数据处理方法、装置、电子设备及计算机可读存储介质与流程
本申请实施例涉及文本处理,具体涉及一种数据处理方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、文本聚类,也就是文本分类,是指将具有相同或者相似语义的文本划分至同一集合中。比较常用的文本聚类方式有基于模型的文本聚类,例如基于文本表征模型的文本聚类。具体的,文本表征模型可以将不同文本映射成文本向量,并利用文本向量之间的相似度来表征对应文本之间语义的相似度。因此,文本表征模型的性能会严重影响到文本聚类的效果。
2、目前,文本表征模型的训练过程通常是采用自监督的对比学习,通过拉近数据样本中语义相似的句子距离,排开语义不相似的句子距离来学习高质量的文本表征模型。然而,对比学习是将正例样本和负例样本在特征空间中进行对比,来学习样本的特征,其所依赖的是大量的正负样本,需要获得大量的数据和先验知识,在数据样本不足的条件下,无法训练得到高质量的文本表征模型。
技术实现思路
1、本申请实施例提供一种数据处理方法、装置、电子设备及计算机可读存储介质,旨在解决现有技术中在数据样本不足的条件下,无法训练得到高质量的文本表征模型的问题。
2、一方面,本申请实施例提供一种数据处理方法,包括:
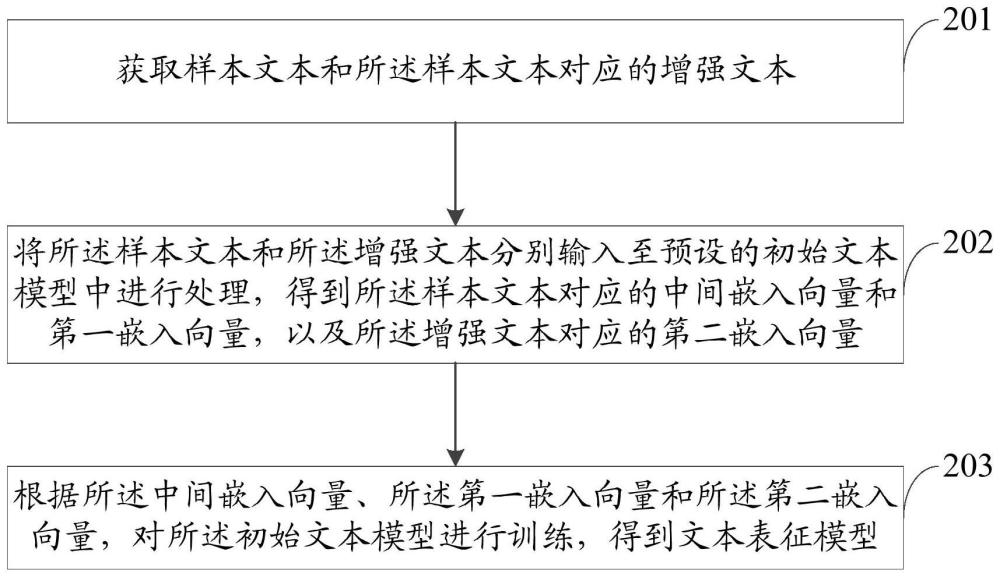
3、获取样本文本和所述样本文本对应的增强文本;所述增强文本是通过数据增强的方式对所述样本文本处理得到;所述数据增强的方式包括替换、插入、删除中的至少一种;
4、将所述样本文本和所述增强文本分别输入至预设的初始文本模型中进行处理,得到所述样本文本对应的中间嵌入向量和第一嵌入向量,以及所述增强文本对应的第二嵌入向量;
5、根据所述中间嵌入向量、所述第一嵌入向量和所述第二嵌入向量,对所述初始文本模型进行训练,得到文本表征模型。
6、作为本申请的一种可行实施例,所述初始文本模型由第一编码器、第二编码器和第三编码器组成;
7、得到所述样本文本对应的中间嵌入向量和第一嵌入向量的步骤,包括:
8、将所述样本文本输入至所述第一编码器中进行处理,得到中间嵌入向量;
9、将所述样本文本输入至所述第二编码器中进行处理,得到第一嵌入向量;
10、得到所述增强文本对应的第二嵌入向量的步骤,包括:
11、将所述增强文本输入至所述第三编码器中进行处理,得到第三嵌入向量。
12、作为本申请的一种可行实施例,所述将所述样本文本输入至所述第一编码器中进行处理,得到中间嵌入向量,包括:
13、将所述样本文本输入至所述第一编码器中进行处理,得到所述第一编码器中各编码层的输出向量;
14、对各所述编码层的输出向量进行采样,并计算采样后的输出向量的均值,得到中间嵌入向量。
15、作为本申请的一种可行实施例,所述根据所述中间嵌入向量、所述第一嵌入向量和所述第二嵌入向量,对所述初始文本模型进行训练,得到文本表征模型,包括:
16、根据预设的权重对所述中间嵌入向量与所述第一嵌入向量之间的第一相似度、所述第一嵌入向量与所述第二嵌入向量之间的第二相似度进行加权,得到对比损失值;
17、根据所述对比损失值对所述初始文本模型中第二编码器和第三编码器的参数进行更新,得到更新后的初始文本模型;
18、当更新后的初始文本模型的对比损失值满足预设条件时,将所述更新后的初始文本模型确定为文本表征模型;其中,所述更新后的对比损失值是由所述中间嵌入向量,以及更新后的第一嵌入向量和第二嵌入向量确定。
19、作为本申请的一种可行实施例,所述根据预设的权重对所述中间嵌入向量与所述第一嵌入向量之间的第一相似度、所述第一嵌入向量与所述第二嵌入向量之间的第二相似度进行加权,得到对比损失值,包括:
20、获取所述第二编码器或所述第三编码器中参数的更新次数;
21、根据所述更新次数对应的权重系数对所述中间嵌入向量与所述第一嵌入向量之间的第一相似度,以及所述第一嵌入向量与所述第二嵌入向量之间的第二相似度进行加权,得到对比损失值。
22、作为本申请的一种可行实施例,所述获取样本文本和所述样本文本对应的增强文本,包括:
23、获取样本文本;
24、对所述样本文本进行同义词替换处理,得到替换文本;和/或
25、对所述样本文本进行交换处理,得到交换文本;和/或
26、对所述样本文本进行插入处理,得到插入文本;和/或
27、对所述样本文本进行删除处理,得到删除文本;
28、将所述替换文本、所述交换文本、所述插入文本和所述删除文本中的至少一种确定为所述样本文本对应的增强文本。
