一种基于大数据的网络消息处理系统的制作方法
1.本发明涉及数据处理技术领域,具体是一种基于大数据的网络消息处理系统。
背景技术:
2.大数据指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据共享合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产;随着社会的发展,人们对数据的查询需求越来越大,数据共享交换是人们迫切需要的。
3.现有的网络消息处理系统在信息交互和处理中存在着所需内容不易找到,且一般网络消息的排序方式都是按照上传时间排序,导致不能及时为没有明确目标的用户提供综合排序较好的内容;同时各网络平台的消息相互交织,用户难以分辨真假,基于以上不足,本发明提出一种基于大数据的网络消息处理系统。
技术实现要素:
4.本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种基于大数据的网络消息处理系统。
5.为实现上述目的,根据本发明的第一方面的实施例提出一种基于大数据的网络消息处理系统,包括消息获取模块、消息处理中心、消息分析模块以及消息推荐模块;
6.所述消息获取模块用于用户发送获取跨平台消息的消息交换请求至消息处理中心;所述消息交换请求携带有用户标识和消息属性标识;
7.所述消息分析模块用于对消息处理中心接收到的消息交换请求进行解析值分析,并将消息交换请求按照解析值pr大小进行降序排列,生成消息交换请求的处理优先表;反馈该消息交换请求的序列位置至消息处理中心;
8.所述消息处理中心接收到消息交换请求后,验证对应身份;验证成功后,则消息处理中心解析消息交换请求内容查找对应消息内容位置,通过共享网络通道采集各网络平台的可信消息返回给消息处理中心;
9.所述消息推荐模块用于获取各网络平台返回的可信消息进行筛选推荐,其中可信消息包括若干个消息切片;具体分析过程如下:
10.对消息切片中的所有对象进行查重分析;对被认为是同一对象的对象进行共享吸引系数比较,将共享吸引系数cf最大的对象作为标准对象;
11.按照可信系数tg大小对标准对象进行排序,选取排名前w1的标准对象反馈至用户终端,其中w1为预设值。
12.进一步地,所述消息分析模块的具体分析步骤为:
13.对消息交换请求进行溯源处理;所述溯源处理表现为:获取发送消息交换请求的用户身份信息和ip网络地址;
14.结合数据库对用户身份信息进行特值赋予过程,得到对应身份信息的特值,并标
记为t1;数据库内存储有身份信息与身份特值的对照表;
15.获取预设时间段内该用户身份信息的请求记录,所述请求记录携带有请求时刻和对应的ip网络地址;根据请求记录对用户的请求吸引因子qs进行评估;
16.获取所有请求记录中对应的ip网络地址,统计得到当前ip网络地址出现的次数占比zb;利用公式pr=(t1
×
a1+qs
×
a2)
×
zb计算得到当前消息交换请求的解析值pr,其中a1、a2均为系数因子。
17.进一步地,请求吸引因子qs的具体评估过程为:
18.统计该用户身份信息的请求次数并标记为请求频次c1;将相邻请求时刻进行时间差计算得到请求间隔qti;将请求间隔qti与间隔阈值相比较;
19.统计qti大于间隔阈值的次数为z1,将对应qti与间隔阈值的差值进行求和得到请求超隔值zt;利用公式zs=z1
×
k1+zt
×
k2计算得到超隔系数zs,其中k1、k2为系数因子;利用公式计算得到对应用户的请求吸引因子qs,其中k3、k4为系数因子。
20.进一步地,其中可信消息的获取方法为:
21.消息处理中心解析消息交换请求内容后,按照消息获取规则向各网络平台获取消息切片;具体为:向每个网络平台获取一个消息切片;
22.其中消息获取规则包括过滤门限和获取数量;即每个消息切片中对象的共享吸引系数cf大于过滤门限且对象数量不大于获取数量。
