一种文本信息的处理方法、装置及设备与流程
本发明涉及文本处理,特别是指一种文本信息的处理方法、装置及设备。
背景技术:
1、机器阅读理解(machine reading comprehension,mrc)就是给定一篇文章,以及基于文章的一个问题,让机器在阅读文章后对问题进行作答。
2、现有技术中,用户输入的查询文本和阅读材料文本在进行问题和答案匹配时,采用相同的词语处理方法,使得机器阅读文章进行问题作答匹配时,效率较低。
技术实现思路
1、本发明提供一种文本信息的处理方法、装置及设备,解决现有技术中机器阅读文章进行问题作答匹配时,效率较低的问题。
2、为解决上述技术问题,本发明的技术方案如下:
3、一种文本信息的处理方法,包括:
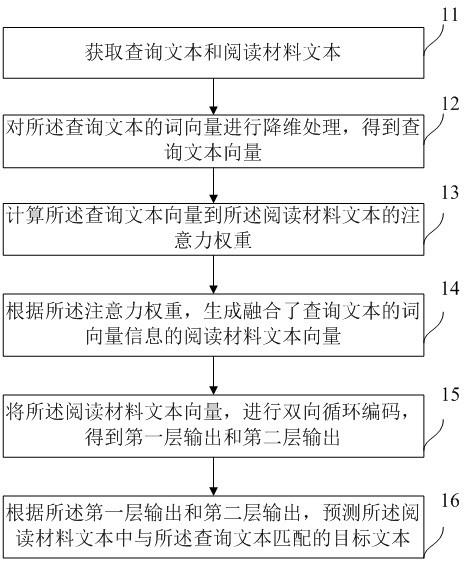
4、获取查询文本和阅读材料文本;
5、对所述查询文本的词向量进行降维处理,得到查询文本向量;
6、计算所述查询文本向量到所述阅读材料文本的注意力权重;
7、根据所述注意力权重,生成融合了查询文本的词向量信息的阅读材料文本向量;
8、将所述阅读材料文本向量,进行双向循环编码,得到第一层输出和第二层输出;
9、根据所述第一层输出和第二层输出,预测所述阅读材料文本中与所述查询文本匹配的目标文本。
10、可选的,对所述查询文本的词向量进行降维处理,得到处理结果,包括:
11、对所述查询文本进行分词处理,得到所述查询文本的字词粒度的分词序列;
12、获取所述分词序列中的元素在预设的分词词典中出现的词,得到子词序列;
13、对所述子词序列中的元素进行哈希运算,得到每一个元素的哈希值形成的预设维度的查询文本向量,所述预设维度小于所述查询文本的维度。
14、可选的,计算所述查询文本向量到所述阅读材料文本的注意力权重,包括:
15、将所述查询文本向量进行至少一层的非线性映射处理,得到查询文本向量映射结果;
16、对所述阅读材料文本进行分词处理,得到所述阅读材料文本的字词粒度的分词矩阵;
17、对所述分词矩阵进行词嵌入处理,得到词嵌入处理结果;
18、将所述词嵌入处理结果,输入双向的长短期记忆人工神经网络进行编码处理,得到所述阅读材料文本的上下文编码;
19、根据所述查询文本向量映射结果和所述上下文编码中的元素,计算所述查询文本向量到所述阅读材料文本的注意力权重。
20、可选的,通过以下公式计算注意力权重:
21、
22、其中,表示所述查询文本向量映射结果,表示上下文编码中的第i个元素,t表示元素的个数,表示第i个元素对应的注意力权重,exp表示自然常数e为底的指数函数。
23、可选的,根据所述注意力权重,生成融合了查询文本的词向量信息的阅读材料文本向量,包括:
24、将所述注意力权重与查询文本向量映射结果的乘积与每一个元素拼接后,得到所述阅读材料文本向量,所述阅读材料文本向量为,其中,表示拼接。
25、可选的,将所述阅读材料文本向量,进行双向循环编码,得到第一层输出和第二层输出,包括:
26、将所述阅读材料文本向量输入双向长短期记忆人工神经网络进行编码处理,得到第一层输出和第二层输出;其中,所述第一层输出为双所述长短期记忆人工神经网络的l1层的最后一个位置的输出值,所述第二层输出为所述长短期记忆人工神经网络的l2层的每一个位置的输出值。
27、可选的,根据所述第一层输出和第二层输出,预测所述阅读材料文本中与所述查询文本向量匹配的目标文本,包括:
28、利用所述第一层输出,预测所述阅读材料文本中与所述查询文本匹配的目标文本;
29、利用所述第二层输出,预测所述阅读材料文本中与所述查询文本匹配的文本对应的文本区域;
30、根据所述目标文本和所述文本区域,输出最终的目标文本。
31、本发明的实施例还提供一种文本信息的处理装置,包括:
