基于运动特征和外观特征的视频目标检测及域适应方法
1.本发明属于计算机视觉、模式识别技术领域,特别地涉及到一种基于运动特征和外观特征的视频目标检测及域适应方法。
背景技术:
2.在多媒体技术应用愈发普遍的今天,得益于计算机视觉技术以及深度学习技术的飞速发展,基于视频信号智能化地完成一些任务成为可能。对视频进行智能的分析处理不但可以大大减轻人力负担节省成本,还可能在一些任务上获得比人工处理更加稳定可靠的效果。
3.目前一些针对视频输入信号完成感兴趣目标检测定位的方法首先基于背景差分方法预先提取可能存在目标前景的区域,并通过后续分类实现单张视频帧中感兴趣目标的检测。这种前景区域提取方法对于复杂多变的视频场景鲁棒性较差,容易出现低质量的区域提取或漏检。此外,绝大多数现有方法集中视频中外观特征的提取,这些方法没有充分提取视频中包含的运动变化信息,该问题会导致检测框架不适用于异常行为检测、汽车尾气检测这类仅凭外观特征难以有效完成的任务。另一方面,一些情况下感兴趣目标在视频中出现概率很可能比较低,然而现有的绝大多数框架仅利用非常有限的含有感兴趣目标的视频(正样本数据)训练模型,并且这种做法很可能导致实际应用中模型非常容易错误地检测出非感兴趣目标。
4.此外,实际检测模型应用部署中容易遇到部分视频场景在一段时间内无法提供拍摄到感兴趣目标的视频作为正样本数据参与检测模型训练这一情况。由于不同视频通常会在场景、视频质量等方面存在较大的差异性,该情况下训练所得模型会在正样本训练数据缺失场景下表现出严重的性能劣化。这一问题与计算机视觉中的域适应问题较为类似,目前视频目标检测方面对这一问题的关注较少。
技术实现要素:
5.针对视频目标检测算法的问题,本发明提供了一种基于运动特征和外观特征的视频目标检测方法,其能够充分提取视频蕴含的外观与运动信息并完成对于任意一张视频帧中感兴趣目标的检测定位。
6.为实现上述目的,本发明中的基于运动特征和外观特征的视频目标测方法采用如下技术方案:
7.本发明实施例的第一方面提供了一种基于运动特征和外观特征的视频目标检测方法,具体包括如下步骤:
8.(1)将输入的任意视频转化为视频帧构成的图片集合,对其中任意一张目标视频帧i进行感兴趣目标的检测,抽取目标视频帧i与其相邻的2p张视频帧,合计2p+1张视频帧,并进行视频帧i的目标检测;
9.(2)使用骨干网络提取各帧的外观特征,获得2p+1个外观特征;
10.(3)将每一张相邻帧in的外观特征an与目标视频帧i的外观特征a输入运动特征提取网络em以提取对应的运动特征mn,同时运动特征提取网络em输出相应的预测运动的像素级运动信息图fn;
11.(4)所述像素级运动信息图fn用于将每一张相邻帧in的外观特征an向目标视频帧i的外观特征a对齐以获得空间对齐的外观特征a’n
;
12.(5)使用外观特征聚合网络e
aa
对外观特征进行融合获得外观特征fa,将外观特征fa输入外观特征精炼网络ra进行哈达玛积,获得精炼后的外观特征f’a
;
13.(6)使用运动特征聚合网络e
am
对运动特征mn进行融合获取运动特征fm,将运动特征mn输入运动特征精炼网络rm进行哈达玛积,获得精炼后的运动特征f’m
14.(7)将步骤(5)获得的精炼后的外观特征f’a
与步骤(6)获得的精炼后的运动特征f’m
输入特征聚合网络e
agg
,获取一个与输入的两个特征尺寸一致的聚合特征f
agg
;
15.(8)将聚合特征f
agg
输入目标检测网络h获得目标的边框预测结果b及其相应的分类置信度c;
16.(9)对视频目标检测网络进行训练;对训练好的视频目标检测网络进行测试,若分类置信度c的最大值c
max
