并行处理系统中的高带宽扩展存储器的制作方法
各种实施例总体上涉及并行处理计算架构,更具体地,涉及并行处理系统中的高带宽扩展存储器。
背景技术:
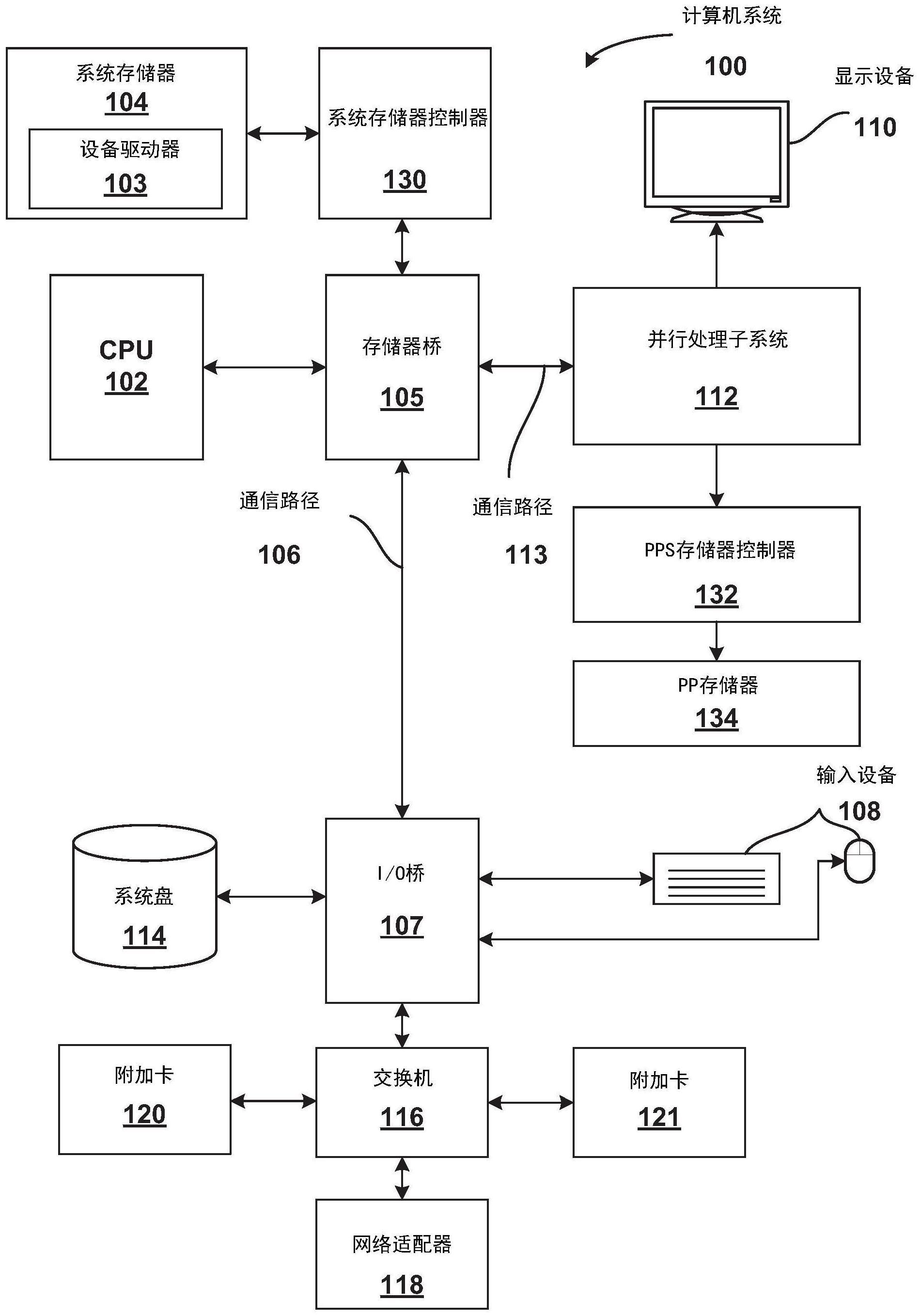
1、除其他外,计算系统通常包括一个或更多个处理单元,例如中央处理单元(cpu)和/或图形处理单元(gpu),以及一个或更多个存储器系统。通常,cpu充当计算系统的主处理器,控制和协调其他系统组件(例如gpu)的操作。cpu通常可以访问大量的低带宽系统存储器。另一方面,gpu通常可以访问少量的高带宽本地存储器。因此,cpu能够容纳消耗大量存储器并且不需要来自存储器的高带宽的应用程序。另一方面,gpu能够适应消耗较少存储器并需要高存储器带宽的进程。特别是,gpu能够同时执行大量(例如,数百或数千个)线程,其中每个线程都是独立指令序列的实例。因此,gpu非常适合可并行线程,这些线程受益于高带宽存储器以实现特定任务的高性能。
2、某些线程是高度可并行化的,因此非常适合在一个或更多个gpu上执行。然而,这些线程通常可以访问比gpu可以直接寻址更多的存储器。此类线程的示例包括推荐系统(为特定用户建议相关项目)、佩奇等级(pagerank)系统(根据节点之间的关系和连接来衡量数据图中每个节点的重要性)、数据科学和分析系统以及利用大型存储器内数据库的其他系统。这样的线程非常适合在一个或更多个gpu上实现的数千个处理器上执行。但是,这些线程可访问比配置访问gpu的存储器量占用大得多的存储器空间的数据库。
3、用于在gpu上执行此类线程的一种方法是配置线程以使大部分数据驻留在系统存储器中。数据从系统存储器加载或“调入(paged-in)”gpu本地存储器,并根据需要存储回或“调出(paged out)”到系统存储器。但是,由于gpu到系统存储器的带宽较低,因此相对于访问gpu本地存储器而言,将数据调进出gpu本地存储器的速度较慢,从而显著降低了gpu性能。
4、用于在gpu上执行此类线程的另一种方法是通过互连gpu的高速总线来利用一个或更多个其他gpu的gpu本地存储器的一部分。可以根据需要将数据从一个或更多个其他gpu的本地存储器调入gpu本地存储器并调出至其他gpu的本地存储器。或者,gpu可以通过通信网络直接访问存储在一个或更多个其他gpu的本地存储器中的数据。因此,gpu可能会增加线程可用的高带宽存储器量。这种方法的一个缺点是,与低带宽系统存储器相比,其他gpu可用的附加高带宽存储器量相对有限。因此,即使在gpu从一个或更多个其他gpu分配高带宽存储器之后,gpu仍可能没有足够的高带宽存储器来有效地执行应用程序。这种方法的另一个缺点是,当第一gpu被分配了来自第二gpu的一部分存储器时,第二gpu可访问的存储器相应地减少了。分配后,第一gpu现在可以执行具有足够高带宽存储器量的线程,而第二gpu可能无法执行具有足够高带宽存储器量的线程,从而导致第二gpu的性能下降。