32、获取模块,用于获取查询文本和阅读材料文本;
33、处理模块,用于对所述查询文本的词向量进行降维处理,得到查询文本向量;计算所述查询文本向量到所述阅读材料文本的注意力权重;根据所述注意力权重,生成融合了查询文本的词向量信息的阅读材料文本向量;将所述阅读材料文本向量,进行双向循环编码,得到第一层输出和第二层输出;根据所述第一层输出和第二层输出,预测所述阅读材料文本中与所述查询文本匹配的目标文本。
34、本发明的实施例还提供一种计算设备,包括:处理器、存储有计算机程序的存储器,所述计算机程序被处理器运行时,执行如上所述的方法。
35、本发明的实施例还提供一种计算机可读存储介质,存储指令,当所述指令在计算机上运行时,使得计算机执行如上所述的方法。
36、本发明的上述方案至少包括以下有益效果:
37、本发明的上述方案,通过获取查询文本和阅读材料文本;对所述查询文本的词向量进行降维处理,得到查询文本向量;计算所述查询文本向量到所述阅读材料文本的注意力权重;根据所述注意力权重,生成融合了查询文本的词向量信息的阅读材料文本向量;将所述阅读材料文本向量,进行双向循环编码,得到第一层输出和第二层输出;根据所述第一层输出和第二层输出,预测所述阅读材料文本中与所述查询文本匹配的目标文本;从而可以自动挖掘多文档问题答案,即目标文本,降低输入的查询文本的维度,可以单独使用查询文本作为问题编码器,在线上应用中快速为输入的查询文本所表示的问题进行编码,提高机器阅读文章进行问题作答匹配时的效率。
技术特征:
1.一种文本信息的处理方法,其特征在于,包括:
2.根据权利要求1所述的文本信息的处理方法,其特征在于,对所述查询文本的词向量进行降维处理,得到处理结果,包括:
3.根据权利要求1所述的文本信息的处理方法,其特征在于,计算所述查询文本向量到所述阅读材料文本的注意力权重,包括:
4.根据权利要求3所述的文本信息的处理方法,其特征在于,通过以下公式计算注意力权重:
5.根据权利要求4所述的文本信息的处理方法,其特征在于,根据所述注意力权重,生成融合了查询文本的词向量信息的阅读材料文本向量,包括:
6.根据权利要求1所述的文本信息的处理方法,其特征在于,将所述阅读材料文本向量,进行双向循环编码,得到第一层输出和第二层输出,包括:
7.根据权利要求6所述的文本信息的处理方法,其特征在于,根据所述第一层输出和第二层输出,预测所述阅读材料文本中与所述查询文本向量匹配的目标文本,包括:
8.一种文本信息的处理装置,其特征在于,包括:
9.一种计算设备,其特征在于,包括:处理器、存储有计算机程序的存储器,所述计算机程序被处理器运行时,执行如权利要求1至7任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,存储指令,当所述指令在计算机上运行时,使得计算机执行如权利要求1至7任一项所述的方法。
技术总结
本发明公开了一种文本信息的处理方法、装置及设备。方法包括:获取查询文本和阅读材料文本;对所述查询文本的词向量进行降维处理,得到查询文本向量;计算所述查询文本向量到所述阅读材料文本的注意力权重;根据所述注意力权重,生成融合了查询文本向量的词向量信息的阅读材料文本向量;将所述阅读材料文本向量,进行双向循环编码,得到第一层输出和第二层输出;根据所述第一层输出和第二层输出,预测所述阅读材料文本中与所述查询文本匹配的目标文本。本发明的方案可以提高机器阅读文章时,对阅读材料进行问题作答匹配时的效率。
技术研发人员:梁矗,郑铁樵,张博
受保护的技术使用者:云智慧(北京)科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!