一种文档识别智能校对系统及方法与流程
本发明属于文档识别智能校对系统,具体涉及一种文档识别智能校对系统及方法。
背景技术:
1、现有的pdf文件内容提取核对是完全依靠纯人工手工复制来操作,速度慢成本高,长时间核对人因影响大,各类表格文字看串行,手动录入错误率高,无法为科研,数据分析,数据预测等场景提供高质量的数据保证。
2、本套系统通过ocr文字识别,表格提取技术完全取代了人工手动复制,录入等重复性劳动的工作,效率提升10倍,针对识别后内功有问题的地方系统可自动进行高亮展示,节省了人员核对成本,有效的提升了准确率。
技术实现思路
1、针对现有技术中存在的上述不足之处,本发明提供了一种文档识别智能校对系统及方法,用以解决现有的问题。
2、为了解决上述技术问题,本发明采用了如下技术方案:
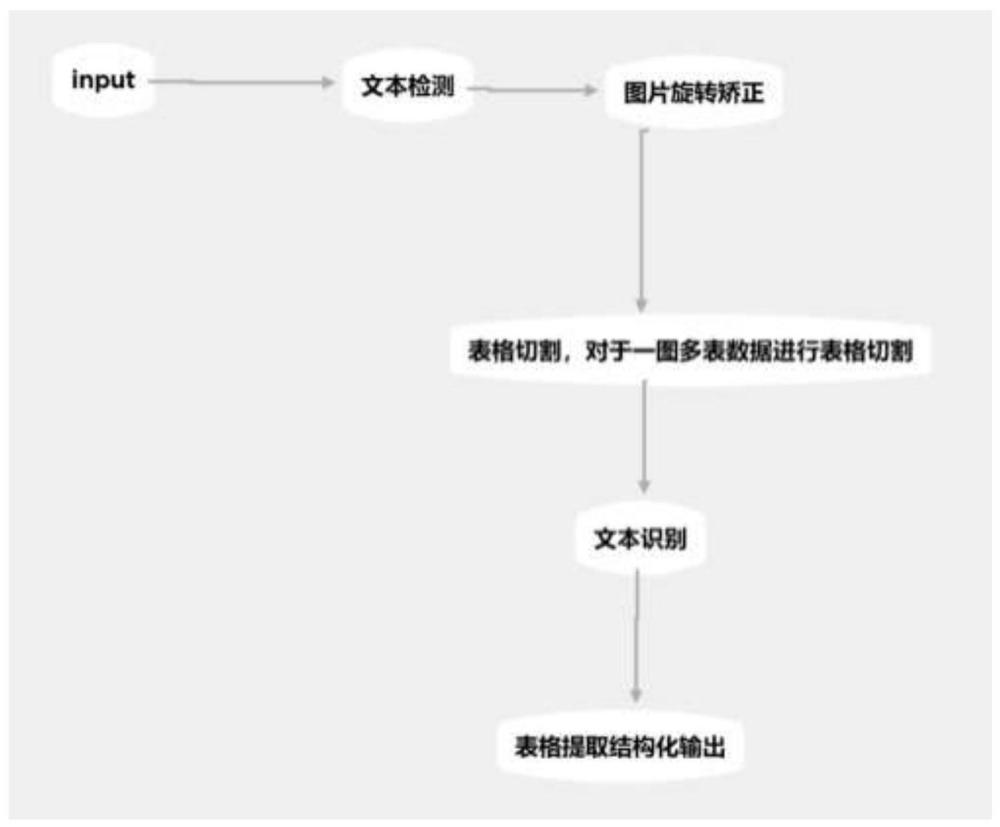
3、一种文档识别智能校对系统及方法,包括:文本定位模块,用于实现自动化文本定位;图片倾斜矫正模块,用于把图片矫正为正确格式数据;表格切割模块,用于将一图多个表格数据进行表格切割;ocr识别模块,用于对文本进行识别;表格提取模块,用于提取结构化数据;数据核对模块,用于针对识别结果设置算法置信度并针对错误率判定较高的进行高亮提示辅助人工校对。
4、进一步,所述文本定位模块采用计算近似二值图的方式输出文本位置信息。
5、进一步,所述图片倾斜矫正模块采用mobilenetv2模型进行文字方向分类提取,并通过获取到的方向判断图片是否有旋转情况,如有旋转对图片进行旋转矫正,然后对旋转矫正后的图像进行斜率计算,通过计算得到的斜率值进行倾斜矫正。
6、进一步,所述表格切割模块通过所述ocr识别模块识别结果获取图像内部title区域特定文字的数量判断出图片内表格的数量,并结合表格内部title文字结果和文本位置信息以及表格底部特定文字信息进行图片切割,从而得到多个表格数据。
7、进一步,所述ocr识别模块采用cnn+bilstm网络结构,包括特征提取和序列特征提取两部分。
8、进一步,所述表格提取模块通过文本位置信息进行文本行列关系排序,对特定区域内文字进行表格区域生成,并对表格区域内文字进行行列关系提取,直至提取完毕。
9、本发明与现有技术相比,具有如下有益效果:
10、本发明可自动识别pdf文件并提取相应的表格内容并按原有表格还原至excel文档,系统支持左右对照人工审核,针对识别置信度的内容进行高亮提取,提高了人工提取核对效率,准确率校对后可达到100%。
技术特征:
1.一种文档识别智能校对系统及方法,其特征在于,包括:
2.如权利要求1的一种文档识别智能校对系统及方法,其特征在于:所述文本定位模块采用计算近似二值图的方式输出文本位置信息。
3.如权利要求2的一种文档识别智能校对系统及方法,其特征在于:所述图片倾斜矫正模块采用mobilenetv2模型进行文字方向分类提取,并通过获取到的方向判断图片是否有旋转情况,如有旋转对图片进行旋转矫正,然后对旋转矫正后的图像进行斜率计算,通过计算得到的斜率值进行倾斜矫正。
4.如权利要求3的一种文档识别智能校对系统及方法,其特征在于:所述表格切割模块通过所述ocr识别模块识别结果获取图像内部title区域特定文字的数量判断出图片内表格的数量,并结合表格内部title文字结果和文本位置信息以及表格底部特定文字信息进行图片切割,从而得到多个表格数据。
5.如权利要求4的一种文档识别智能校对系统及方法,其特征在于:所述ocr识别模块采用cnn+bilstm网络结构,包括特征提取和序列特征提取两部分。
6.如权利要求5的一种文档识别智能校对系统及方法,其特征在于:所述表格提取模块通过文本位置信息进行文本行列关系排序,对特定区域内文字进行表格区域生成,并对表格区域内文字进行行列关系提取,直至提取完毕。
技术总结
本发明属于文档识别智能校对系统技术领域,具体涉及一种文档识别智能校对系统及方法,包括:文本定位模块,用于实现自动化文本定位;图片倾斜矫正模块,用于把图片矫正为正确格式数据;表格切割模块,用于将一图多个表格数据进行表格切割;OCR识别模块,用于对文本进行识别;表格提取模块,用于提取结构化数据;数据核对模块,用于针对识别结果设置算法置信度并针对错误率判定较高的进行高亮提示辅助人工校对,本发明可自动识别pdf文件并提取相应的表格内容并按原有表格还原至excel文档,系统支持左右对照人工审核,针对识别置信度的内容进行高亮提取,提高了人工提取核对效率,准确率校对后可达到100%。
技术研发人员:张旭
受保护的技术使用者:壹合原码(北京)科技有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!