文本识别模型生成方法、文本识别方法、设备及存储介质与流程
1.本说明书实施例涉及数据处理技术领域,尤其涉及文本识别模型生成方法、文本识别方法、设备及存储介质。
背景技术:
2.近年来,伴随着人工智能(artificial intelligence,ai)领域技术的不断发展和创新,光学字符识别(optical character recognition,ocr)取得了巨大的突破,并成为金融、交通、物流、教育、政务等各个垂直行业数字转型、智能升级及融合创新的重要基础能力。由于移动互联网的日益成熟和产业互联网的加速发展,ocr的服务载体、形式呈现出多样化特征,兼顾性能和效率的离线ocr已成为未来技术发展的趋势之一。离线ocr成为继公有云应用程序接口(application program interface,api)、私有化部署之后的一种全新产品形态,是对泛ocr体系边界的拓展,相比在线服务具有低成本部署、零流量消耗、保护隐私、所见即所得等优势。
3.教育智能硬件通过集成ai算法、软件、内容等形式多样化的产品功能,帮助学生获得个性化学习内容并合理改善学习方法,帮助家长辅导和监督孩子的学习情况,帮助老师改善教学内容和减轻教学压力。
4.根据艾瑞的估算,2020年教育智能硬件市场规模为343亿元,预计2024年有望接近 1000亿元,其中新兴品类如ai词典笔的增长速度尤为突出。ai词典笔是一款面向学生用户,通过扫描、语音等操作学习语言的全新一代人工智能词典笔,能帮助学生解决听说读写、背译查解等问题。ai词典笔最核心的基础功能是扫描查词由于是离线算法,词典笔可以在无网环境下正常使用,极大地提升看便捷性和可用性。而离线ocr是文字信息提取的入口,一旦识别错误,会导致整体功能不可用,同时由于是面向用户的消费品,需要重点考虑用户体验和硬件成本,因此如何在算力有限的电子设备上做到快速、高精准的ocr识别是业界面临的一个技术难题。
5.背景技术部分的内容仅仅是公开人所知晓的技术,并不当然代表本领域的现有技术。
技术实现要素:
6.有鉴于此,本说明书实施例提供一种文本识别模型生成方法、文本识别方法、设备及存储介质,对于算力有限的电子设备,能够提高文本识别的精度及效率。
7.首先,本说明书实施例提供了一种文本识别模型生成方法,包括:
8.分别获取文本行图像训练集和字符图像训练集;
9.将所述文本行图像训练集输入预设的文本行识别模型,对所述文本行识别模型进行训练,将所述字符图像训练集输入预设的单字检测和识别模型,对所述单字检测和识别模型进行训练;
10.获取文本行图像测试集,输入所述文本行识别模型,输出文本行识别结果;
11.评估所述文本行识别结果中各字符的置信度和能量;
12.在确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符测试子图像;
13.对于各字符测试子图像,输入所述单字检测和识别模型,输出相应的字符识别结果;
14.结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像测试集的字符识别测试结果;
15.基于所述字符识别测试结果是否达到预设的性能评估指标确定是否对所述文本行识别模型以及所述单字检测和识别模型继续进行训练,直至所述字符识别测试结果达到预设的性能评估指标。
16.可选地,所述分别获取文本行图像训练集和字符图像训练集,包括:
17.将第一文本行图像训练集和第二文本行图像训练集按照相应训练批次预设的第一混合比例进行混合,得到所述文本行图像训练集;其中,所述第一文本行图像训练集为对采集的真实文本图像进行裁切得到;所述第二文本行图像训练集为通过收集不同字体的字库,并按照文本行中文字的排布规则合成文本行得到;
18.将第一字符图像训练集和第二字符图像训练集按照相应训练批次预设的第二混合比例进行混合,得到所述字符图像训练集;其中,所述第一字符图像训练集为对采集的真实文本图像进行裁切得到;所述第二字符图像训练集为通过收集不同字体的字库,并按照文本行中文字的排布规则合成文本图像后进行裁切得到。
19.可选地,将第一文本行图像训练集和第二文本行图像训练集按照相应训练批次预设的第一混合比例进行混合,以及将第一字符图像训练集和第二字符图像训练集按照相应训练批次预设的第二混合比例进行混合,使得经所述文本行图像训练集训练得到的所述文本行识别模型和经所述字符图像训练集训练得到的所述单字检测和识别模型达到预设的泛化性能指标阈值。
20.可选地,所述文本行识别模型包括:卷积循环神经网络。
21.可选地,所述方法还包括:对所述文本行图像训练集和字符图像训练集执行图像增广操作。
22.可选地,所述对所述文本行图像训练集和字符图像训练集执行图像增广操作,包括:
23.对所述文本行图像训练集和字符图像训练集按照相应训练批次设置的超参数执行图像增广操作,所述超参数随着训练批次的增加而衰减。
24.本说明书实施例还提供了一种文本识别方法,包括:
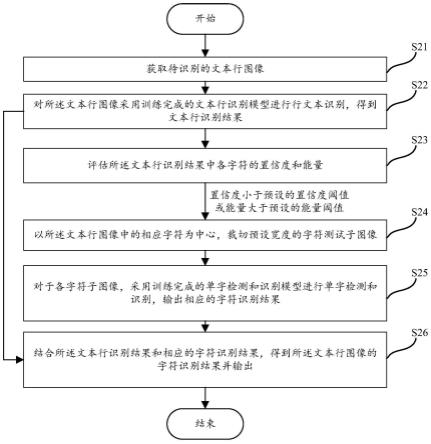
25.获取待识别的文本行图像;
26.对所述文本行图像采用训练完成的文本行识别模型进行行文本识别,得到文本行识别结果;
27.评估所述文本行识别结果中各字符的置信度和能量;
28.在确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,以所述文本行图像中的相应字符为中心,裁切预设宽
度的字符子图像;
29.对于各字符子图像,采用训练完成的单字检测和识别模型进行单字检测和识别,输出相应的字符识别结果;
30.结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像的字符识别结果。
31.可选地,所述文本行识别模型包括:卷积循环神经网络。
32.可选地,按照如下公式评估所述文本行识别结果中各字符的能量:
[0033][0034]
其中,x表征所述字符的图像,t表征温度超参数,k表征类别数,f为文本行识别模型网络,fi(x)表示k个类别数中的第i个类别对应的特征值。
[0035]
可选地,在对所述文本行图像采用训练完成的文本行识别模型进行行文本识别之前,还包括:
[0036]
对所述待识别的文本行图像进行图像增强预处理。
[0037]
本说明书实施例还提供了一种文本识别系统,包括:
[0038]
获取单元,适于获取待识别的文本行图像;
[0039]
文本行识别单元,适于对所述文本行图像采用训练完成的文本行识别模型进行行文本识别,得到文本行识别结果;
[0040]
评估单元,适于评估所述文本行识别结果中各字符的置信度和能量;
[0041]
裁切单元,适于在所述评估单元确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符子图像;
[0042]
字符识别单元,对于各字符子图像,适于采用训练完成的单字检测和识别模型进行单字检测和识别,输出相应的字符识别结果;
[0043]
识别结果输出单元,适于结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像的字符识别结果并输出。
[0044]
本说明书实施例还提供了一种电子设备,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机程序,其中,所述处理器运行所述计算机程序时执行前述任一实施例所述的文本识别模型生成方法或前述任一实施例所述的文本识别方法的步骤。
[0045]
本说明书实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,其中,所述计算机程序运行时执行前述任一实施例所述的文本识别模型生成方法或前述任一实施例所述的文本识别方法的步骤。
[0046]
采用本说明书实施例的文本识别模型生成方法,通过分别获取文本行图像训练集和字符图像训练集,并采用所述文本行图像训练集对文本行识别模型进行训练,通过字符图像训练集对单字检测和识别模型进行训练,并通过文本行图像测试集进行测试,其中,对于文本行识别结果,通过评估所述文本行识别结果中各字符的置信度和能量,在确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符测试子图像,对于各字符测试子图像,输入所述单字检测和识别模型,输出相应的字符识别结果,并结合
所述文本行识别结果和相应的字符识别结果,得到所述文本行图像测试集的字符识别测试结果,之后,基于所述字符识别测试结果是否达到预设的性能评估指标确定是否对所述文本行识别模型以及所述单字检测和识别模型继续进行训练,直至所述字符识别测试结果达到预设的性能评估指标。采用上述文本识别模型生成方法所得到的文本识别模型,引入能量联合置信度对文本行识别结果进行综合判断,能够更加高效地挑选出需要进行单字识别和检测的字符;并且,由于结合了行识别与用于生僻字识别的单字检测和识别模型进行综合识别,因而采用所述文本识别模型进行字符识别,能够提高字符识别精度。
[0047]
