一种基于训练模型的医疗领域实体及关系抽取方法与流程
本发明涉及一种基于训练模型的医疗领域实体及关系抽取方法,属于自然语言处理领域。
背景技术:
1、实体抽取也叫命名实体识别,是指在非结构化的自然语言文本中提取命名实体,并将其分类到提前预定好的类别中。关系抽取旨在提取实体之间存在的语义关系,如实体“成都”和实体“四川”它们的关系是“省会”。
2、传统的实体抽取技术都是基于“基于词典”或“有监督”的方法,所构建的知识图谱将无法适应新问题领域中的新词汇。例如,当构建一个新型冠状病毒的知识图谱时,它不能用预先建立的字典或数据集来构建,也不能频发的更新构建好的知识图谱。因此,当将像新型冠状病毒这样医疗领域的新词添加到现有知识图谱时,传统方法是很难实现的。要构建医疗领域的知识图谱,要解决的主要问题有:准确识别医疗领域实体;准确提取医疗领域实体之间的关系;生成医疗领域三元组以供构建医疗领域知识图谱。
技术实现思路
1、本发明提出一种基于预训练模型的医疗领域实体及关系抽取方法。本发明的目的在于准确识别医疗领域实体,准确提取医疗领域实体之间的关系,生成医疗领域三元组以供构建医疗领域知识图谱。
2、本发明技术方案如下:
3、首先基于自定义规则构建医疗领域本体,从不同结构的数据源中提取相关知识,自定义一些规则过滤掉收集到的知识中不属于医疗领域的文本知识,形成本医疗领域的本体;
4、然后基于biobert-bilstm-crf算法(bbc算法)进行医疗领域实体抽取,选择biobert模型作为词向量获取的特征表示层,bilstm模型用于深入学习医疗领域的全文特征信息,bilstm模型的输出序列在crf算法层进行处理,并与crf算法相结合,基于两个邻居之间的标签获得最优序列。
5、最后基于biobert-bilstm-attcrf(bbattc算法)进行医疗领域实体关系抽取。为了使模型能关注想要的重要信息,引入注意力机制。将上层的出层做本层的输入层,计算各个单词的注意力分数,实现重要信息的关注,且能提出实体之间的关系。
6、本发明的有益效果为:传统的实体抽取技术都是基于“基于词典”或“有监督”的方法,所构建的知识图谱将无法适应新问题领域中的新词汇。本发明可以更准确地识别医疗领域实体,更准确地提取医疗领域实体之间的关系,从而生成医疗领域三元组以供构建医疗领域知识图谱。
7、附图和附表说明
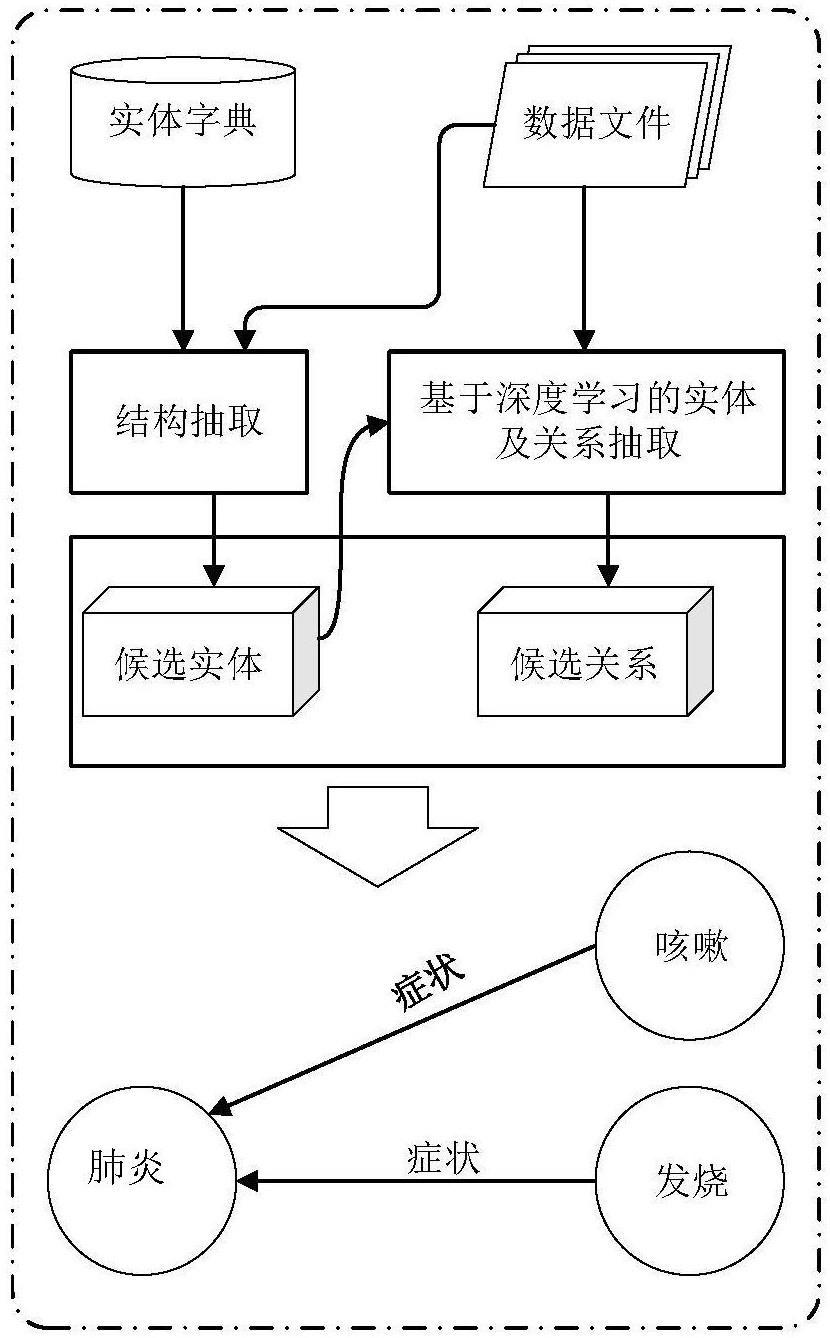
8、图1为本发明的算法整体框图;
9、图2为基于mesh获取医疗领域本体;
10、图3为非结构数据爬取流程;
11、图4为bert嵌入层示意图;
12、图5为lstm模型结构;
13、图6为基于联合预训练模型的医疗领域实体及关系抽取模型的整体结构;
14、图7为传统encoder-decoder框架;
15、图8为引入注意力机制后的encoder-decoder框架。
技术特征:
1.一种基于预训练模型的医疗领域实体及关系抽取方法,该方法包括以下步骤:
2.如权利要求1所属方法,其特征在于,步骤1提出一种基于自定义规则的医疗领域本体构建方法。基于自定义规则的医疗领域本体构建技术分为两步:基于结构化mech知识库的医疗领域本体生成;基于自定义规则的非结构化医疗领域文本知识处理。对结构化数据,本步骤针对新型冠状病毒构建本体(医疗领域)从医学主题词表(medical subjectheadings,(mesh)2)获取本体,(mesh)2是目前最权威最常用的标准医学主体词表。基于非结构化医疗领域文本知识处理,主要是通过爬虫技术,从维基百科等网站爬取医疗相关的非结构化数据,并对文本数据进行关键信息提取。
3.如权利要求1所属方法,其特征在于,步骤2提出一种基于医疗预训练模型的医疗领域实体抽取算法biobert+bilstm+crf。选择biobert模型作为词向量获取的特征表示层,使得在后面的bilstm层更加关注新型冠状病毒类的词语。bilstm模型用于深入学习医疗领域的全文特征信息,称为实体识别。bilstm模型的输出序列在crf算法层进行处理,并与crf算法相结合,基于两个邻居之间的标签获得最优序列,而融合注意力机制使两个具有关系的实体更加关注。
4.如权利要求1所属方法,其特征在于,步骤3提出一种融合注意力机制的医疗预训练模型医疗领域实体关系抽取算法biobert+bilstm+attcrf。为了使模型能关注想要的重要信息,引入注意力机制。将上层的出层做本层的输入层,计算各个单词的注意力分数,实现重要信息的关注,且能提出实体之间的关系。为了自动关注医疗领域实体之间的关系,在将传统的encoder-decoder框架加入注意力机制,在处理文本时,把encoder-decoder框架看作处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。
技术总结
本发明提出了一种基于预训练模型的医疗领域实体及关系抽取方法,所述方法包括以下步骤:首先基于自定义规则构建医疗领域本体,从不同结构的数据源中提取相关知识,自定义一些规则过滤掉收集到的知识中不属于医疗领域的文本知识,形成本医疗领域的本体;然后基于BioBERT‑BiLSTM‑CRF算法(BBC算法)进行医疗领域实体抽取;最后基于BioBERT‑BiLSTM‑AttCRF(BBAttC算法)进行医疗领域实体抽取。本发明主要研究医疗领域的实体及关系抽取,要解决的主要问题有:准确识别医疗领域实体;准确提取医疗领域实体之间的关系;生成医疗领域三元组以供构建医疗领域知识图谱,从而构建医疗领域的知识图谱。
技术研发人员:周焕来,李嘉豪,唐小龙,许文波,贾海涛,李金润,谭志昊,张博阳
受保护的技术使用者:成都量子矩阵科技有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!