若大于预设阈值则判定目标视频帧i中存在感兴趣目标并输出目标的边框预测结果b,否则判定该帧中无感兴趣目标存在。
17.进一步的,所述骨干网络为resnet-50、resnet-101或vgg-16网络。
18.进一步的,所述的步骤(3)中的运动特征提取网络em可以是当前任何能够实现如下映射的神经网络:
19.mn,fn=em(a,an)
20.其中运动信息图fn可被用于如下的某相邻帧外观特征an向需要进行目标检测的目标帧外观特征a的空间对齐:
21.a
′n=align(an,fn)
22.其中空间对齐操作align(
·
)可以是当前任何能够完成特征像素空间位置调整操作的映射。
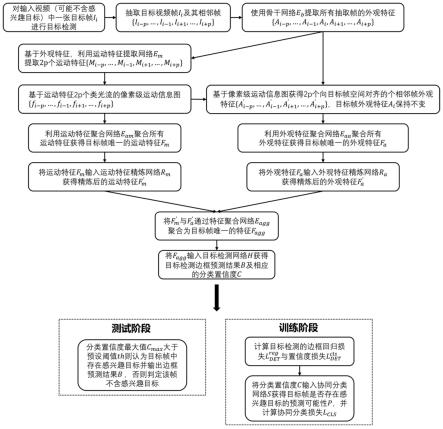
23.进一步的,对视频目标检测网络进行训练的过程具体为:
24.计算置信度损失与边框回归损失
25.将置信度预测结果c输入协同分类网络s,获得目标帧i是否含有感兴趣目标的预测可能性p:
26.根据目标帧i是否真实存在感兴趣目标的标签y
*
并结合协同分类网络输出的预测可能性p计算协同分类损失l
cls
;
27.利用上述计算得到的置信度损失边框回归损失以及协同分类损失l
cls
优化视频目标检测网络。
28.进一步的,所述协同分类损失l
cls
为一种二分类损失。
29.本发明实施例的第二方面提供了一种基于运动特征和外观特征的视频目标检测的域适应方法,具体包括如下步骤:
30.(1)将运动特征精炼网络rm输出的运动空间注意力attm与聚合特征f
agg
进行哈达玛积获得优化后的聚合特征f’agg
;
31.(2)将视频目标检测网络中的聚合特征f
agg
替换为优化后的聚合特征f’agg
;对调整优化后的视频目标检测网络进行训练;再对训练好的视频目标检测网络进行测试。
32.优选的,对调整优化后的视频目标检测网络进行训练的过程具体为:
33.对聚合特征f’agg
进行对抗方式的域适应,计算获得对抗学习损失l
adv
;
34.利用置信度损失边框回归损失协同分类损失l
cls
以及对抗学习损失l
adv
训练调整优化后的视频目标检测网络,获得初步训练的视频目标检测网络;
35.将用于预测分类置信度c的特征在空间维度上完全拆解为实例级别特征,并根据是否对应感兴趣目标区域、分类置信度细分为包括分类置信度较高且对应感兴趣目标tp,分类置信度较高但对应背景fp,分类置信度较低且对应背景tn,分类置信度较低但对应感兴趣目标fn在内的类别;
36.以属于分类置信度较高且对应感兴趣目标tp和分类置信度较低且对应背景tn的实例特征分别构建有代表性的正原型特征p
p
和负原型特征pn;
37.计算损失函数l
p
,该函数是目前任意可拉近p
p
与fn中实例特征距离并推远p
p
与fp中实例特征距离的函数;
38.计算损失函数ln,该函数是目前任意可拉近pn与fp中实例特征距离并推远pn与fn中实例特征距离的函数;
39.在初步训练的视频目标检测网络的基础上,通过置信度损失边框回归损失协同分类损失l
cls
、对抗学习损失l
adv
、损失函数l
p
和损失函数ln,对该模型进行进一步调优训练以获得最终的视频目标检测网络。
40.优选的,所述对抗方式的域适应为一种基于梯度反转层grl以及域分类任务的域适应方法。
41.本发明实施例的第三方面提供了一种电子设备,包括存储器和处理器,其中,所述存储器与所述处理器耦接;其中,所述存储器用于存储程序数据,所述处理器用于执行所述程序数据以实现上述的基于运动特征和外观特征的视频目标检测方法和基于运动特征和外观特征的视频目标检测的域适应方法。