而采用本说明书实施例的文本识别方法对文本行图像进行字符识别,通过评估所述文本行识别结果中各字符的置信度和能量,能够准确地区分出常见字与生僻字,在确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,即在确定所述字符为生僻字时,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符子图像,之后,对于各字符子图像,采用训练完成的单字检测和识别模型进行单字检测和识别,输出相应的字符识别结果,结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像的字符识别结果。一方面,由于整个识别过程,引入能量联合置信度对文本行识别结果进行综合判断,能够更加高效地挑选出需要进行单字识别和检测的字符;另一方面,由于结合了行识别与用于生僻字识别的单字检测和识别模型进行综合识别,因而采用所述文本识别模型进行字符识别,能够提高字符识别精度。
[0048]
进一步地,通过将对采集的真实文本图像进行裁切得到的第一文本行图像训练集和通过收集不同字体的字库,并按照文本行中文字的排布规则合成文本行得到的第二文本行图像训练集按照相应训练批次预设的第一混合比例进行混合,得到所述文本行图像训练集;以及将通过对采集的真实文本图像进行裁切得到的第一字符图像训练集和通过收集不同字体的字库,并按照文本行中文字的排布规则合成文本图像后进行裁切得到的第二字符图像训练集按照相应训练批次预设的第二混合比例进行混合,得到所述字符图像训练集,也即训练过程中通过合成的第二文本行图像训练集和第二字符图像训练集的加入,能够更加高效地得到满足训练要求的文本行图像训练集和字符图像训练集,进而能够提高文本识别模型的训练效率。
[0049]
进一步地,通过将第一文本行图像训练集和第二文本行图像训练集按照相应训练批次预设的第一混合比例进行混合,以及将第一字符图像训练集和第二字符图像训练集按照相应训练批次预设的第二混合比例进行混合,使得经所述文本行图像训练集训练得到的所述文本行识别模型和经所述字符图像训练集训练得到的所述单字检测和识别模型达到预设的泛化性能指标阈值,使得训练得到的文本识别模型能够更加有效地表达真实文本图像数据的特征,提高所述文本识别模型的泛化能力。
[0050]
将文本行图像输入卷积循环神经网络,可以先使用其中的卷积神经网络提取文本行图像的特征,再采用双向长短期记忆网络将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层进行预测得到文本序列,由于利用双向长短期记忆网络和转录层能够学习到文本行图像的上下文特征,因而能够提高文本识别准确率,提高文本识别模型的鲁棒性。
[0051]
进一步地,通过对所述文本行图像训练集和所述字符图像训练集执行图像增广操作,能够提高所述文本识别模型在通用场景下的字符识别率。
[0052]
进一步地,通过对所述文本行图像训练集和字符图像训练集按照相应训练批次设置的超参数执行图像增广操作,由于所述超参数随着训练批次的增加而衰减,可以在训练过程中逐渐增强原始的文本行图像训练集和字符图像训练集的拟合程度,进一步提高通用场景的字符识别率。
附图说明
[0053]
为了更清楚地说明本说明书实施例的技术方案,下面将对本说明书实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面所描述的附图仅仅是本说明书的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0054]
图1示出了本说明书实施例中一种文本识别模型生成方法的流程图。
[0055]
图2示出了本说明书实施例中一种文本识别方法的流程图。
[0056]
图3示出了本说明书实施例中一种文本识别方法的场景示例示意图。
[0057]
图3a示出了图3所示的本说明书实施例中的一待识别的文本行图像。
[0058]
图3b示出了本说明书实施例中图3a所示待识别的文本行图像对应的文本行识别结果。
[0059]
图3c示出了本说明书实施例中图3b所示的文本行识别结果中各个字符对应的置信度和能量。
[0060]
图3d示出了本说明书实施例中对于图3a所示的文本行图像所得到的部分字符子图像。
[0061]
图3e示出了本说明书实施例中图3d对应的字符子图像输入预设的单字检测和识别模型后得到的字符识别结果。
[0062]
图3f示出了本说明书实施例中结合图3b和图3e的字符识别结果得到的文本识别结果。
[0063]
图4示出了本说明书实施例中一种文本识别系统的结构示意图。
[0064]
图5示出了本说明书实施例中一种电子设备的结构示意图。
具体实施方式
[0065]
如前所述,在算力有限的电子设备上做到快速、高精准的ocr识别是业界面临的一个技术难题,尤其是对于具有长尾分布特性以及包含大量的形近字的文字,如何提高文本识别的精度及效率是亟待解决的技术问题。
[0066]
针对上述问题,本说明书实施例的一个方面,提供了一种文本识别模型生成方法,一方面,通过引入能量联合置信度对文本行识别结果进行综合判断,能够更加高效地挑选出需要进行单字识别和检测的字符;另一方面,结合行识别与用于生僻字识别的单字检测和识别模型进行综合识别,因而采用所述文本识别模型进行字符识别,能够提高字符识别精度。
