信息系统相关文档缺乏,数据表、数据字段信息不规范、不清晰,所导致的数据溯源、清洗困难问题。
2.根据权利要求1所述的数据分析场景主题关键词提取方法,其特征在于,所述的步骤1具体方法如下:
3.根据权利要求1所述的系统层血缘关系分析方法,其特征在于,所述的步骤2具体方法如下:
4.根据权利要求1所述的数据层血缘关系分析方法,其特征在于,所述的步骤3体方法如下:
技术总结
本文发明一种场景驱动的分层融合数据血缘分析方法,属于数据治理领域,该方法基于业务场景驱动,在明确数据分析场景后,通过对数据库的分析,梳理数据分析场景所覆盖的业务信息系统,明确信息系统数据库层面的数据血缘关系;根据信息系统数据表的主键、外键信息,进一步梳理数据表间的数据血缘关系,表述系统数据库层、数据表层的数据血缘关系。本发明基于场景驱动和分层融合的策略,提出一种全新的数据血缘分析方法,实现多信息系统的数据融合,为数据分析挖掘奠定基础,适用于信息系统相关文档缺乏,数据表、数据字段信息不规范、不清晰,导致数据溯源、清洗困难的多系统大数据应用。说明书附图中的图1为本发明的摘要附图。
技术研发人员:陈爱明,曾仲大,文里梁
受保护的技术使用者:大连达硕信息技术有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!