42.本发明实施例的第四方面提供了一种计算机可读存储介质,其上存储有计算机程序,其中,所述程序被处理器执行时实现上述的基于运动特征和外观特征的视频目标检测方法和基于运动特征和外观特征的视频目标检测的域适应方法。
43.本发明公开的适配于前述视频目标检测的域适应方法的有益效果是:利用运动空间注意力使模型提取的特征更加关注与场景关联性较弱的前景区域,且利用对抗方式的隐式特征对齐与新颖的基于正负原型特征的显式实例特征对齐进一步缩小了模型提取特征的跨场景差异,能够提升视频目标检测网络的泛化表现。
附图说明
44.图1为本发明中基于运动特征和外观特征的视频目标检测方法流程图;
45.图2为本发明中基于运动特征和外观特征的视频目标检测方法的模型结构示意图;
46.图3为本发明中适配于基于运动特征和外观特征的视频目标检测方法的域适应方
法流程图;
47.图4为本发明装置的示意图。
具体实施方式
48.为了使本发明的技术方案表述更加清楚,以下结合附图及实施例对本发明中的基于运动特征和外观特征的视频目标检测及域适应方法进行详细说明。
49.参考图1,所示为本发明公开的基于运动特征和外观特征的视频目标检测方法流程图。参考图2,所示为本发明公开的基于运动特征和外观特征的视频目标检测方法的模型结构示意图。
50.输入一段视频(可能不包含感兴趣目标)转化所得的n张视频帧构成的图片集合{i1,i2,...,in},利用本发明公开的基于运动特征和外观特征的视频目标检测方法针对其中一张目标视频帧ii进行感兴趣目标的检测需要进行以下步骤处理:
51.步骤1.1:抽取目标视频帧ii及与其相邻的2p张视频帧,本发明实施例中所述相邻的2p张视频帧为前p张相邻帧与后p张相邻帧,其中p为自定义的正整数,合计为2p+1张视频帧{i
i-p
,...,i
i-1
,ii,i
i+1
,...,i
i+p
};,并进行视频帧i的目标检测;
52.步骤1.2:将步骤1.1中所得的视频帧逐一输入骨干网络eb提取各帧的外观特征,获得2p+1个外观特征{a
i-p
,...,a
i-1
,ai,a
i+1
,...,a
i+p
},本发明实施例中骨干网络eb可以采用深度学习中常用的resnet-50 resnet-101或vgg-16等网络;
53.步骤1.3:将每个相邻帧外观特征aj与目标帧外观特征ai在通道维度连接并输入由卷积层与激活层构成的运动特征提取网络em,获得2p个运动特征{m
i-p
,...,m
i-1
,m
i+1
,...,m
i+p
}以及相应的2p个类光流的像素级运动信息图{f
i-p
,...,f
i-1
,f
i+1
,...,f
i+p
},其中运动信息图由对应的运动特征通过单层卷积预测获得;。对于一张目标视频帧i的目标检测,会获取到2p个对齐后的相邻帧外观特征、2p个运动特征。
54.优选的,所述的步骤1.3中的运动特征提取网络em可以是当前任何能够实现如下映射的神经网络:
55.mn,fn=em(a,an)
56.其中运动信息图fn可被用于如下的某相邻帧外观特征an向需要进行目标检测的目标帧外观特征a的空间对齐:
57.an=align(an,fn)
58.其中空间对齐操作align(
·
)可以是当前任何能够完成特征像素空间位置调整操作的映射。
59.步骤1.4:利用每张类光流的运动信息图fj将对应的相邻帧外观特征aj向目标帧外观特征ai进行投影,获得在空间上向目标帧进行了一定程度对齐的2p个相邻帧外观特征{a’i-p
,...,a
′
i-1
,a’i+1
,...,a
′
i+p
};
60.步骤1.5:将步骤1.4获得的空间对齐的2p个相邻帧外观特征以及一张目标帧外观特征全部在通道维度连接并输入由卷积层以及激活层构成的外观特征聚合网络e
aa
