图像检索模型的训练方法、图像检索方法和相关设备与流程
本公开涉及图像检索,特别涉及一种图像检索模型的训练方法、图像检索方法和相关设备。
背景技术:
1、随着计算机视觉技术的发展,基于内容的图像检索(content-based imageretrieval,cbir)方法开始大量研究,这种“以图找图”的方法依据图像本身的颜色、形状、纹理等特征进行检索,避免文本描述和图像内容的语义差异。目前用于图像检索的度量学习模型在训练过程时使用的损失函数分为两类:pair loss(或说contrastive)和tripletloss,pair loss考虑成对样本间的相关性;triplet loss建模三元组间的相关性。其中,传统的triplet loss需要设定一个先验margin值,这个先验margin值关系到三元组间相关性的度,而一个良好的先验margin值难以给定,从而容易导致模型难以收敛,训练效果较差。
技术实现思路
1、本公开目的在于:提供了一种图像检索模型的训练方法、图像检索方法和相关设备,其在进行图像检索的度量学习模型的训练时,不需要设定先验margin值,从而使得模型训练可以快速收敛,具有更好的训练效果。
2、为达上述目的,本公开采用以下技术方案:一种图像检索模型的训练方法,包括:
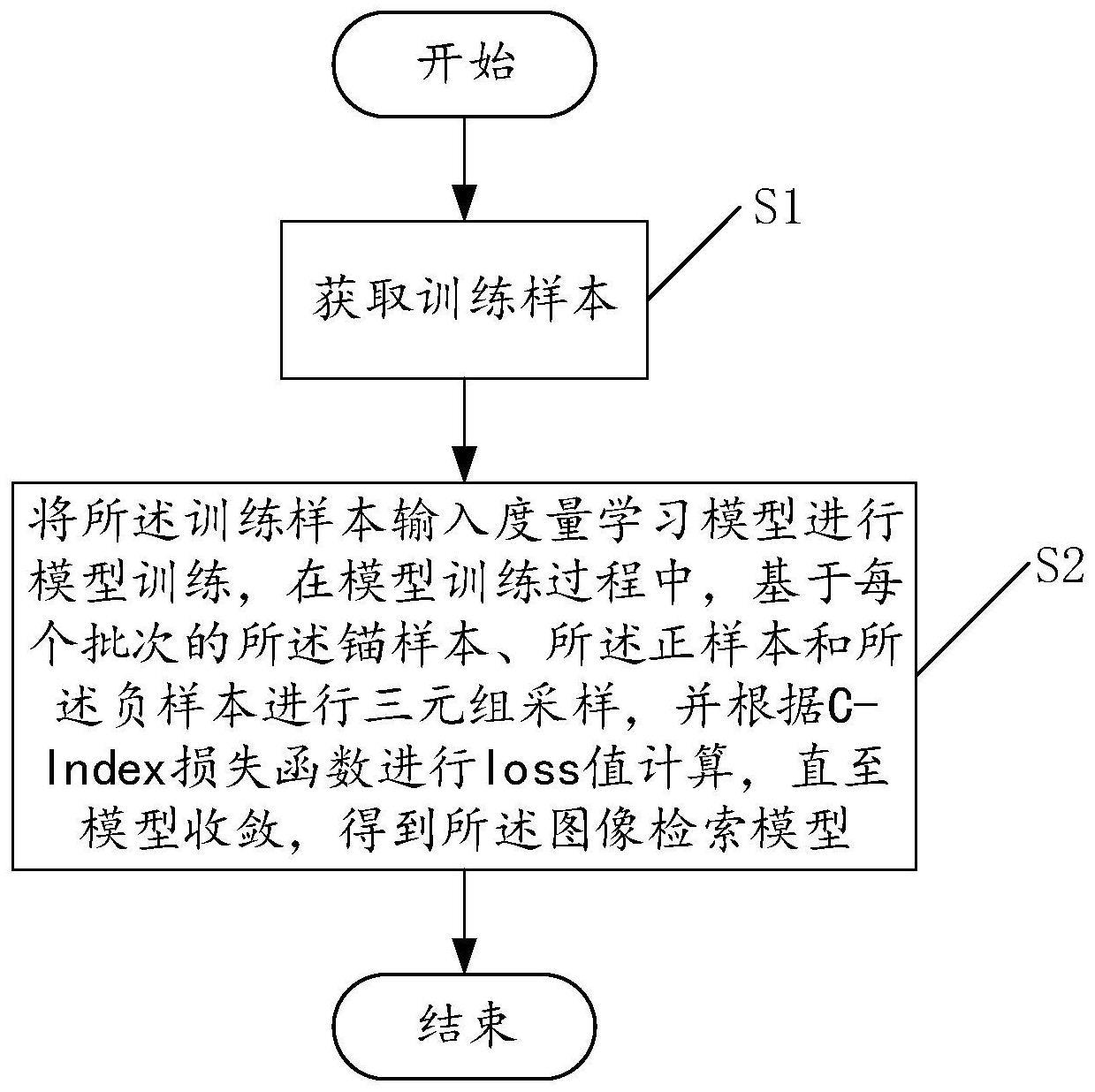
3、获取训练样本,所述训练样本包括锚样本、正样本和负样本;
4、将所述训练样本输入度量学习模型进行模型训练,在模型训练过程中,基于每个批次的所述锚样本、所述正样本和所述负样本进行三元组采样,并根据c-index损失函数进行loss值计算,直至模型收敛,得到所述图像检索模型。
5、本公开还提供了一种图像检索方法,包括:
6、获取待识别图像;
7、将所述待识别图像输入图像检索模型进行识别,利用所述图像检索模型从图像库中筛选得到与所述待识别图像的相似度大于阈值的相似图像,其中,所述图像检索模型由如上所述的图像检索模型的训练方法训练得到;
8、将所述相似图像输出到显示界面。
9、本公开还提供了一种图像检索模型的训练装置,包括:
10、第一获取模块,用于获取训练样本,所述训练样本包括锚样本、正样本和负样本;
11、训练模块,用于将所述训练样本输入度量学习模型进行模型训练,在模型训练过程中,基于每个批次的所述锚样本、所述正样本和所述负样本进行三元组采样,并根据c-index损失函数进行loss值计算,直至模型收敛,得到所述图像检索模型。
12、本公开还提供了一种图像检索装置,包括:
13、第二获取模块,用于获取待识别图像;
14、检索模块,用于将所述待识别图像输入图像检索模型进行识别,利用所述图像检索模型从图像库中筛选得到与所述待识别图像的相似度大于阈值的相似图像,其中,所述图像检索模型由如上所述的图像检索模型的训练方法训练得到;
15、输出模块,用于将所述相似图像输出到显示界面。
16、本公开还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
17、本公开还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的方法的步骤。
