一种文本纠错方法、装置、设备及介质与流程
本申请涉及数据处理,尤其涉及一种文本纠错方法、装置、设备及介质。
背景技术:
1、文本纠错是一种对语句自动检查、自动纠正的技术。其中,在现有技术中,一般通过文本纠错模型实现文本纠错,具体的,将可能带有错误的句子输入到文本纠错模型中,该文本纠错模型会输出正确的句子。
2、目前传统的文本纠错方法,通过预置混淆词语、专有名词等方法,实现了对语音识别的文本进行特定易错词的纠错。但是,由于不同用户之间存在发音差异,经常会出现过纠、错纠的现象。例如用户a表述“经济”时,语音识别成“警戒”,进行文本纠错后将“警戒”的文本纠错为“经济”,但是用户b由于口音与用户a不同,该用户b被识别为“警戒”发音的原始表述为“京剧”,但是在文本纠错时,也会将“警戒”纠错为“经济”,导致文本纠错效果差。
技术实现思路
1、本申请提供了一种文本纠错方法、装置、设备及介质,用以解决现有技术中在对文本纠错时,受用户发音的影响,导致文本纠错效果差的问题。
2、第一方面,本申请实施例提供了一种文本纠错方法,所述方法包括:
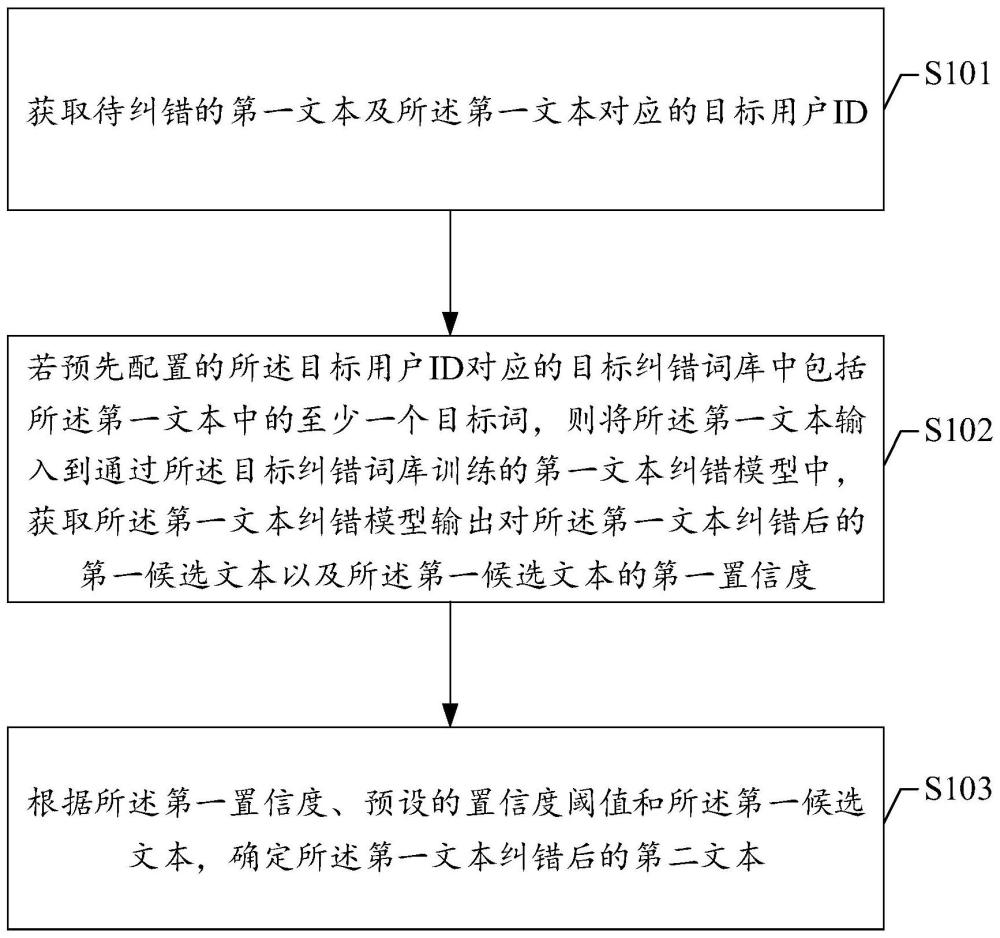
3、获取待纠错的第一文本及所述第一文本对应的目标用户id;
4、若预先配置的所述目标用户id对应的目标纠错词库中包括所述第一文本中的至少一个目标词,则将所述第一文本输入到通过所述目标纠错词库训练的第一文本纠错模型中,获取所述第一文本纠错模型输出对所述第一文本纠错后的第一候选文本以及所述第一候选文本的第一置信度;
5、根据所述第一置信度、预设的置信度阈值和所述第一候选文本,确定所述第一文本纠错后的第二文本。
6、第二方面,本申请实施例还提供了一种电子设备,所述电子设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如上述所述文本纠错方法的步骤。
7、在本申请实施例中,获取待纠错的第一文本及所述第一文本对应的目标用户id;若预先配置的所述目标用户id对应的目标纠错词库中包括所述第一文本中的至少一个目标词,则将所述第一文本输入到通过所述目标纠错词库训练的第一文本纠错模型中,获取所述第一文本纠错模型输出对所述第一文本纠错后的第一候选文本以及所述第一候选文本的第一置信度;根据所述第一置信度、预设的置信度阈值和所述第一候选文本,确定所述第一文本纠错后的第二文本。在本申请实施例中,电子设备中保存有不同用户对应的纠错词库,当存在待纠错的第一文本时,电子设备可以根据该第一文本对应的目标用户id,确定该目标用户id对应的目标纠错词库,再根据该目标纠错词库和第一文本纠错模型对该第一文本进行纠错,避免了在对文本纠错时受到用户发音的影响,提高了文本纠错效果。