29、作为本申请的一种可行实施例,所述根据所述中间嵌入向量、所述第一嵌入向量和所述第二嵌入向量,对所述初始文本模型进行训练,得到文本表征模型之后,所述方法包括:
30、将待分类的目标文本输入至所述文本表征模型,得到各所述目标文本的文本表征向量;
31、根据各所述文本表征向量之间的相似度,对所述目标文本进行聚类,得到文本分类集合。
32、另一方面,本申请实施例还提供一种数据处理装置,包括:
33、获取模块,用于获取样本文本和所述样本文本对应的增强文本;所述增强文本是通过数据增强的方式对所述样本文本处理得到;所述数据增强的方式包括替换、插入、删除中的至少一种;
34、处理模块,用于将所述样本文本和所述增强文本分别输入至预设的初始文本模型中进行处理,得到所述样本文本对应的中间嵌入向量和第一嵌入向量,以及所述增强文本对应的第二嵌入向量;
35、训练模块,用于根据所述中间嵌入向量、所述第一嵌入向量和所述第二嵌入向量,对所述初始文本模型进行训练,得到文本表征模型。
36、另一方面,本申请实施例还提供一种电子设备,所述电子设备包括处理器、存储器以及存储于所述存储器中并可在所述处理器上运行的数据处理程序,所述处理器执行所述数据处理程序以实现上述的数据处理方法中的步骤。
37、另一方面,本申请实施例还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有数据处理程序,所述数据处理程序被处理器执行以实现上述的数据处理方法中的步骤。
38、本申请实施例利用样本文本输入至初始文本模型所得到的中间嵌入向量和第一嵌入向量,以及增强文本输入至初始文本模型所得到的第二嵌入向量来对初始文本模型进行训练,能够提高文本模型学习句子嵌入的效果,从而提高模型文本表征的效果,以更准确地用于后续的文本聚类。
技术特征:
1.一种数据处理方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述初始文本模型由第一编码器、第二编码器和第三编码器组成;
3.根据权利要求2所述的方法,其特征在于,所述将所述样本文本输入至所述第一编码器中进行处理,得到中间嵌入向量,包括:
4.根据权利要求2所述的方法,其特征在于,所述根据所述中间嵌入向量、所述第一嵌入向量和所述第二嵌入向量,对所述初始文本模型进行训练,得到文本表征模型,包括:
5.根据权利要求4所述的方法,其特征在于,所述根据预设的权重对所述中间嵌入向量与所述第一嵌入向量之间的第一相似度、所述第一嵌入向量与所述第二嵌入向量之间的第二相似度进行加权,得到对比损失值,包括:
6.根据权利要求1所述的方法,其特征在于,所述获取样本文本和所述样本文本对应的增强文本,包括:
7.根据权利要求1~6任一项所述的方法,其特征在于,所述根据所述中间嵌入向量、所述第一嵌入向量和所述第二嵌入向量,对所述初始文本模型进行训练,得到文本表征模型之后,所述方法包括:
8.一种数据处理装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括处理器、存储器以及存储于所述存储器中并可在所述处理器上运行的数据处理程序,所述处理器执行所述数据处理程序以实现权利要求1至7任一项所述的数据处理方法中的步骤。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有数据处理程序,所述数据处理程序被处理器执行以实现权利要求1至7任一项所述的数据处理方法中的步骤。
技术总结
本申请实施例提供一种数据处理方法、装置、电子设备及计算机可读存储介质,方法包括:获取样本文本和样本文本对应的增强文本;将样本文本和增强文本分别输入至预设的初始文本模型中进行处理,得到样本文本对应的中间嵌入向量和第一嵌入向量,以及增强文本对应的第二嵌入向量;根据中间嵌入向量、第一嵌入向量和第二嵌入向量,对初始文本模型进行训练,得到文本表征模型。本申请实施例利用样本文本输入至初始文本模型所得到的中间嵌入向量和第一嵌入向量,以及增强文本输入至初始文本模型所得到的第二嵌入向量来对初始文本模型进行训练,能够提高文本模型学习句子嵌入的效果,从而提高模型文本表征的效果,以更准确地用于后续的文本聚类。
技术研发人员:卢思瑾,赵向军
受保护的技术使用者:TCL科技集团股份有限公司
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!