一种基于多模态数据融合的行为识别方法
1.本专利申请涉及一种基于多模态数据融合的行为识别方法,属于计算机视觉领域。
背景技术:
2.近年来人工智能快速发展,机器视觉,模式识别,自然语言处理等技术已经在社会发展的多个方面得到了广泛应用。其中涉及的领域有智能制造,自动驾驶,智能机器人等。机器视觉在人工智能中有着举足轻重的作用。机器视觉致力于使用计算机来达到生物视觉的作用,极大地促进者人工智能的发展。机器视觉是一项综合技术,包括计算机软件技术、传感器、光学成像、图像处理、视频处理、电光源照明等。计算机通过机器视觉实现了对周围环境的感知与理解。人体行为识别与研究是对机器视觉技术一项重要应用,通过分析各类传感器收集到的人体行为时各类信息,达到人体行为识别的目的。人体行为识别与研究在生活中有着广泛的应用,其中包括的主要应用领域有:
3.医疗辅助:人体行为识别在医疗辅助领域有着广泛的应用。人体的诸多疾病,例如帕金森症、老年痴呆等,在疾病确认、康复等阶段都需要对病人的肢体行为进行观察、识别与研究。传统人工行为观察方式,往往会受专业医护人员数量不足,观察时间受限等问题影响。采用机器视觉技术对患者行为识别与研究,不仅提高了识别精度,还大大节省了医疗资源。
4.视频监控:如今公共安全问题越来越多受到了社会的关注。公共场合中威胁公众安全的行为时有发生。在火车站、幼儿园等场合进行视频监控来识别入镜人员的行为能有效地实现犯罪及危险监控,实现监控智能化。除了公共场合,行为识别在室内监控中也有着广泛的应用。对于有老年人的家庭,通过安装家庭摄像头,可以实时监控老年人行为,自动判断老年人是否发生跌倒、发病等危险行为。在危险出现的第一时间通知子女并启动警报系统。
5.体感游戏:体感游戏是通过人体肢体动作来控制游戏进行,丰富和拓展了人机交互的方式,大大增强了游戏的真实性与娱乐性。体感游戏一般通过深度或彩色摄像机来采集游戏者的行为数据,通过分析行为数据来识别游戏者指令。2010年6月微软公司推出了体感游戏设备kinect,并发布了多种基于kinect的体感游戏。自从体感游戏的出现,游戏方式从双手操作变成了肢体行为操作。kinect在人体深度数据的基础上进一步提取了人体骨骼数据,极大的简化了构建人体模型的复杂度。
6.运动分析:运动分析是利用摄像机采集人体运动信息,通过研究人体各个部位的位置、速度以及加速度来分析指导人体运动。运动分析常用于运动员的竞技动作分析,通过研究改善运动员的动作实现运动成绩的提高。
7.随着计算机视觉的不断发展,行为识别算法运用广泛。但由于单模态人体行为识别研究遇到瓶颈、噪声样本对实验造成副作用等问题,同时对行为识别的准确性要求较高。针对以上的问题,本发明设计了一种基于多模态数据融合的行为识别方法。
技术实现要素:
8.本发明所要解决的技术问题是:提供一种基于多模态数据融合的行为识别方法,为多模态行为识别研究与克服噪声样本对实验产生的影响提供了一种高效可靠的解决方案。
9.本发明为解决上述技术问题采用以下技术方案:
10.一种基于多模态数据融合的行为识别方法,包括如下步骤:
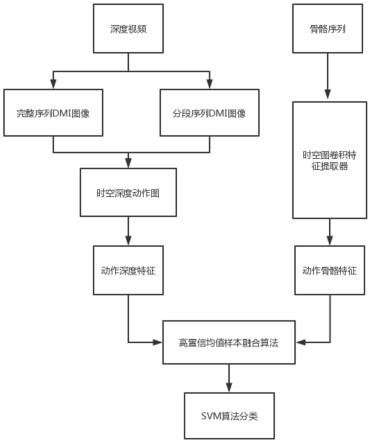
11.步骤1,深度数据动作特征提取。针对深度视频类型数据,在视频序列上提取到dmi深度特征图;然后,将原有的深度动作序列按照帧数分为相同长度的2段子序列,在各子序列上分别提取子dmi深度特征图。将得到的两张子dmi特征图与dmi图像一起组成时空深度动作图,并使用hog算法提取动作的深度特征。
12.步骤2,骨骼数据动作特征提取。针对骨骼序列数据,使用基于时空图卷积网络模型改进的时空图卷积特征提取器,直接处理骨骼序列,提取动作的骨骼特征。