[0067]
针对上述问题,本说明书实施例的另一个方面,提供了一种文本识别方法,一方面,由于整个识别过程,引入能量联合置信度对文本行识别结果进行综合判断,能够更加高效地挑选出需要进行单字识别和检测的字符;另一方面,由于结合了行识别与用于生僻字
识别的单字检测和识别模型进行综合识别,因而采用所述文本识别模型进行字符识别,能够提高字符识别精度。
[0068]
为使本领域技术人员更好地理解和实施,以下对本发明实施例的构思、原理及优点等,通过具体实施例并结合具体应用场景和附图,进行详细描述。
[0069]
为了使得文本识别模型能够达到预期的性能指标,需要对文本识别模型预先进行训练集测试,直至其满足预期的性能指标需求,则生成所需要的文本识别模型。为使本领域技术人员更好地理解和实施,以下首先结合具体应用示例及附图对文本识别模型生成过程进行详细介绍。
[0070]
参照图1所示的文本识别模型生成方法的流程图,在本发明一些实施例中,可以采用如下步骤生成用于文本字符识别的文本识别模型:
[0071]
s11,分别获取文本行图像训练集和字符图像训练集。
[0072]
在具体实施中,可以通过识别出文本图像集中各文本图像中各行的区域并进行裁切得到所述文本行图像训练集。所述字符图像训练集可以通过识别出文本行图像中字符并以各字符为中心按照预设宽度分别进行裁切得到所述字符图像训练集,也可以先对获取的文本图像集中各文本图像先进行行裁切,得到文本行图像,再对得到的文本行图像进行字符裁切得到,或者直接对获取的文本图像集进行字符识别并以识别得到的字符为中心按照预设的区域范围直接进行裁切得到。
[0073]
在具体实施中,可以通过收集真实的文本图像获取所述文本行图像训练集和所述字符图像训练集,也可以通过人工合成方式得到所述文本行图像训练集和所述字符图像训练集。
[0074]
在具体实施中,为了兼顾文本识别模型的训练效率及训练结果的鲁棒性,可以将收集得到的真实的文本行图像和合成的文本行图像进行混合得到所述文本行图像训练集,将收集得到的真实的字符图像和人工合成的字符图像进行混合得到所述字符图像训练集。
[0075]
s12,将所述文本行图像训练集输入预设的文本行识别模型,对所述文本行识别模型进行训练,将所述字符图像训练集输入预设的单字检测和识别模型,对所述单字检测和识别模型进行训练。
[0076]
在本发明一些实施例中,可以采用循环神经网络(recurrent neural network,rnn),在具体实施中,所采用的文本行识别模型也可以为rnn与其他的神经网络或算法结合形成的组合模型,或者是在rnn基础上进一步演化、变形或扩展的rnn。
[0077]
作为一可选示例,所述文本行识别模型可以为卷积循环神经网络(convolutionalrecurrent neural network,crnn)。crnn主要用于端到端的对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,即基于图像的序列识别。
[0078]
具体而言,crnn的整个网络结构包括三个部分:卷积层、循环层和转录层。作为一具体示例,首先,在卷积层,可以使用深度cnn,对输入的文本行图像提取特征,得到特征图;之后,在循环层,可以使用双向rnn,更具体地,可以为深层rnn,例如双向长短期记忆网络(bi-directional long-short term memory,bilstm)对特征序列进行预测,对特征序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;之后,在转录层,可以使用联结主义时间分类(connectionist temporal classification,ctc)损失函数,将从循环层获
取的一系列标签分布转换为最终的标签序列。
[0079]
其中,ctc是一种损失函数计算方法,训练样本无须对齐,其特点是通过引入空格 (blank)字符,解决有些位置没有字符的问题,并且通过递推,可以快速计算梯度。
[0080]
具体而言,对于lstm,有训练集合s={(x1,z1),(x2,z2),...,(xn,zn)},其中,x是图像经过cnn计算获得的特征图,z是图像对应的ocr字符标签,标签里面没有blank字符。通过梯度调整lstm的参数w,使得对于输入样本π∈b-1
(z)时有p(l|x)取得最大。单独来看ctc输入(即lstm输出)y矩阵中的某一个值(注意与含义相同,都是在t时π
t
=lk)的概率:
[0081][0082]
上述公式中α
t
(lk)β
t
(lk)是通过递推计算的常数,任何时候均可以通过递推快速获得,因此可以快速计算梯度之后按照梯度训练即可。