18、本公开中提供的一种图像检索模型的训练方法、图像检索方法和相关设备,训练时,首先获取训练样本,该训练样本包括锚样本、正样本和负样本。然后将训练样本输入度量学习模型进行模型训练,在模型训练过程中,基于每个批次的锚样本、正样本和负样本进行三元组采样,并根据c-index损失函数进行loss值计算,直至模型收敛,得到图像检索模型。应用时,首先获取待识别图像,然后将待识别图像输入图像检索模型进行识别,利用图像检索模型从图像库中筛选得到与待识别图像的相似度大于阈值的相似图像;最后将相似图像输出到显示界面。本公开通过在模型训练过程中使用c-index损失函数进行loss值计算,利用三元组样本的关系构建相关性关系来起到一致性学习效果,从而实现既不需要设定先验margin值,同时还能有效驱动模型学习,既能使模型训练快速收敛,还能使得训练所得的图像检索模型预测的效果符合真实的相关性(即一致性),从而有效提升模型训练效果(即训练完成后的图像检索模型在应用时的准确度更高)。
技术特征:
1.一种图像检索模型的训练方法,其特征在于,包括:
2.根据权利要求1所述的图像检索模型的训练方法,其特征在于,所述c-index损失函数为:其中,l为所述loss值,n表征一个批次的训练样本的数量,e表征三元组采样的样本集合,a表征所述锚样本,p表征所述正样本,n表征所述负样本,d(fθ(a),fθ(p))表征所述锚样本和所述正样本经模型预测的第一向量距离,d(fθ(a),fθ(n))表征所述锚样本和所述负样本经模型预测的第二向量距离。
3.根据权利要求2所述的图像检索模型的训练方法,其特征在于,若所述第一向量距离小于所述第二向量距离,则判定模型预测正确;
4.根据权利要求1所述的图像检索模型的训练方法,其特征在于,所述将所述训练样本输入度量学习模型进行模型训练,在模型训练过程中,基于每个批次的所述锚样本、所述正样本和所述负样本进行三元组采样,并根据c-index损失函数进行loss值计算,直至模型收敛,得到所述图像检索模型的步骤,包括:
5.一种图像检索方法,其特征在于,包括:
6.根据权利要求5所述的图像检索方法,其特征在于,所述相似图像的数量大于1个,所述将所述相似图像输出到显示界面的步骤,包括:
7.一种图像检索模型的训练装置,其特征在于,包括:
8.一种图像检索装置,其特征在于,包括:
9.一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,其中,所述处理器执行所述计算机程序时实现权利要求1—6中任一项所述方法的步骤。
10.一种计算机可读存储介质,其上存储有计算机程序,其中,所述计算机程序被处理器执行时实现权利要求1—6任一项所述的方法的步骤。
技术总结
本公开提供了一种图像检索模型的训练方法、图像检索方法和相关设备,通过在模型训练过程中使用C‑Index损失函数进行loss值计算,利用三元组样本的关系构建相关性关系来起到一致性学习效果,从而实现既不需要设定先验margin值,同时还能有效驱动模型学习,既能使模型训练快速收敛,还能使得训练所得的图像检索模型预测的效果符合真实的相关性(即一致性),从而有效提升模型训练效果(即训练完成后的图像检索模型在应用时的准确度更高)。
技术研发人员:方建生
受保护的技术使用者:广州视源电子科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!