13.步骤3,不同模态数据动作特征融合。在得到两种数据模态上的动作特征后,使用一种基于cca改良的高可信均值样本融合算法,融合两类特征,获得融合特征。
14.步骤4,融合特征分类。使用svm对融合特征进行分类,并计算识别的准确率。
15.作为本发明的一种优选方案,所述步骤1的提取时空深度动作图特征的具体过程为:
16.1.1在输入的深度视频上计算获得三视角的dmi深度特征图。公式如下所示:
17.dmiv=max(i(h,w)v)
18.其中,dmiv表示在v视角上的dmi特征图,视角分为f,s,d三种,分别对应前视角、侧视角与俯视角。(h,w)表示图像i上的坐标位置。max()表示求最大值。
19.1.2将原有的深度视频分为相同帧数的两段子视频序列,分别在子视频序列上计算三视角子dmi深度特征图。公式如下所示:
[0020][0021]
其中,dmiv表示在v视角上的dmi特征图,视角分为f,s,d三种,分别对应前视角、侧视角与俯视角。i表示子序段数的序号。(h,w)表示图像i上的坐标位置。t代表当前的段数。n代表原深度视频的总帧数。max()表示求最大值。
[0022]
1.3将dmi深度特征图与子dmi深度特征图合为一个整体,称为时空深度动作图。一个动作样本使用一份时空深度动作图表示,一份时空深度动作图包含有9张灰度图。使用hog算法对时空深度动作图提取动作的深度特征。
[0023]
作为本发明的一种优选方案,所述步骤2使用时空图卷积特征提取器提取骨骼数据中的动作特征。时空图卷积特征提取器使用到了图卷积神经网络(gcn)。gcn的公式定义如下:
[0024][0025]
λ
ii
=∑j(a
ij
+i
ij
)
[0026]
其中,f
out
和f
in
分别表示图卷积过程的输入与输出,w表示权重矩阵。a是伴随矩阵,i是单位矩阵。
[0027]
作为本发明的一种优选方案,所述步骤3中采用高可信均值样本融合算法,对步骤1与步骤2提取的两种动作特征进行融合。由于在样本空间中,噪声样本属于离群点,且一类动作中的噪声样本数量较少。因此,该算法使用四分位算法的思想,对于某一类的动作样本,首先剔除孤立的噪声样本,将剩下的样本称为高可信样本,并对高可信样本求取均值。使用均值表征该类动作。该算法公式如下:
[0028][0029][0030]
其中,c
sd
表示深度模态与骨骼模态的协方差。c
ss
与c
ss
分别表示深度模态和骨骼模态上的方差。i是单位矩阵。w是权重矩阵。
[0031]
作为本发明的一种优选方案,所述步骤4中,使用svm对特征分类后准确率的计算。准确率的计算如下公式所示:
[0032][0033]
其中,n表示不同类别样本的数量和,m表示类别数,ri表示预测的结果中对于类别i预测准确的样本数。
[0034]
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
[0035]
1、采用的时空深度动作图,在原有的dmi深度特征图基础上,通过添加了一层新的子dmi深度特征图,为原dmi深度特征图添加了充足的时间信息;
[0036]
2、采用时空图卷积特征提取器,使用图卷积的思想,使用较少的层数实现对骨骼数据特征的提取,相较于原有的骨骼网络,降低了时间的开销;
[0037]
3、使用高可信均值样本融合算法,能够克服现实生活中产生的噪声样本对算法的影响,同时使用均值样本表征动作,简化了融合算法的时间复杂度。
附图说明
[0038]
图1是本发明一种基于多模态数据融合的行为识别方法的流程图。
[0039]
图2是本发明提取动作深度特征的流程图。
[0040]
图3是本发明提取动作骨骼特征的流程图。