[0083]
作为另一可选示例,所述文本行识别模型可以为cnn结合seq2seq模型结构以及注意力(attention)模型结构,其中,seq2seq模型结构属于编码器-解码器结构,其基本思想是利用两个rnn,一个rnn作为编码器,另一个rnn作为解码器,attention模型结构可以让编码器编码出的c向量和解码器解码过程中的每一个书屋进行加权运算,在解码的每一个过程中调整权重到不一样的c向量。
[0084]
可以理解的是,本说明书实施例中并不限定所采用的具体的文本行识别模型的类型,本领域技术人员可以根据实际需求选择实施。
[0085]
在本发明一些实施例中,通过单字检测和识别模型可以先检测出单字,再用字典识别出具体是哪个字。本发明实施例中并不限定所采用的单字检测和识别模型的具体类型,作为可选示例,所述单字检测和识别模型可以为区域建议网络(region proposal networks,rpn) 结构模型,或者为带角度的区域建议网络(rotation region proposal networks,rrpn)结构模型,或者为rcnn结构模型,也可以为快速循环卷积神经网络(fast-recurrent convolutionalneural network,fast-rcnn)结构模型等或其结合。
[0086]
s13,获取文本行图像测试集,输入所述文本行识别模型,输出文本行识别结果。
[0087]
s14,评估所述文本行识别结果中各字符的置信度和能量,在确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,执行步骤s15。
[0088]
s15,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符测试子图像。
[0089]
在具体实施中,可以通过如下公式计算置信度:
[0090][0091]
其中,x表征所述字符的图像,k表征类别数,yi表示k个类别中第i个类别对应的特征值,f为文本行识别模型网络。
[0092]
在具体实施中,可以按照如下公式评估所述文本行识别结果中各字符的能量:
[0093][0094]
其中,x表征所述字符的图像,t表征温度超参数,k表征类别数,f为文本行识别模型网络,fi(x)表示k个类别数中的第i个类别对应的特征值。
[0095]
在具体实施中,可以将生僻字定义为分布外检测(out of distribution,ood)问题,也可以称为异常样本检测问题,结合字符的能量和置信度进行综合判断,使得生僻字和常见字在能量分布上有明显的区分界面,从而能够更加高效地挑选出文本行图像中需要进行单字检测和识别的部分。
[0096]
在具体实施中,由于生僻字一般不容易识别,因此其对应的置信度通常较小,而生僻字的能量分布一般较大,即生僻字的能量值较大,因此若某一字符的置信度小于一预设的置信度阈值或其能量大于一预设的能量阈值,则可以将其作为生僻字,将其进一步输入所述单字检测和识别模型完成更加准确的单字识别。
[0097]
其中,所述字符预设的置信度阈值或能量阈值可以通过训练网络后,对样本进行分析,根据统一得到的经验值进行设定。本说明书实施例中并不限定具体的置信度阈值或能量阈值,具体可以依据文本的语言类型、训练所用的文本库、字库以及所采用的训练网络等因素进行设定。
[0098]
s16,对于各字符测试子图像,输入所述单字检测和识别模型,输出相应的字符识别结果。
[0099]
s17,结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像测试集的字符识别测试结果。
[0100]
s18,确定所述字符识别测试结果是否达到预设的性能评估指标,如果是,则结束训练;如果否,则继续执行步骤s11,继续对所述文本行识别模型以及所述单字检测和识别模型继续进行训练,直至所述字符识别测试结果达到预设的性能评估指标。
[0101]
在具体实施中,可以先通过步骤s11和步骤s12对所述文本识别模型进行训练,之后通过步骤s13至步骤s17对所述文本识别模型进行测试,并根据得到的字符识别测试结果确定所述文本识别模型是否达到预设的性能评估指标,并根据测试评价结果选择是否继续对所述文本识别模型进行训练。其中,所述文本识别模型包括适于对文本行图像进行识别的文本行识别模型以及适于对单字进行识别的单字检测和识别模型,并且对于经文本行识别模型输出的文本行识别结果,通过预设的置信度阈值和能量阈值进行综合评价,能够更加高效地挑选出需要进行单字识别和检测的字符,之后,通过用于生僻字识别的单字检测和识别模型进行单字识别,由于所述文本识别模型结合了文本行识别模型以及单字检测和识别模型,因而行识别结合了用于生僻字识别的单字检测和识别模型的字符识别结果。综上可知,上述文本识别模型经训练完成后,采用所述文本识别模型进行文本行图像的字符识别,能够提高字符识别精度及识别效率。
