一种任务驱动的视觉注意力预测方法、装置和系统
1.本发明属于计算机视觉技术领域,具体涉及一种任务驱动的视觉注意力预测方法、装置和系统。
背景技术:
2.视觉注意力预测是指对图像或视频中不同位置受到视觉关注的概率预测,被应用到各领域。现有的视觉注意力预测大多着眼于人生理本能的注意力研究,如cn101980248a的中国发明专利公开了一种基于改进视觉注意力模型的自然场景目标检测方法,根据亮度、颜色和方向等一些低级视觉特征来预测自然场景检测目标。cn110251076b的中国发明专利公开了一种融合视觉注意力基于对比度的显著性预测方法,凸显色彩对人眼注意力的引导。cn110827193a的中国发明专利公开了一种基于多通道特征的全景视频显著性检测方法。这些方法所用到的低级和高级的视觉特征预测视觉注意力都是以自下而上的刺激驱动,没有涉及结合自上而下信息(例如任务和目标)的注意力预测。任务等主观意识在引导人的视觉注意力方面是非常重要的,研究任务驱动的注意力具有重要意义。
3.在应用层面,目前视觉注意力预测的应用仅针对特定人群,没有实现普通人群在信息浏览、导航、搜索等交互任务下的视觉注意力预测。cn114092900a的中国发明专利公开了一种驾驶员视觉注意力预测方法。将预处理之后的图像数据输入结合卷积神经网络和transformer的注意力预测网络,训练得到注意力预测模型;将所述预处理图像输入所述注意力预测模型,输出得到注意力预测概率图。但是该技术没有提及到自上而下的驾驶员的认知层面,视觉注意力的预测会产生偏差,应用只局限于驾驶场景。cn111951637a的中国发明专利公开了一种任务情景相关联的无人机飞行员视觉注意力分配模式提取方法,对不同任务情景、不同疲劳等级下的飞行员注意力分配情形进行区分。但是该技术应用仅局限于无人机飞行驾驶场景。
技术实现要素:
4.鉴于上述,本发明的目的是提供一种任务驱动的视觉注意力预测方法、装置和系统,通过结合自下而上刺激驱动与自上而下任务引导,实现普通人群在信息浏览、导航、搜索等交互任务下的在更加准确地预测人类视觉注意力。
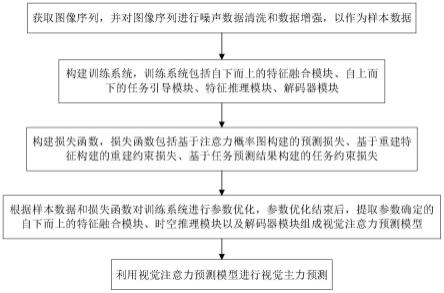
5.为实现上述发明目的,实施例提供的一种任务驱动的视觉注意力预测方法,包括以下步骤:
6.获取图像序列,并对图像序列进行噪声数据清洗和数据增强,以作为样本数据;
7.构建训练系统,训练系统包括自下而上的特征融合模块、自上而下的任务引导模块、特征推理模块、解码器模块,其中,自下而上的特征融合模块用于对输入的图像序列进行多低级视觉特征的提取和融合得到视觉特征;自上而下的任务引导模块用于对输入的任务信息进行特征提取后与视觉特征融合再经重建得到重建特征,根据重建特征进行任务预测得到任务预测结果;特征推理模块用于对输入的视觉特征进行特征再提取得到新特征;
解码器模块用于对输入的新特征进行视觉注意力预测并输出注意力概率图;
8.构建损失函数,损失函数包括基于注意力概率图构建的预测损失、基于重建特征构建的重建约束损失、基于任务预测结果构建的任务约束损失;
9.根据样本数据和损失函数对训练系统进行参数优化,参数优化结束后,提取参数确定的自下而上的特征融合模块、时空推理模块以及解码器模块组成视觉注意力预测模型;
10.利用视觉注意力预测模型进行视觉主力预测。
11.在一个实施例的所述自下而上的特征融合模块对输入的图像序列从色彩、对比度、方向特征三个方面提取低级视觉特征,然后采用自我注意机制对三个方面的低级视觉特征进行对齐后再进行特征相加,得到视觉特征。
12.在一个实施例的所述自上而下的任务引导模块中,任务信息以图上标签的形式呈现,其中,任务标签包括用作粗粒度提示的任务标签、用作细粒度提示的子任务标签;采用bert模型对图像上任务标签和子任务标签编码后再经过融合得到任务特征;视觉特征经过池化操作后再与任务特征融合得到融合特征;采用ave模型对融合特征进行重建以得到重建特征;采用多分类模型对重建特征进行任务预测得到任务预测结果。
13.在一个实施例的所述特征推理模块中,采用vgg模型对输入的视觉特征进行特征再提取得到新特征。
14.在一个实施例中,所述基于注意力概率图构建的预测损失包括基于整图的预测损失和基于像素的预测损失具体表示为:
[0015][0016][0017]
其中,a表示注意力概率图,表示注意力真值标签图,||