23.进一步地,消息切片中包含的对象均满足第一预设条件;所述第一预设条件为:与消息交换请求中的用户标识和消息属性标识相对应。
24.进一步地,其中共享吸引系数cf的具体计算方法为:
25.在预设时间段内,采集消息切片中每个对象的查阅记录;所述查阅记录包括查阅时刻以及是否共享;共享包括分享、收藏以及转发行为特征;
26.针对某个对象,统计该对象的共享次数为xb;截取相邻两次共享之间的时间段为共享缓冲时段,将每个共享缓冲时段内该对象的查阅次数标记为共享缓冲频次xpi;将共享缓冲频次xpi与缓冲阈值相比较;
27.统计xpi小于缓冲阈值的次数为p1,将对应xpi与缓冲阈值的差值进行求和得到差缓总值pt;利用公式cz=p1
×
g1+pt
×
g2计算得到差缓系数cz,其中g1、g2为系数因子;利用公式计算得到对应对象的共享吸引系数cf,其中g3、g4为系数因子。
28.进一步地,对消息切片中的所有对象进行查重分析,具体表现为:对消息切片中所有对象的关键词进行提取,当两个对象的关键词重合度大于等于预设重合度λ%,则认为这两个对象为同一对象;其中λ为预设值。
29.进一步地,其中可信系数tg的具体计算过程如下:
30.统计标准对象在每个网络平台的重合数量为li;其中重合数量表示为被认为与标准对象为同一对象的对象数量;
31.统计重合数量li大于0的网络平台数量为ls;将重合数量li与重合阈值相比较;统计li大于重合阈值的次数为lt,将对应li与重合阈值的差值进行求和得到超重总值lz;利
用公式cs=lt
×
g5+lz
×
g6计算得到超重系数cs,其中g5、g6为系数因子;利用公式tg=ls
×
g7+cs
×
g8计算得到对应标准对象的可信系数tg,其中g7、g8为系数因子。
32.与现有技术相比,本发明的有益效果是:
33.1、本发明中所述消息分析模块用于对消息处理中心接收到的消息交换请求进行解析值分析,首先对消息交换请求进行溯源处理;结合数据库对用户身份信息进行特值赋予过程,得到对应身份信息的特值t1;获取预设时间段内该用户身份信息的请求记录,计算得到对应用户的请求吸引因子qs;获取所有请求记录中对应的ip网络地址,统计得到当前ip网络地址出现的次数占比zb;利用公式pr=(t1
×
a1+qs
×
a2)
×
zb计算得到当前消息交换请求的解析值pr,所述消息处理中心按照解析值pr大小依次对消息交换请求进行解析,提高数据处理效率;
34.2、本发明中所述消息处理中心解析消息交换请求内容查找对应消息内容位置,通过共享网络通道采集各网络平台的可信消息返回给消息处理中心;其中可信消息包括若干个消息切片,每个消息切片中包含的对象均与消息交换请求中的用户标识和消息属性标识相对应,且每个对象的共享吸引系数大于过滤门限,使得获取的消息更具有可信度,满足用户需求;同时本发明通过传输包含一定量消息的消息切片的方式,降低在一次网络传输中消息的传输量,并减少网络传输轮次,进而提高了消息读取效率;
35.3、本发明中消息推荐模块用于获取各网络平台返回的可信消息进行筛选推荐;首先对消息切片中的所有对象进行查重分析,将共享吸引系数最大的对象作为标准对象;统计重合数量li大于0的网络平台数量为ls;统计标准对象在每个网络平台的重合数量为li;将重合数量li与重合阈值相比较;计算得到超重系数cs,利用公式tg=ls
×
g7+cs
×
g8计算得到对应标准对象的可信系数tg,按照可信系数tg大小对标准对象进行排序,选取排名前w1的标准对象反馈至用户终端,能够及时为没有明确目标的用户提供综合排序较好的内容,提高查询效率。
附图说明
36.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
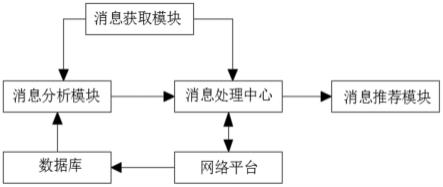
37.图1为本发明一种基于大数据的网络消息处理系统的系统框图。