[0102]
在具体实施中,由于汉字、日语等语言的长尾分布特性以及包含大量的形近字,例如直接用文本行识别模型例如crnn训练达到数万类别的汉字会带来一些问题,例如精度问题,若形近字较多,则影响常见字的识别率,生僻字在文本行识别模型中识别精度较低。发明人经过研究和实践发现,在高置信度区间,生僻字和常见字难以有效区分,单纯依靠置信度区分时,在设定阈值时,如果判定为生僻字的阈值过低,则很多常见字会被误判为生僻字进入单字识别分支,导致计算量变大,如果置信度阈值设置过高,很多生僻字无法进入到单
字识别分支,导致生僻字识别率很低,在上述实施例中,结合能量与置信度进行生僻字识别,相比单一的置信度判定,可以在单字总字数相同的情况下,例如总字数为2万,准确率可以提升3%,能够解决直接用文本行识别模型训练2万类产生的效率低的问题,并可以保障常见字的识别精度,因而能够兼顾识别效率及识别精度。
[0103]
此外,在具体实施中,发明人发现,直接用文本行识别模型例如crnn训练达到数万类别的汉字还会带来一些其他问题,例如数据问题。具体而言,由于真实数据成本高,而生僻字语料少,随机语料训练效果差。
[0104]
为缓解上述问题,在步骤s11中,可以将第一文本行图像训练集和第二文本行图像训练集按照相应训练批次预设的第一混合比例进行混合,得到所述文本行图像训练集;其中,所述第一文本行图像训练集为对采集的真实文本图像进行裁切得到;所述第二文本行图像训练集为通过收集不同字体的字库,并按照文本行中文字的排布规则合成文本行得到;类似地,可以将第一字符图像训练集和第二字符图像训练集按照相应训练批次预设的第二混合比例进行混合,得到所述字符图像训练集;其中,所述第一字符图像训练集为对采集的真实文本图像进行裁切得到;所述第二字符图像训练集为通过收集不同字体的字库,并按照文本行中文字的排布规则合成文本图像后进行裁切得到。
[0105]
由于真实数据获取成本较高,合成数据和真实数据的比例通常为100:1或甚至更高。若按照同样比例采样训练,合成数据的拟合效果通常会大于真实数据,尤其是真实场景中的难样本更难拟合,这个问题在容量有限的小模型上更为突出,为此,在本发明一些实施例中,采用批次比例采样策略。具体而言,可以将第一文本行图像训练集和第二文本行图像训练集按照相应训练批次预设的第一混合比例进行混合,以及将第一字符图像训练集和第二字符图像训练集按照相应训练批次预设的第二混合比例进行混合,使得经所述文本行图像训练集训练得到的所述文本行识别模型和经所述字符图像训练集训练得到的所述单字检测和识别模型达到预设的泛化性能指标阈值。作为可选示例,所述第一混合比例例如可以为1:2,或者为1:3、1:4等;类似地,所述第二混合比例可以为1:2,或者为1:3、1:4等。以上混合比例仅为示例说明,在具体实施中,能够使得经所述文本行图像训练集训练得到的所述文本行识别模型和经所述字符图像训练集训练得到的所述单字检测和识别模型达到预设的泛化性能指标阈值即可。
[0106]
通过上述批次比例采样策略,可以提升真实数据的采样率,提高真实场景是识别准确率,能够在一定程度上缓解训练数据的问题。
[0107]
为了更好地生成文本识别模型,在执行步骤s11后,还可以对所述文本行图像训练集和字符图像训练集执行图像增广操作,之后再执行步骤s12,以提高生成的文本识别模型的鲁棒性。
[0108]
通过图像增广,对图像训练集做一系列的随机改变,来产生相似但又不同的训练样本,从而可以扩展用于训练的图像集的规模。在具体实施中,图像增广操作具体可以包括:图像随机裁剪、随机加噪、仿射变换、投射变换、光照对比度变换等其中一种或多种,本发明实施例中并不限定所采用的图像增广操作的具体方式。
[0109]
正则化技术,如数据增广,丢弃(dropout)等通过添加噪声来克服过拟合,在大型神经网络上取得了很大成功。其中,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
[0110]
然而,这些常规的正则化技术会损害小型神经网络的性能,因为小型模型的容量有限,往往都是欠拟合状态。针对这一问题,在本发明一些实施例中,可以采用自衰减式图像增广方法,具体而言,可以对所述文本行图像训练集和字符图像训练集按照相应训练批次设置的超参数执行图像增广操作,所述超参数随着训练批次的增加而衰减。在具体实施中,可以通过超参数ε控制图像增广的程度,ε越大代表增广后图像与原始图像的差异越大,在训练过程中,同学习率一样,可以对ε进行衰减。自衰减式图像增广在ε较大时可以看成是一种另类的预训练,在ε逐渐缩小过程中,原始图像数据的拟合程度逐渐增强,能够提高通用场景的字符识别率。