[0041]
图4是本发明高可信均值样本融合算法流程图。
具体实施方式
[0042]
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
[0043]
随着计算机视觉的不断发展,行为识别算法运用广泛。但由于单模态人体行为识别研究遇到瓶颈、噪声样本对实验造成副作用等问题,同时对行为识别的准确性要求较高。针对以上的问题,本发明设计了一种基于多模态数据融合的行为识别方法。
[0044]
如图1所示,本发明一种基于多模态数据融合的行为识别方法,包括以下步骤:
[0045]
1、深度数据动作特征提取。针对深度视频类型数据,在视频序列上提取到dmi深度特征图;然后,将原有的深度动作序列按照帧数分为相同长度的2段子序列,在各子序列上
分别提取子dmi深度特征图。将得到的两张子dmi特征图与dmi图像一起组成时空深度动作图,并使用hog算法提取动作的深度特征。
[0046]
提取时空深度动作图特征具体过程为:
[0047]
1.1在输入的深度视频上计算获得三视角的dmi深度特征图。公式如下所示:
[0048]
dmiv=max(i(h,w)v)
[0049]
其中,dmiv表示在v视角上的dmi特征图,视角分为f,s,d三种,分别对应前视角、侧视角与俯视角。(h,w)表示图像i上的坐标位置。max()表示求最大值。
[0050]
1.2将原有的深度视频分为相同帧数的两段子视频序列,分别在子视频序列上计算三视角子dmi深度特征图。公式如下所示:
[0051][0052]
其中,dmiv表示在v视角上的dmi特征图,视角分为f,s,d三种,分别对应前视角、侧视角与俯视角。i表示子序段数的序号。(h,w)表示图像i上的坐标位置。t代表当前的段数。n代表原深度视频的总帧数。max()表示求最大值。
[0053]
1.3将dmi深度特征图与子dmi深度特征图合为一个整体,称为时空深度动作图。一个动作样本使用一份时空深度动作图表示,一份时空深度动作图包含有9张灰度图。使用hog算法对时空深度动作图提取动作的深度特征。
[0054]
2、骨骼数据动作特征提取。针对骨骼序列数据,使用基于时空图卷积网络模型改进的时空图卷积特征提取器,直接处理骨骼序列,提取动作的骨骼特征。时空图卷积特征提取器使用到了图卷积神经网络(gcn)。gcn的公式定义如下:
[0055][0056]
λ
ii
=∑j(a
ij
+i
ij
)
[0057]
其中,f
out
和f
in
分别表示图卷积过程的输入与输出,w表示权重矩阵。a是伴随矩阵,i是单位矩阵。
[0058]
3、不同模态数据动作特征融合。在得到两种数据模态上的动作特征后,使用一种基于cca改良的高可信均值样本融合算法,融合两类特征,获得融合特征。由于在样本空间中,噪声样本属于离群点,且一类动作中的噪声样本数量较少。因此,该算法使用四分位算法的思想,对于某一类的动作样本,首先剔除孤立的噪声样本,将剩下的样本称为高可信样本,并对高可信样本求取均值。使用均值表征该类动作。该算法公式如下:
[0059][0060][0061]
其中,c
sd
表示深度模态与骨骼模态的协方差。c
ss
与c
ss
分别表示深度模态和骨骼模态上的方差。i是单位矩阵。w是权重矩阵。
[0062]
4、融合特征分类。使用svm对融合特征进行分类,并计算识别的准确率。准确率的计算如下公式所示:
[0063]
[0064]
其中,n表示不同类别样本的数量和,m表示类别数,ri表示预测的结果中对于类别i预测准确的样本数。
[0065]
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1