·
||1表示1-范数,a
ij
表示第i张图片第j个像素的注意力概率,表示第i张图片第j个像素的注意力真值标签,ω为注意力真值标签图中注意区域面积比,
⊙
表示点积操作,w和h分别表示图像的长和宽。
[0018]
在一个实施例中,所述基于重建特征构建的重建约束损失表示为:
[0019][0020]
其中,f
x
表示对输入的任务信息进行特征提取后与视觉特征融合得到的融合特征,f
x|z
表示重建特征,μ和σ分别表示根据融合特征f
x
学习得到的潜在特征fz的高斯分布的均值和方差;
[0021]
所述基于任务预测结果构建的任务约束损失表示为:
[0022][0023]
其中,y表示任务预测结果,表示任务真值,f
ce
(
·
)表示交叉熵损失的标准函数。
[0024]
在一个实施例中,所述利用视觉注意力预测模型进行视觉主力预测,包括:
[0025]
利用自下而上的特征融合模块对输入的图像进行多低级视觉特征的提取和融合得到视觉特征;
[0026]
利用特征推理模块对输入的视觉特征进行特征再提取得到新特征;
[0027]
利用解码器模块对输入的新特征进行视觉注意力预测并输出注意力概率图。
[0028]
为实现上述发明目的,实施例提供了一种任务驱动的视觉主力预测装置,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上执行的计算机程序,所述存储器中存有通过上述任务驱动的视觉主力预测方法构建的视觉注意力预测模型;所述处理器执行所述计算机程序时实现以下步骤:
[0029]
接收图像序列;
[0030]
调用视觉注意力预测模型对图像序列进行注意力预测,包括:利用自下而上的特征融合模块对输入的图像进行多低级视觉特征的提取和融合得到视觉特征;利用特征推理模块对输入的视觉特征进行特征再提取得到新特征;利用解码器模块对输入的新特征进行视觉注意力预测得到注意力概率图;
[0031]
输出注意力概率图并以热力图形式进行可视化呈现。
[0032]
为实现上述发明目的,实施例提供了一种任务驱动的视觉主力预测系统,包括客户端和服务器,所述客户端用于通过页面接口接收输入的图像序列,并将图像序列传输至服务器;还用于对注意力概率图进行可视化呈现;
[0033]
所述服务器挂载有上述任务驱动的视觉主力预测方法构建的视觉注意力预测模型,用于利用视觉注意力预测模型对传入的图像序列进行注意力预测,并返回注意力概率图至客户端。
[0034]
与现有技术相比,本发明具有的有益效果至少包括:
[0035]
通过基于自下而上的多低级视觉特征的融合和任务信息的引导来构建视觉注意力预测模型,使得模型能够实现更普通人群在信息浏览、导航、搜索等交互任务下的视觉注意力预测,提高基于任务状态下预测结果的准确度。
附图说明
[0036]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。
[0037]
图1是实施例提供的任务驱动的视觉主力预测方法的流程图;
[0038]
图2是实施例提供的训练系统的结构示意图。
具体实施方式
[0039]
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。
[0040]
图1是实施例提供的任务驱动的视觉主力预测方法的流程图。如图1所示,实施例提供的任务驱动的视觉主力预测方法,包括以下步骤:
[0041]
步骤1,获取图像序列,并对图像序列进行噪声数据清洗和数据增强,以作为样本数据。
[0042]
实施例,通过眼动仪采集用户在不同任务(包括信息浏览、导航、搜索等交互任务)驱动下的图像序列数据集,每张图像与任务相关的物体,任务和子任务都被打上标签。为了使图像序列数据集可用于任务驱动的注意力预测,所有图像中均额外注释了注意力对象。数据集包括无任务驱动的自然状态下人图像记录和特定任务驱动下的图像记录。
[0043]
实施例中,对输入图片进行噪声数据清洗和数据增强,并保证被试者在所有任务中都不重叠。
[0044]
步骤2,构建训练系统,训练系统包括自下而上的特征融合模块、自上而下的任务引导模块、特征推理模块、解码器模块。
[0045]