[0111]
通过采用自衰减式图像增广方法,可以在训练过程中逐渐增强原始数据的拟合程度,经一具体测试验证发现,最终使通用场景ocr识别率提高约2%。
[0112]
上述文本识别模型经训练完成后,可以用于文本识别,以下通过具体实施例并结合具体应用场景进行详细介绍。
[0113]
参照图2所示的文本识别方法的流程图,在本发明一些实施例中,具体可以通过如下步骤实施:
[0114]
s21,获取待识别的文本行图像。
[0115]
s22,对所述文本行图像采用训练完成的文本行识别模型进行行文本识别,得到文本行识别结果。
[0116]
作为可选示例,所述文本行识别模型可以包括:crnn,如前述实施例所述,所述文本行识别模型也可以采用其他结构的神经网络模型或者算法,本发明实施例中对所采用的模型的具体类型和结构并不做任何限定。
[0117]
s23,评估所述文本行识别结果中各字符的置信度和能量,在确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,执行步骤s24。
[0118]
作为可选示例,可以按照如下公式评估所述文本行识别结果中各字符的能量:
[0119][0120]
其中,x表征所述字符的图像,t表征温度超参数,k表征类别数,f为文本行识别模型,例如为crnn,fi(x)表示k个类别数中的第i个类别对应的特征值。
[0121]
s24,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符子图像。
[0122]
在具体实施中,所述预设宽度可以基于待识别的语言文字的种类,图像尺寸及文字尺寸等具体设定,本发明实施例中并不限定其具体数值。
[0123]
s25,对于各字符子图像,采用训练完成的单字检测和识别模型进行单字检测和识别,输出相应的字符识别结果。
[0124]
如前实施例介绍,通过单字检测和识别模型可以先检测出单字,再用字典识别出具体是哪个字。本发明实施例中并不限定所采用的单字检测和识别模型的具体类型,作为可选示例,所述单字检测和识别模型可以为rpn结构模型,或者为rrpn结构模型,或者为rcnn 结构模型,也可以为fast-rcnn结构模型等或其结合。
[0125]
s26,结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像的字符识别结果并输出。
[0126]
采用上述实施例,通过引入能量联合置信度对文本行识别结果进行综合判断,能
够更加高效地挑选出需要进行单字识别和检测的字符;另一方面,由于结合了行识别与用于生僻字识别的单字检测和识别模型进行综合识别,因而采用所述文本识别模型进行字符识别,能够提高字符识别精度。
[0127]
在具体实施中,为了提高文本识别模型对于通用场景的鲁棒性,在对所述文本行图像采用训练完成的文本行识别模型进行行文本识别之前,还可以对所述待识别的文本行图像进行图像增强预处理。具体而言,可以对所述文本行图像进行中值滤波、旋转或尺寸缩放等各种图像增强处理。
[0128]
为使本领域技术人员更好地理解和实施例,以下结合一具体应用场景进行示例性说明,参照图3及图3a至图3f所示的文本识别方法的场景示例示意图,例如,将如图3a所示的待识别的文本行图像输入预设的文本识别模型中的文本行识别模型,例如crnn,其中包括 cnn层和ctc层,输出的文本行识别结果如图3b所示。
[0129]
经评估所述文本行识别结果中各个字符的置信度conf和能量energy,分别满足如图3c 所示的对应关系。
[0130]
作为可选示例,能量energy可以采用如下公式计算:
[0131][0132]
其中,x表征所述字符的图像,t表征温度超参数,k表征类别数,f为文本行识别模型网络,fi(x)表示k个类别数中的第i个类别对应的特征值。
[0133]
经判定,参照图3c,文本行识别结果中字符a01的置信度为064,低于预设的置信度阈值tc,而字符a02的能量值为400,大于预设的能量阈值te,则以图3a所示文本行图像中的相应字符为中心,裁切预设宽度的字符子图像,例如得到两个字符子图像如图3d中字符子图像b01和b02所示,之后,将这两个字符子图像输入预设的单字检测和识别模型,得到相应的字符识别结果如图3e所示,且二者的置信度分别达到0.93和0.96,如图3所示,满足预设的识别精度要求,则结合图3b所示的文本行识别结果和图3e所示的单字检测和识别得到的相应的字符识别结果,可以得到所述文本行图像的文本识别结果如图3f所示。
[0134]
由上可知,结合了字符的置信度和能量的综合判定,以及文本行识别模型结合单字识别模型综合识别,能够提高文本识别精度。并且通过字符的置信度和能量的综合评判,可以筛选出需要进一步用于生僻字识别的单字检测和识别,而避免文本行图像中逐个字符进行单字检测和识别,因而能够提高整体识别效率。