5、如前所述,本领域需要用于访问并行处理系统中的扩展存储器的更有效的技术。
技术实现思路
1、本公开的各种实施例阐述了一种用于访问并行处理系统(例如gpu)中的存储器的方法,该并行处理系统被附接到中央处理单元。该方法包括从并行处理系统接收存储器访问。该方法还包括确定存储器访问是指向与由操作系统管理的中央处理单元相关联的扩展存储器。该方法还包括将存储器访问传送到与中央处理单元相关联的存储器控制器以进行处理。该处理可以包括存储器写入操作或存储器读取操作中的至少一种。
2、其他实施例包括但不限于实现所公开技术的一个或更多个方面的系统,以及包括用于执行所公开技术的一个或更多个方面的指令的一个或更多个计算机可读介质,以及用于执行所公开技术的方法所公开技术的一个或更多个方面。
3、所公开的技术相对于现有技术的至少一个技术优势在于,利用所公开的技术,执行线程的并行处理器可以访问大量存储器,而不会招致从调入和调出到系统存储器的带宽损失。在另一种方法中,并行处理器(例如gpu)直接读取和写入系统存储器。这种替代方法通常需要输入/输出存储器管理单元(iommu)地址转换,这会导致性能下降。相比之下,所公开技术的优点是存储器访问可以以全链路带宽指向存储器,而没有iommu转换的开销。因此,高度可并行化并访问大存储器空间的线程具有相对于现有方法在并行处理器上提高的性能执行。这些优点代表了对现有技术方法的一项或更多项技术改进。
技术特征:
1.一种用于访问并行处理系统中的存储器的方法,所述并行处理系统被耦合到中央处理单元,所述方法包括:
2.如权利要求1所述的方法,其中所述并行处理系统包括与所述扩展存储器分离的本地存储器。
3.如权利要求1所述的方法,其中所述并行处理系统包括与所述扩展存储器分离的本地存储器,并且其中所述扩展存储器具有与所述本地存储器相同的编程模型。
4.如权利要求1所述的方法,其中所述并行处理系统缺少本地存储器,并且其中所述扩展存储器提供对系统存储器的高速访问,所述系统存储器包括所述扩展存储器并且与所述中央处理单元相关联。
5.如权利要求1所述的方法,其中所述并行处理系统包括与所述扩展存储器分离的本地存储器,并且所述方法还包括:基于页表中包括的页表条目,确定第二存储器访问是指向所述扩展存储器还是指向所述本地存储器。
6.如权利要求1所述的方法,其中所述扩展存储器被包括在与所述中央处理单元相关联的系统存储器的指定部分中,并且其中所述存储器控制器在处理所述第一存储器访问时不对包括在所述第一存储器访问中的地址执行地址转换。
7.如权利要求1所述的方法,其中用于访问所述扩展存储器的第一页大小大于用于访问与所述中央处理单元相关联的系统存储器的第二页大小。
8.如权利要求1所述的方法,其中所述第一存储器访问与包括对等标识符的页表条目相关联,并且其中所述对等标识符识别包括所述扩展存储器的插座。