如图2所示,实施例提供的训练系统包括自下而上的特征融合模块(bu)、自上而下的任务引导模块(td)、特征推理模块(fi)、解码器模块(de)。其中,特征融合模块(bu)用于对输入的图像序列进行多低级视觉特征的提取和融合得到视觉特征;任务引导模块(td)用于对输入的任务信息进行特征提取后与视觉特征融合再经重建得到重建特征,根据重建特征进行任务预测得到任务预测结果;特征推理模块(fi)用于对输入的视觉特征进行特征再提取得到新特征;解码器模块(de)用于对输入的新特征进行视觉注意力预测并输出注意力概率图。
[0046]
在特征融合模块(bu)中,将图像中的色彩、对比度、方向特征融合在一起,为注意力预测提供自下而上的线索,具体对输入的图像序列从色彩、对比度、方向特征三个方面提取低级视觉特征;然后为了更好地融合多个低级视觉特征,采用自我注意机制对三个方面的低级视觉特征进行对齐,对齐后的低级视觉特征fh、fc、fd相加成为自下而上的视觉特征f
bu
:
[0047]fbu
=fh+fc+fd[0048]
实施例中,任务信息以图上标签的形式呈现,被嵌入作为特征与自下而上的线索相结合,任务也被制定为约束来指导预测任务驱动的注意力。一个任务通常由几个子任务组成,图像可能具有相同的任务标签,但具有不同的子任务标签。任务标签是粗粒度提示,而子任务标签是细粒度提示。
[0049]
bert模型允许探索不同单词的语义关系,有助于构建一个强大的特征表示来编码任务信息。因此,在任务引导模块(td)中,采用bert模型对图像上任务标签和子任务标签编码后再经过融合得到自上而下的任务特征f
td
。视觉特征f
bu
经过池化操作后得到特征特征再与任务特征融合f
td
得到融合特征f
x
,表示为:
[0050][0051]
其中,fc(
·
)表示融合操作cat。
[0052]
为了获得更好的融合特征表示,在任务引导模块(td)中,还采用ave(variational autoencoder)模型对融合特征进行重建以得到重建特征,即首先在融合特征f
x
的基础上学习一个潜在特征fz,然后在潜在特征fz的基础上计算出重建特征f
x|z
,公式表示为:
[0053]
[0054]
其中,表示ave模型,μ和σ分别表示根据融合特征f
x
学习得到的潜在特征fz的高斯分布的均值和方差。
[0055]
在任务引导模块(td)中,采用多分类模型对重建特征f
x|z
进行任务预测得到任务预测结果y,公式表示为:
[0056][0057]
其中,表示多分类模型,可以为全连接网络。
[0058]
在特征推理模块(fi)中,图像序列对应的视觉特征f
bu
被输入到vgg网络中,通过探索图片特征与任务特征的关联来学习更准确的新特征fb,用公式表示为:
[0059][0060]
其中,表示vgg网络。
[0061]
在解码器模块(de)中,新特征fb被采样为概率图,并显示为黑白热力图形式,以表示人类视觉注意力的可能位置,即对输入的新特征fb进行视觉注意力预测并输出像素级的注意力概率图a,公式表示为:
[0062][0063]
其中,表示解码操作,以预测视觉注意力概率。
[0064]
步骤3,构建损失函数,损失函数包括基于注意力概率图构建的预测损失、基于重建特征构建的重建约束损失、基于任务预测结果构建的任务约束损失。
[0065]
实施例中,构建的损失函数表示为:
[0066][0067]
其中,表示基于整图的预测损失,表示基于像素的预测损失,预测损失和组成基于注意力概率图构建的预测损失,表示基于重建特征构建的重建约束损失,表示基于任务预测结果构建的任务约束损失,λ1、λ2、λ3以及λ4均表示单个损失的权重。
[0068]
实施例中,预测损失和分别表示为:
[0069][0070][0071]
其中,a表示注意力概率图,表示注意力真值标签图,||
·
||1表示1-范数,a
ij
表示第i张图片第j个像素的注意力概率,表示第i张图片第j个像素的注意力真值标签,该真值标签用1和0表示,其中,1表示注意区域,0表示非注意区域,ω为注意力真值标签图中注意区域面积比,
⊙
表示点积操作,w和h分别表示图像的长和宽,预测损失表示了a与
的重叠,从整体角度衡量a与的差异,预测损失表示带权重的交叉熵,从像素级角度衡量a与的差异。
[0072]
实施例中,重建约束损失表示为:
[0073][0074]
其中,f
x
表示对输入的任务信息进行特征提取后与视觉特征融合得到的融合特征,f
x|z
