基于融合运动传感信息的多模态视频描述生成方法
本发明涉及深度学习技术,特别涉及基于动词预测的多模态视频描述生成技术。
背景技术:
1、随着时代的发展和技术的进步,近年来越来越多的可穿戴设备进入人们的生产生活,如google眼镜,微软hololens,华为vr眼镜等,并且在娱乐消遣、行为记录、消防排灾等领域都有着广泛的应用。这些设备的运作大多基于使用者自身的行为动作以及第一视角画面内容,以上数据往往具有高冗余、多信息的特点。尤其是应用于日常行为记录时,海量的视频流会带来巨大的存储负担。与之对应,文字具有很好的抽象描述功能,用于记录日常行为描述时对存储的开销非常微小。本发明致力于利用视频描述生成技术将第一人称视频浓缩为一段关于内容的描述性文字,同时研究运动传感数据与视频信息的多模融合,提升文字生成的精度。
2、视频描述生成任务涉及视频、文本之间跨域的转换。其主流方法从起初的模板匹配策略,基于检索的策略,发展到现在的基于深度学习的策略。受基于编解码结构的算法在机器翻译领域的启发,目前主流的视频描述算法也是基于编解码结构。现阶段的卷积神经网络cnn(编码)与长短期记忆lstm(解码)组成的编解码结构能生成形式灵活的描述语句。然而对于第一人称的日常行为记录,动词作为句式的核心,往往影响生成句子的质量。尤其是对于采取自回归方式的解码器,动词生成的偏差将直接导致后续迭代生成语句的偏差。目前有研究尝试利用视频光流特征或图像特征以挖掘视频运动信息,但这大大增加了存储开销与计算开销。
技术实现思路
1、本发明所要解决的技术问题是,针对仅关注视觉信息的视频描述文字生成方法并不能精准挖掘动作特征,提供一种利用运动传感数据信息辅助视频生成文字描述的方法。
2、本发明为解决上述问题所采用的技术方案是,一种基于融合运动传感信息的多模态视频描述生成方法,包含以下步骤:
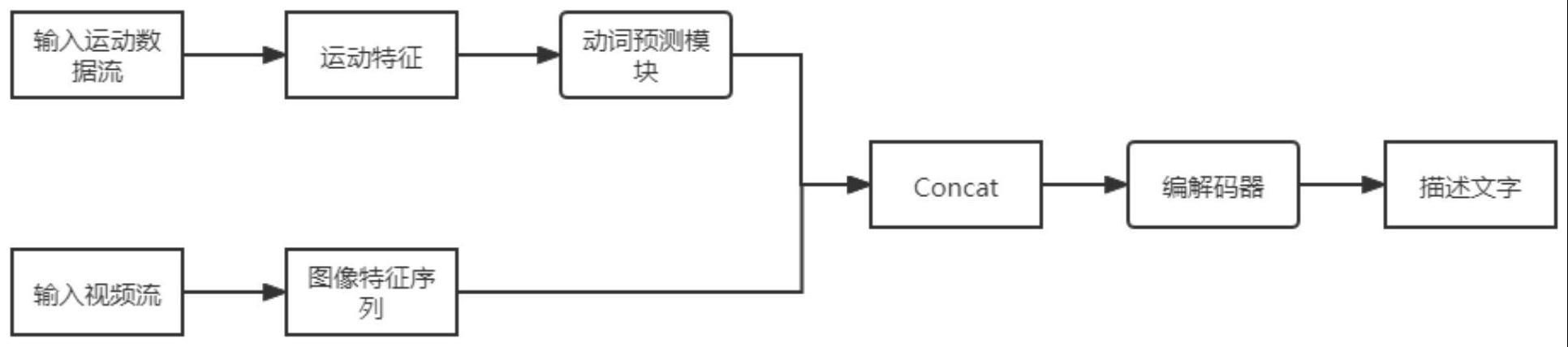
3、1)对输入的视频流和来自运动传感器的运动数据流进行并行特征提取处理;对视频流逐帧提取图像特征;对运动数据流采样并进行提取运动特征,之后再对运动特征进行动词预测得到包含关键动词信息的预测向量;
4、2)对单位采样时间内的得到的所有图像特征以及该单位采样对应的动词预测向量进行拼接得到融合特征;
5、3)将融合特征输入编解码结构中,编解码结构采用自回归的方式逐个生成词汇组成视频描述语句。
6、本发明有别于现有的基于视频流的描述生成方法,本发明设计针对运动传感器数据流的动词预测模块,从而达到多模态信息的融合。
7、动词预测的实施采用一个独立的拟合网络作为动词预测模块。动词预测模块的目的为是让运动特征尽可能预测相应的关键动词,训练完毕后动作特征生成关键动词预测向量,作为额外的运动信息插入到主干网络中。在使用该模块时,其输入为运动特征,其输出为关键动词预测向量。该模块作为单独训练的模块,在添加到主干网络时并不会造成结构上额外的训练负担,且能提供额外的运动信息辅助后续的描述文字生成。
8、传感器数据为单维时序数据,数据量小且可捕捉到直接的运动特征。本方法融合运动数据与视觉两者的模态信息,旨在增加少量的运算与存储成本提升文字描述生成的精度。
9、本发明的有益效果是,通过构建动词预测模块,在不修改主干网络结构的同时使网络更加关注动词的生成;通过引入额外的运动传感器数据,使运动模态和视觉模态相融合,使网络挖掘到更多有效信息,有效提升了视频描述生成的精度。
技术特征:
1.一种基于融合运动传感信息的多模态视频描述生成方法,其特征在于,包含以下步骤:
2.如权利要求1所述方法,其特征在于,采用动词预测模块完成动词预测,动词预测模块由双支路组成,一条运动分支和一条动词分支;动词预测模块独立训练;训练时,动词预测模块使用双支路,完成训练后只使用运动分支;
3.如权利要求2所述方法,其特征在于,关键动词集合p的子集o的生成方式如下:
4.如权利要求3所述方法,其特征在于,关键动词集合p的具体生成方式为:通过统计数据集中出现频次最高的k个动词,将这k个动词组成的集合作为关键动词集合p。
5.如权利要求1所述方法,其特征在于,运动数据流由可穿戴设备的运动传感器输出。
6.如权利要求6所述方法,其特征在于,可穿戴设备的运动传感器具体为6轴运动传感器,运动数据流包括6轴运动传感器采集的三种坐标轴下头部运动的线加速度和角速度。
7.如权利要求1所述方法,其特征在于,编解码结构由双向lstm的编码部分与单向lstm解码部分构成。
技术总结
本发明提供一种基于融合运动传感信息的多模态视频描述生成方法,对输入的视频流和来自运动传感器的运动数据流进行并行特征提取处理;对视频流逐帧提取图像特征;对运动数据流采样并进行提取运动特征,之后再对运动特征进行动词预测得到包含关键动词信息的预测向量;对单位采样时间内的得到的所有图像特征以及该单位采样对应的动词预测向量进行拼接得到融合特征;将融合特征输入编解码结构中逐个生成词汇组成视频描述语句。在不修改主干网络结构的同时使网络更加关注动词的生成;通过引入额外的运动传感器数据,使运动模态和视觉模态相融合,使网络挖掘到更多有效信息,在增加少量的运算与存储成本提升文字描述生成的精度。
技术研发人员:李宏亮,盛一航,任子奕,黄俊强,董健伟
受保护的技术使用者:电子科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!