基于边缘计算的实体抽取的制作方法
背景技术:
1、实体抽取(entity extraction,ee),也可以称为命名实体识别(named entitiesrecognition,ner),其主要任务是识别实体的文本范围,并将该实体分类为预定义的类别,例如人名、地名、日期等。可以通过机器学习模型来执行实体抽取。在本文中,将用于执行实体抽取任务的机器学习模型称为实体抽取模型。可以将实体抽取任务定义为序列标注任务。实体抽取模型可以对输入的文本或者文本特征进行推理,并输出相应的实体类别序列。
技术实现思路
1、提供本
技术实现要素:
以便介绍一组构思,这组构思将在以下的具体实施方式中做进一步描述。本发明内容并非旨在标识所保护的主题的关键特征或必要特征,也不旨在用于限制所保护的主题的范围。
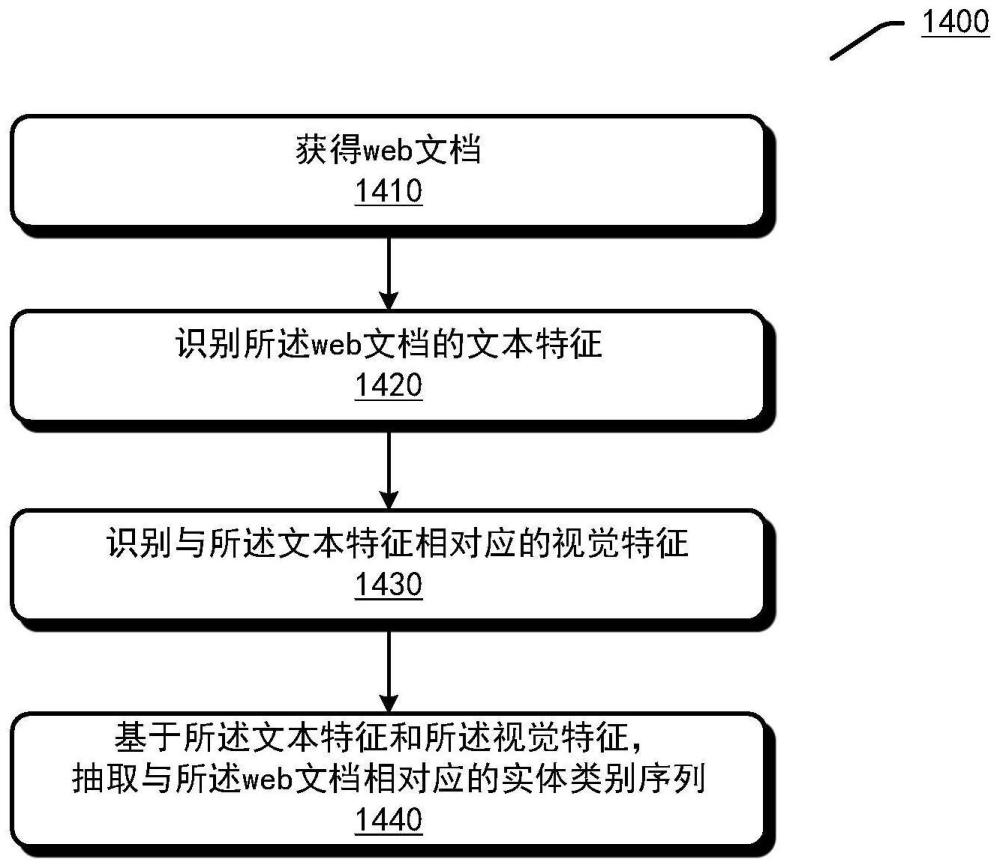
2、本公开的实施例提出了用于基于边缘计算的实体抽取的方法、装置和计算机程序产品。可以获得web文档。可以识别所述web文档的文本特征。可以识别与所述文本特征相对应的视觉特征。可以基于所述文本特征和所述视觉特征,抽取与所述web文档相对应的实体类别序列。
3、应当注意,以上一个或多个方面包括在下文中详细描述并且在权利要求中具体指出的特征。以下说明书及附图详细阐述了所述一个或多个方面的某些说明性特征。这些特征仅仅指示可以采用各个方面的原理的各种方式,并且本公开旨在包括所有这些方面及其等同变换。
技术特征:
1.一种用于基于边缘计算的实体抽取的方法,包括:
2.根据权利要求1所述的方法,其中,所述文本特征包括词块序列,并且所述识别与所述文本特征相对应的视觉特征包括:
3.根据权利要求1所述的方法,其中,所述文本特征和所述视觉特征与所述web文档中的多个文本片段相对应,并且所述抽取与所述web文档相对应的实体类别序列包括:
4.根据权利要求1所述的方法,其中,所述抽取与所述web文档相对应的实体类别序列包括:
5.根据权利要求4所述的方法,其中,所述目标实体抽取模型是通过以下操作来获得的:
6.根据权利要求5所述的方法,其中,所述对所述复杂语言模型执行模型增强包括:
7.根据权利要求6所述的方法,其中,所述对所述复杂语言模型执行视觉及文本联合预训练包括:
8.根据权利要求7所述的方法,其中,所述计算与所述文本节点对相对应的节点关系子预测损失包括:
9.根据权利要求6所述的方法,其中,所述对所述复杂语言模型执行模型增强还包括:
10.根据权利要求9所述的方法,其中,所述对所述视觉增强型复杂实体抽取模型执行跨语言微调包括:
11.根据权利要求9所述的方法,其中,所述对所述视觉增强型复杂实体抽取模型执行跨语言微调包括:
12.根据权利要求11所述的方法,其中,所述自训练包括:
13.根据权利要求5所述的方法,其中,所述利用所述参考实体抽取模型和所述轻量级语言模型来执行模型压缩包括:
14.根据权利要求13所述的方法,其中,所述利用所述参考实体抽取模型和所述轻量级语言模型来执行知识蒸馏包括:
15.根据权利要求14所述的方法,其中,所述一个或多个老师模型中的每个老师模型包括多个转换器层,并且所述通过所述一个或多个老师模型来标注所述web文档样本包括,对于每个老师模型:
16.根据权利要求13所述的方法,其中,所述利用所述参考实体抽取模型和所述轻量级语言模型来执行模型压缩还包括:
17.根据权利要求16所述的方法,其中,所述对所述轻量级实体抽取模型执行客户端优化包括执行以下至少之一:
18.根据权利要求17所述的方法,其中,所述缩减所述轻量级实体抽取模型的模型词表包括:
19.一种用于基于边缘计算的实体抽取的装置,包括:
20.一种用于基于边缘计算的实体抽取的计算机程序产品,包括计算机程序,所述计算机程序被处理器执行用于:
技术总结
本公开提出了用于基于边缘计算的实体抽取的方法、装置和计算机程序产品。可以获得web文档。可以识别所述web文档的文本特征。可以识别与所述文本特征相对应的视觉特征。可以基于所述文本特征和所述视觉特征,抽取与所述web文档相对应的实体类别序列。
技术研发人员:寿林钧,邵博,沈强,李根,刘天乔,邢璟夏
受保护的技术使用者:微软技术许可有限责任公司
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!