具体实施方式
38.下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
39.如图1所示,一种基于大数据的网络消息处理系统,包括消息获取模块、消息处理中心、消息分析模块、数据库以及消息推荐模块;
40.消息获取模块用于用户发送获取跨平台消息的消息交换请求至消息处理中心;消
息交换请求携带有用户标识和消息属性标识;
41.消息处理中心接收到消息交换请求后,验证对应身份;验证成功后,则消息处理中心解析消息交换请求内容查找对应消息内容位置,通过共享网络通道采集各网络平台的可信消息返回给消息处理中心;
42.其中,消息处理中心基于分布式平台、身份认证、声誉系统和激励机制,增强消息交换过程中跨平台消息的可靠性;
43.其中,消息处理中心与消息分析模块相连接,消息分析模块用于对消息处理中心接收到的消息交换请求进行解析值分析,具体分析步骤为:
44.对消息交换请求进行溯源处理;溯源处理表现为:获取发送消息交换请求的用户身份信息和ip网络地址;
45.结合数据库对用户身份信息进行特值赋予过程,得到对应身份信息的特值,并标记为t1;其中特值赋予过程的具体步骤为:数据库内存储有身份信息与身份特值的对照表,根据对照表,确定与身份信息对应的身份特值;
46.获取预设时间段内该用户身份信息的请求记录,请求记录携带有请求时刻和对应的ip网络地址;
47.统计该用户身份信息的请求次数并标记为请求频次c1;
48.将相邻请求时刻进行时间差计算得到请求间隔qti;将请求间隔qti与间隔阈值相比较;统计qti大于间隔阈值的次数为z1,将对应qti与间隔阈值的差值进行求和得到请求超隔值zt;利用公式zs=z1
×
k1+zt
×
k2计算得到超隔系数zs,其中k1、k2为系数因子;
49.利用公式计算得到对应用户的请求吸引因子qs,其中k3、k4为系数因子;
50.获取所有请求记录中对应的ip网络地址,统计得到当前ip网络地址出现的次数占比zb;
51.将身份特值t1、请求吸引因子qs以及次数占比zb进行归一化处理并取其数值,利用公式pr=(t1
×
a1+qs
×
a2)
×
zb计算得到当前消息交换请求的解析值pr,其中a1、a2均为系数因子;
52.将消息交换请求按照解析值pr大小进行降序排列生成消息交换请求的处理优先表;反馈该消息交换请求在处理优先表所处的序列位置至消息处理中心;消息处理中心按照消息分析模块反馈的序列位置依次对消息交换请求进行解析,提高数据处理效率;
53.其中可信消息的获取方法为:
54.消息处理中心解析消息交换请求内容后,按照消息获取规则向各网络平台获取消息切片;具体为:向每个网络平台获取一个消息切片;其中消息切片中包含的对象均满足第一预设条件;第一预设条件为:与消息交换请求中的用户标识和消息属性标识相对应;
55.本发明通过传输包含一定量消息的消息切片的方式,降低在一次网络传输中消息的传输量,并减少网络传输轮次,进而提高了消息读取效率;
56.其中消息获取规则包括过滤门限和获取数量;即每个消息切片所包含对象的共享吸引系数大于过滤门限且所包含对象的数量不大于获取数量;使得获取的消息更具有可信度,满足用户需求;
57.其中共享吸引系数的具体计算方法为:
58.在预设时间段内,采集消息切片中每个对象的查阅记录;查阅记录包括查阅时刻以及是否共享;共享包括分享、收藏、转发等行为特征;
59.针对某个对象,统计该对象的共享次数为xb;截取相邻两次共享之间的时间段为共享缓冲时段,将每个共享缓冲时段内该对象的查阅次数标记为共享缓冲频次xpi;将共享缓冲频次xpi与缓冲阈值相比较;
60.统计xpi小于缓冲阈值的次数为p1,将对应xpi与缓冲阈值的差值进行求和得到差缓总值pt;利用公式cz=p1
×
g1+pt
×
g2计算得到差缓系数cz,其中g1、g2为系数因子;