表示重建特征,μ和σ分别表示根据融合特征f
x
学习得到的潜在特征fz的高斯分布的均值和方差。
[0075]
该重建约束损失是通过最小化f
x
和f
x|z
之间的差异,重建约束有助于学习融合特征的稳定表示,以削弱自上而下的任务特征f
td
和自下而上的视觉特征f
bu
之间的差距。
[0076]
实施例中,任务约束损失表示为:
[0077][0078]
其中,y表示任务预测结果,表示任务真值,f
ce
(
·
)表示交叉熵损失的标准函数。
[0079]
该任务约束损失的目的是通过将自上而下的任务信息引导引入网络的反向传播,鼓励模型预测任务驱动的注意力。
[0080]
上述两个约束条件用于加强特征表示和任务指导,上述两个约束并没有直接加在实际用于注意力预测的视觉特征f
bu
上,但可以更新整个网络参数,从而更新视觉特征f
bu
以传达自上而下和自下而上的信息。
[0081]
步骤4,根据样本数据和损失函数对训练系统进行参数优化,参数优化结束后,提取参数确定的自下而上的特征融合模块、时空推理模块以及解码器模块组成视觉注意力预测模型。
[0082]
实施例中,将步骤1的样本数据中的图像序列输入至训练系统中,经过计算得到视觉特征、任务特征、任务预测结果、重建特征以及注意力概率图,然后根据损失函数计算损失,利用损失更新训练系统的参数,并进行十字交叉验证,参数优化结束后,提取参数确定的自下而上的特征融合模块、时空推理模块以及解码器模块组成视觉注意力预测模型,该视觉注意力预测模型可结合自下而上的视觉特驱动和自上而下任务引导的视觉注意力预测,生成注意力概率图。
[0083]
步骤5,利用视觉注意力预测模型进行视觉主力预测。
[0084]
实施例中,利用视觉注意力预测模型进行视觉主力预测,包括:利用自下而上的特征融合模块对输入的图像进行多低级视觉特征的提取和融合得到视觉特征;利用特征推理模块对输入的视觉特征进行特征再提取得到新特征;利用解码器模块对输入的新特征进行视觉注意力预测并输出注意力概率图,该概率图以热力图的形式呈现到系统应用中,可视化用户视觉注意重点,由于是输入的图像序列,带有时间信息,这样根据热力图形式呈现的注意力概率图即可以展示视觉注意力区域,该可以获得视觉注意力时长,支持信息浏览、导航、搜索等交互任务下的视觉注意力预测。
[0085]
基于同样的发明构思,实施例还提供了一种任务驱动的视觉主力预测装置,包括存储器、处理器以及存储在存储器中并可在处理器上执行的计算机程序,存储器中存有通
过上述任务驱动的视觉主力预测方法构建的视觉注意力预测模型;处理器执行所述计算机程序时实现以下步骤:
[0086]
步骤1,接收图像序列;
[0087]
步骤2,调用视觉注意力预测模型对图像序列进行注意力预测,包括:利用自下而上的特征融合模块对输入的图像进行多低级视觉特征的提取和融合得到视觉特征;利用特征推理模块对输入的视觉特征进行特征再提取得到新特征;利用解码器模块对输入的新特征进行视觉注意力预测得到注意力概率图;
[0088]
步骤3,输出注意力概率图并以热力图形式进行可视化呈现。
[0089]
在应用中,存储器可以为在近端的易失性存储器,如ram,还可以是非易失性存储器,如rom,flash,软盘,机械硬盘等,还可以是远端的存储云。处理器可以为中央处理器(cpu)、微处理器(mpu)、数字信号处理器(dsp)、或现场可编程门阵列(fpga),即可以通过这些处理器实现图像序列进行注意力预测的步骤。
[0090]
基于同样的发明构思,实施例还提供了一种任务驱动的视觉主力预测系统,包括客户端和服务器,其中,客户端用于通过页面接口接收输入的图像序列,并将图像序列传输至服务器;服务器挂载有上述任务驱动的视觉主力预测方法构建的视觉注意力预测模型,用于利用视觉注意力预测模型对传入的图像序列进行注意力预测,并返回注意力概率图至客户端。客户端还用于对注意力概率图进行可视化呈现。
[0091]
实施例提供的任务驱动的视觉注意力预测方法、装置和系统,通过基于自下而上的多低级视觉特征的融合和任务信息的引导来构建视觉注意力预测模型,使得模型能够实现更普通人群在信息浏览、导航、搜索等交互任务下的视觉注意力预测,提高基于任务状态下预测结果的准确度。
[0092]
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1