获得目标帧唯一的外观特征fa,将2p个运动特征全部在通道维度连接并输入由卷积层以及激活层构成的运动特征聚合网络e
am
获得目标帧唯一的运动特征fm;其中e
am
可以是目前任何能够输入2p个同等尺寸特征并输出一个相同尺寸特征的神经网络。其中e
aa
可以是目前任何能够输
入2p+1个同等尺寸特征并输出一个相同尺寸特征的神经网络。
61.步骤1.6:将目标帧唯一的外观特征fa与运动特征fm分别输入外观特征精炼网络ra与运动特征精炼网络rm,分别获得精炼的外观特征f’a
与精炼的运动特征f’m
。两种特征精炼的方式是一致的,具体的特征精炼方式为首先分别生成外观空间注意力atta与运动空间注意力attm,随后通过空间注意力与对应特征进行哈达玛积(hadamard积)获得精炼后的外观特征f’a
与运动特征f’m
。
62.优选的,运动空间注意力attm可以由目前任意一种空间注意力模块输入运动特征fm后预测获得。外观空间注意力atta可以由目前任意一种空间注意力模块输入fa后预测获得。
63.步骤1.7:将精炼的外观特征f’a
与精炼的运动特征f’m
在通道维度连接并输入由卷积层与激活层构成的特征聚合网络e
agg
,获得目标帧唯一的且与输入的两个特征尺寸一致的聚合特征f
agg
;特征聚合网络e
agg
可以是任何能够实现这种映射的神经网络。
64.步骤1.8:将聚合特征f
agg
输入目标检测网络h获得目标检测边框预测结果b及其相应的分类置信度c。目标检测网络h可以是目前任意一种目标检测网络,例如fcos、retinanet等网络。图1中,本发明实施例选用的目标检测网络h为基于锚框的一阶段目标检测网络,其包围框回归部分与分类置信度预测部分皆为卷积层与激活层构成的网络。
65.步骤1.9对视频目标检测网络进行训练;对训练好的视频目标检测网络进行测试,若分类置信度c的最大值c
max
若大于预设阈值则判定目标视频帧i中存在感兴趣目标并输出目标的边框预测结果b,否则判定该帧中无感兴趣目标存在。本发明实施例中,预设阈值th=0.75。
66.对视频目标检测网络进行训练的过程具体为:
67.步骤(a):将目标帧表示为i,利用其感兴趣目标包围框标注信息并结合检测网络输出,可参考现有目标检测方法计算如下的置信度损失(以单一类别感兴趣目标为实施例进行举例)与边框回归损失其中a
pos
与a
neg
分别代表目标帧i中有匹配感兴趣目标的正样本锚框索引集合和没有匹配目标的负样本锚框索引集合,w
pos
=0.999与w
neg
=0.001分别代表预设的正负样本损失权重,pi与pj分别表示模型输出的相应正负锚框的分类置信度,γ=3.0为控制训练更加关注分类效果较差样本的参数(γ越大则训练越关注分类较差的样本)。y
*
为目标帧i是否含有感兴趣目标的标签,y
*
为1代表该目标帧含有含有感兴趣目标,且指示函数i(y
*
==1)输出值将为1,否则指示函数输出值为0。g∈{w,h,x,y}表示包围框参数的四种类型,w、h、x、y分别对应宽、高、中心点横坐标与中心点纵坐标。b
i,g
和分别表示索引为i对应的正样本锚框的g类型参数预测值和真实标签值。
[0068][0069][0070]
[0071]
步骤(b):将置信度预测结果c输入协同分类网络s,获得单张目标帧是否含有感兴趣目标的预测可能性p。协同分类网络s可由卷积层、激活层与全连接层构成,对一张视频帧输出的结果p为一个标量。
[0072]
步骤(c):根据目标帧i是否真实存在感兴趣目标的标签y
*
并结合协同分类网络输出p,计算如下的协同分类损失l
cls
;
[0073]
l
cls
(i)=-y
*
log(y)-(1-y