技术特征:
1.一种文本纠错方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述将所述第一文本输入到通过所述目标纠错词库训练的第一文本纠错模型中之前,所述方法还包括:
3.根据权利要求2所述的方法,其特征在于,所述第一文本纠错模型确定所述第一候选文本的过程包括:
4.根据权利要求1所述的方法,其特征在于,所述获取待纠错的第一文本及所述第一文本对应的目标用户id之后,所述方法还包括:
5.根据权利要求4所述的方法,其特征在于,根据所述第一置信度、所述第二置信度、所述置信度阈值、所述第一候选文本及所述第二候选文本,确定所述第二文本包括:
6.根据权利要求4所述的方法,其特征在于,若所述通用纠错词库中不包括所述第一文本中的至少一个目标词,且所述目标纠错词库中不包括所述第一文本中的至少一个目标词,所述方法还包括:
7.根据权利要求1所述的方法,其特征在于,确定预先配置的所述目标用户id对应的目标纠错词库中包括所述第一文本中的至少一个目标词包括:
8.根据权利要求5所述的方法,其特征在于,所述判断预先配置的通用纠错词库中是否包括所述第一文本中的至少一个目标词包括:
9.根据权利要求3所述的方法,其特征在于,所述根据所述字符串中每个字符位置对应的预测字符数对所述字符串进行调整包括:
10.一种电子设备,其特征在于,所述电子设备包括处理器,所述处理器用于执行存储器中存储的计算机程序时实现如权利要求1-9任一所述文本纠错方法的步骤。
技术总结
本申请实施例提供了一种文本纠错方法、装置、设备及介质,包括:获取待纠错的第一文本及第一文本对应的目标用户ID,将第一文本输入到通过目标纠错词库训练的第一文本纠错模型中,获取第一文本纠错模型输出对第一文本纠错后的第一候选文本以及第一候选文本的第一置信度;根据第一置信度、预设的置信度阈值和第一候选文本,确定第一文本纠错后的第二文本。在本申请实施例中,电子设备中保存有不同用户对应的纠错词库,电子设备可以根据第一文本对应的目标用户ID,确定采用目标用户ID对应的目标纠错词库训练的第一文本纠错模型,并通过第一文本纠错模型对第一文本进行纠错,避免了在对文本纠错时受到用户发音的影响,提高了文本纠错效果。
技术研发人员:孟卫明,王彦芳,王月岭,高雪松,陈维强
受保护的技术使用者:海信集团控股股份有限公司
技术研发日:
技术公布日:2024/5/10
- 还没有人留言评论。精彩留言会获得点赞!