9.如权利要求1所述的方法,其中所述并行处理系统被包括在第一插座中并且所述扩展存储器被包括在第二插座中。
10.如权利要求9所述的方法,其中与第二存储器访问相关联的地址转换识别所述第二插座,并且其中包括在所述第二插座中的存储器管理单元确定所述第二存储器访问是指向所述扩展存储器还是指向包括在所述并行处理系统中的本地存储器。
11.如权利要求1所述的方法,其中所述第一存储器访问与包括在所述并行处理系统上执行的多个虚拟机中的第一虚拟机相关联,并且其中包括在所述多个虚拟机中的每个虚拟机与所述扩展存储器的非重叠部分相关联。
12.一种系统,包括:
13.如权利要求12所述的系统,其中所述系统还包括与所述扩展存储器分离的本地存储器。
14.如权利要求12所述的系统,其中所述系统还包括与所述扩展存储器分离的本地存储器,并且其中所述扩展存储器具有与所述本地存储器相同的编程模型。
15.如权利要求12所述的系统,其中所述系统缺少本地存储器,并且其中所述扩展存储器提供对系统存储器的高速访问,所述系统存储器包括所述扩展存储器并且与所述中央处理单元相关联。
16.如权利要求12所述的系统,其中所述系统还包括与所述扩展存储器分离的本地存储器,并且其中所述存储器管理单元进一步基于包括在页表中的页表条目来确定第二存储器访问是指向所述扩展存储器还是指向所述本地存储器。
17.如权利要求12所述的系统,其中所述扩展存储器被包括在与所述中央处理单元相关联的系统存储器的指定部分中,并且其中所述存储器控制器在处理所述第一存储器访问时不对包括在所述第一存储器访问中的地址执行地址转换。
18.如权利要求12所述的系统,其中用于访问所述扩展存储器的第一页大小大于用于访问与所述中央处理单元相关联的系统存储器的第二页大小。
19.如权利要求12所述的系统,其中所述第一存储器访问与包括对等标识符的页表条目相关联,并且其中所述对等标识符识别包括所述扩展存储器的插座。
20.如权利要求12所述的系统,其中所述系统被包括在第一插座中并且所述扩展存储器被包括在第二插座中。
技术总结
本公开涉及并行处理系统中的高带宽扩展存储器。各种实施例包括用于经由到驻留在中央处理单元上的扩展存储器的高带宽路径访问并行处理系统中的扩展存储器的技术。所公开的扩展存储器系统将本地可直接寻址的高带宽存储器扩展到并行处理系统并且避免与低带宽系统存储器相关联的性能损失。因此,高度可并行化并访问大存储器空间的执行线程具有相对于现有方法在并行处理系统上提高的性能执行。
技术研发人员:H·侯赛因,S·E·莫尔纳,J·S·R·埃文斯,W·A·甘地,兰基·V·姗,V·文卡塔拉曼,M·海尔格罗夫,G·格芬,J·M·史密斯,T·伯格斯特龙,V·塞西,P·帕特尔
受保护的技术使用者:辉达公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!