*
)log(1-y)
[0074]
优选的,所述协同分类损失l
cls
可以是目前任何一种二分类损失。
[0075]
步骤(d):利用上述计算得到的置信度损失边框回归损失以及协同分类损失l
cls
优化视频目标检测网络。
[0076]
参考图3,所示为本发明中适配于前述视频目标检测方法的域适应方法示意图。
[0077]
本发明所公开的适配于前述视频目标检测的域适应方法可更加详细地描述为以下步骤:
[0078]
步骤2.1:使用运动特征精炼网络rm中间步骤产生的运动空间注意力attm与目标帧唯一的聚合特征f
agg
进行hadamard积,促使优化后的聚合特征f’agg
更加关注与场景关联性较弱的运动前景区域。
[0079]
步骤2.2:将视频目标检测网络中的聚合特征f
agg
替换为优化后的聚合特征f’ag
g;对调整优化后的视频目标检测网络进行训练;再对训练好的视频目标检测网络进行测试。
[0080]
对调整优化后的视频目标检测网络进行训练的过程具体为:。
[0081]
对步骤2.1中所得目标帧i的更优聚合特征f’agg
进行基于梯度反转层grl的对抗方式跨场景特征对齐。聚合特征f’agg
将被grl反转梯度后输入全连接层构成的判别器d预测所有特征像素所属场景的类别,并依据真实场景类别计算如下的对抗学习损失l
adv
。其中片,w分别为f’agg
的高与宽,q代表训练数据无缺失的源域场景数量(源域场景类别编码为1至g,数据有所缺失的场景类别编码为0),表示目标帧所属的场景的分类标签(若目标帧属于编码j的场景,则t
(j)
=1且t中其他值均为0);
[0082][0083]
利用对抗学习损失l
adv
以及置信度损失边框回归损失协同分类损失l
cls
训练步骤2.1调整后的视频目标检测网络;
[0084]
此步骤目标在于使用训练数据进一步调优训练上述初步训练所得的视频目标检测框架。第t轮调优训练具体由以下步骤构成:
[0085]
首先将框架的目标检测网络h中用于预测分类置信度c的目标帧对应特征fc在空间维度完全拆解为h
×
w个局部区域实例级别向量特征{vk|k∈{1,2,...,h
×
w}};
[0086]
根据各个实例特征对应的检测置信度ck以及是否对应感兴趣目标区域的真实标签y
′k(1对应含有感兴趣目标,0对应背景)确定每个实例特征是否正确分类为前景或背景。ck>0.5则该实例被预测为含有感兴趣目标,否则该实例被预测为背景类别;
[0087]
分别使用分类正确的感兴趣目标对应的实例特征与背景区域对应的实例特征构建第t轮的正、负原型特征。构建方法可以是目前任意可行的原型构建方法。可以采用滑动
平均的方式获得第t轮的正、负原型特征。具体而言,通过分类正确的正负实例特征做平均的方式获得第t轮的临时正负原型与随后第t轮正负原型由前一轮原型与当前轮临时原型通过如下方式计算获得,其中α为同类别前一轮原型与当前轮临时原型之间的调整后的余弦相似度;
[0088][0089][0090]
通过计算如下的正样本原型损失l
p
来显式地缩小错误分类的感兴趣目标区域对应的实例特征与正原型特征之间的距离,并显式地扩大错误分类的感兴趣目标区域对应的实例特征与负原型特征之间的距离。其中fp与fn分别表示错误分类的实例特征索引集合,|fp|和|fn|分别表示两种实例特征的数量,k为实例特征的索引,λn=0.1为错误分类的背景区域对应实例特征计算所得损失函数的权重;
[0091][0092]
通过计算如下的负样本原型损失ln来显式地缩小错误分类的背景区域对应的实例特征与负原型特征之间的距离,并显式地扩大错误分类的背景区域对应的实例特征与正原型特征之间的距离;
[0093][0094]