61.利用公式计算得到对应对象的共享吸引系数cf,其中g3、g4为系数因子;
62.消息推荐模块与消息处理中心相连接,用于获取各网络平台返回的可信消息进行筛选推荐,可信消息包括若干个消息切片,具体分析过程如下:
63.对消息切片中的所有对象进行查重分析,具体表现为:对消息切片中所有对象的关键词进行提取,当两个对象的关键词重合度大于等于预设重合度λ%,则认为这两个对象为同一对象;其中λ为预设值;
64.对被认为是同一对象的对象进行共享吸引系数比较,将共享吸引系数最大的对象作为标准对象;
65.统计标准对象在每个网络平台的重合数量为li;其中重合数量表示为被认为与标准对象为同一对象的对象数量;
66.统计重合数量li大于0的网络平台数量为ls;将重合数量li与重合阈值相比较;统计li大于重合阈值的次数为lt,将对应li与重合阈值的差值进行求和得到超重总值lz;利用公式cs=lt
×
g5+lz
×
g6计算得到超重系数cs,其中g5、g6为系数因子;
67.利用公式tg=ls
×
g7+cs
×
g8计算得到对应标准对象的可信系数tg,其中g7、g8为系数因子,可信系数tg越大,则表明对应标准对象在各网络平台分布越广,传播越深,可信度越高;
68.按照可信系数tg大小对标准对象进行排序,选取排名前w1的标准对象反馈至用户终端,既满足用户的个性化需求,又能够及时为没有明确目标的用户提供综合排序较好的内容,提高查询效率。
69.上述公式均是去除量纲取其数值计算,公式是由采集大量数据进行软件模拟得到最接近真实情况的一个公式,公式中的预设参数和预设阈值由本领域的技术人员根据实际情况设定或者大量数据模拟获得。
70.本发明的工作原理:
71.一种基于大数据的网络消息处理系统,在工作时,消息获取模块用于用户发送获取跨平台消息的消息交换请求至消息处理中心;消息分析模块用于对消息处理中心接收到的消息交换请求进行解析值分析,首先对消息交换请求进行溯源处理;结合数据库对用户身份信息进行特值赋予过程,得到对应身份信息的特值t1;获取预设时间段内该用户身份信息的请求记录,计算得到对应用户的请求吸引因子qs;获取所有请求记录中对应的ip网络地址,统计得到当前ip网络地址出现的次数占比zb;利用公式pr=(t1
×
a1+qs
×
a2)
×
zb
计算得到当前消息交换请求的解析值pr,消息处理中心按照解析值pr大小依次对消息交换请求进行解析,提高数据处理效率;
72.消息处理中心接收到消息交换请求后,验证对应身份;验证成功后,则消息处理中心解析消息交换请求内容查找对应消息内容位置,通过共享网络通道采集各网络平台的可信消息返回给消息处理中心;其中可信消息包括若干个消息切片,每个消息切片中包含的对象均与消息交换请求中的用户标识和消息属性标识相对应,且每个对象的共享吸引系数大于过滤门限;使得获取的消息更具有可信度,满足用户需求;同时本发明通过传输包含一定量消息的消息切片的方式,降低在一次网络传输中消息的传输量,并减少网络传输轮次,进而提高了消息读取效率;
73.消息推荐模块用于获取各网络平台返回的可信消息进行筛选推荐;首先对消息切片中的所有对象进行查重分析,将共享吸引系数最大的对象作为标准对象;统计重合数量li大于0的网络平台数量为ls;统计标准对象在每个网络平台的重合数量为li;将重合数量li与重合阈值相比较;计算得到超重系数cs,利用公式tg=ls
×
g7+cs
×
g8计算得到对应标准对象的可信系数tg,按照可信系数tg大小对标准对象进行排序,选取排名前w1的标准对象反馈至用户终端,既满足用户的个性化需求,又能够及时为没有明确目标的用户提供综合排序较好的内容,提高查询效率。
74.在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
75.以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1