[0135]
本说明书实施例中还提供了相应的文本识别系统,如图4所示的文本识别系统的结构示意图,文本识别系统40可以包获取单元41、文本行识别单元42、评估单元43、裁切单元 44、字符识别单元45和识别结果输出单元46,其中:
[0136]
所述获取单元41,适于获取待识别的文本行图像;
[0137]
所述文本行识别单元42,适于对所述文本行图像采用训练完成的文本行识别模型进行行文本识别,得到文本行识别结果;
[0138]
所述评估单元43,适于评估所述文本行识别结果中各字符的置信度和能量;
[0139]
所述裁切单元44,适于在所述评估单元确定所述文本行识别结果中任一字符的置信度小于预设的置信度阈值或所述字符的能量大于预设的能量阈值时,以所述文本行图像中的相应字符为中心,裁切预设宽度的字符子图像;
[0140]
所述字符识别单元45,对于各字符子图像,适于采用训练完成的单字检测和识别
模型进行单字检测和识别,输出相应的字符识别结果;
[0141]
所述识别结果输出单元46,适于结合所述文本行识别结果和相应的字符识别结果,得到所述文本行图像的字符识别结果并输出。
[0142]
本说明书实施例还提供了相应的电子设备,参照图5所示的电子设备的结构示意图,本说明书实施例还提供了一种电子设备50,包括存储器51和处理器52,所述存储器51上存储有可在所述处理器52上运行的计算机程序,其中,所述处理器52运行所述计算机程序时可以执行前述任一实施例所述的文本识别模型生成方法的步骤或文本识别方法的步骤。具体步骤可以参见前述方法实施例的详细描述。
[0143]
此外,在具体实施中,继续参照图5,所述电子设备50还可以包括显示模块53,适于输出展示文本行识别结果。
[0144]
在具体实施中,继续参照图5,所述电子设备还可以包括输入接口54,通过输入接口54 与用户交互,以供用户选择待识别的文本行图像或进行一些基本设置或个性化设置等。作为一可选示例,所述输入接口54包括光学扫描接口,例如可以光学扫描接口可以直接获取待识别的文本行图像;作为另一可选示例,所述输入接口54包括摄像头模组,通过所述摄像头模组可以对待识别的页面或界面等进行拍照以获得待识别的文本行图像。
[0145]
在另一些实施例中,可以通过通讯接口55获取所述获取待采集的文本行图像,所述通讯接口可以为蓝牙接口或者其他短程通讯接口。
[0146]
在具体实施中,存储器51、处理器52、显示模块53、输入接口54及通讯接口55之间可以通过总线56进行通信。
[0147]
作为一可选示例,所述电子设备50可以为能够离线处理的数据处理设备,例如可以为词典笔,所述处理器52可以为单核处理器,也可以为多核处理器,可以为通用的处理器,也可以为专门定制的处理器,这里对处理器的具体构造及实现方式并不做任何限定。
[0148]
在具体实施中,词典笔是一种面向学生用户的产品,可以使用其进行扫描或者通过语音交互等操作方式来学习语言,能够帮助用户解决听说读写、背译查解等问题。其中,词典笔最核心的基础功能是扫描查词,由于采用离线算法,因此词典笔可以在无网络的离线状态下正常使用,因而能够极大地提升使用便捷性和可用性。
[0149]
其中,离线ocr可以作为文字信息提取的入口,即作为输入接口,一旦识别错误,会导致整体功能不可用,同时由于是面向终端消费者的产品,因而需要考虑用户体验和硬件成本,通常其数据处理能力有限,例如其可能采用单核、2核或4核的低功耗的片上系统或处理器。
[0150]
而通过本发明实施例的优化改进,经测试验证,可以使得词典笔生僻字测试集的准确率整体提升30%以上,并且对常见字的识别率几乎不影响。此外,通过本说明书前述实施例所示例的针对小型模型训练的多项改进设计,能够满足词典笔场景高效快速的用户应用需求。
[0151]
可以理解的是,所述电子设备具体也可以为智能眼镜、智能手表等可穿戴式设备,或者为低端手机,也可以为可移动扫描仪、智能音箱等物联网设备,本说明书实施例中并不限定能够应用本发明实施例所述的文本识别方法和系统的电子设备的具体类型。
[0152]
本说明书实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,其中,所述计算机程序运行时执行前述任一实施例所述的文本识别模型生成方法的步骤或文
本识别方法的步骤,具体步骤可以参见前述实施例,此处不再赘述。
[0153]
在具体实施中,所述计算机可读存储介质可以是光盘、机械硬盘、固态硬盘等各种适当的可读存储介质。
[0154]
虽然本说明书实施例披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1