计算前述的对抗学习损失l
adv
以及置信度损失边框回归损失协同分类损失l
cls
,配合原型损失l
p
与ln实现对于初步训练所得的所得的视频目标检测网络的进一步调优训练,获得在正样本训练数据缺失的场景下表现得到改善的视频目标检测框架。
[0095]
本发明公开的运动特征和外观特征的视频目标检测方法应用于自建的多场景汽车尾气检测任务可获得如表1所示的实验测试数据。
[0096]
表1
[0097][0098]
将以上实验中的场景5设定目标域(训练中缺失有汽车尾气这一感兴趣目标的正样本训练数据),其他4个场景设定为源域(训练数据完整)。则如下表2所示,本发明公开的运动特征和外观特征的视频目标检测方法在目标域场景5下的目标检测指标将严重衰减,而本发明公开的域适应方法可显著提升基于运动特征和外观特征的视频目标检测方法在目标域场景5下的表现。
[0099]
表2
[0100][0101]
与前述基于运动特征和外观特征的视频目标检测及域适应方法的实施例相对应,本发明还提供了基于运动特征和外观特征的视频目标检测及域适应装置的实施例。
[0102]
参见图4,本发明实施例提供的一种基于运动特征和外观特征的视频目标检测及域适应装置,包括一个或多个处理器,用于实现上述实施例中的基于运动特征和外观特征的视频目标检测及域适应方法。
[0103]
本发明基于运动特征和外观特征的视频目标检测及域适应装置的实施例可以应用在任意具备数据处理能力的设备上,该任意具备数据处理能力的设备可以为诸如计算机等设备或装置。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在任意具备数据处理能力的设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的。从硬件层面而言,如图4所示,为本发明基于运动特征和外观特征的视频目标检测及域适应装置所在任意具备数据处理能力的设备的一种硬件结构图,除了图4所示的处理器、内存、网络接口、以及非易失性存储器之外,实施例中装置所在的任意具备数据处理能力的设备通常根据该任意具备数据处理能力的设备的实际功能,还可以包括其他硬件,对此不再赘述。
[0104]
上述装置中各个单元的功能和作用的实现过程具体详见上述方法中对应步骤的实现过程,在此不再赘述。
[0105]
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本发明方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
[0106]
本发明实施例还提供一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现上述实施例中的基于运动特征和外观特征的视频目标检测及域适应方法。
[0107]
所述计算机可读存储介质可以是前述任一实施例所述的任意具备数据处理能力的设备的内部存储单元,例如硬盘或内存。所述计算机可读存储介质也可以是任意具备数据处理能力的设备,例如所述设备上配备的插接式硬盘、智能存储卡(smart media card,smc)、sd卡、闪存卡(flash card)等。进一步的,所述计算机可读存储介质还可以既包括任意具备数据处理能力的设备的内部存储单元也包括外部存储设备。所述计算机可读存储介质用于存储所述计算机程序以及所述任意具备数据处理能力的设备所需的其他程序和数据,还可以用于暂时地存储已经输出或者将要输出的数据。
[0108]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1