一种通用即时3D口型动画生成方法、装置及存储介质与流程
本发明涉及语音数据处理,特别涉及一种通用即时3d口型动画生成方法、装置及存储介质。
背景技术:
1、目前,随着3d游戏技术的发展,大众对沉浸感的要求在不断提高。在剧情演绎、虚拟人互联等游戏场景中,通常会涉及到音频与3d口型动画相互配合的对话场景,例如在重要演出时,人物模型要具有和音频保持一致的嘴部动画。
2、在传统的工作流程中,要为3d人物模型添加音频一致的口型动画,有赖于动画师的手动定帧或者人工采集面部捕捉的方式。其中前者需要耗费大量的人力,且存在人工标定方差较大的问题,后者经济成本较高,且对演绎面部捕捉的演员要求也较高。传统的方法都没能很好的解决多语言的问题。
3、在游戏应用场景中,例如玩家间的交流同步表现为口型动画的场景,现有的技术无法即时生成对应到玩家3d人物的口型动画,或对不同语言的玩家无法表现拟真的动画效果。
4、因此需要一种成本相对较低,通用性更强并具有即时性的通用即时3d口型动画生成方法、装置及存储介质。
技术实现思路
1、本发明的主要目的是提供一种成本相对较低,通用性更强并具有即时性的通用即时3d口型动画生成方法、装置及存储介质。
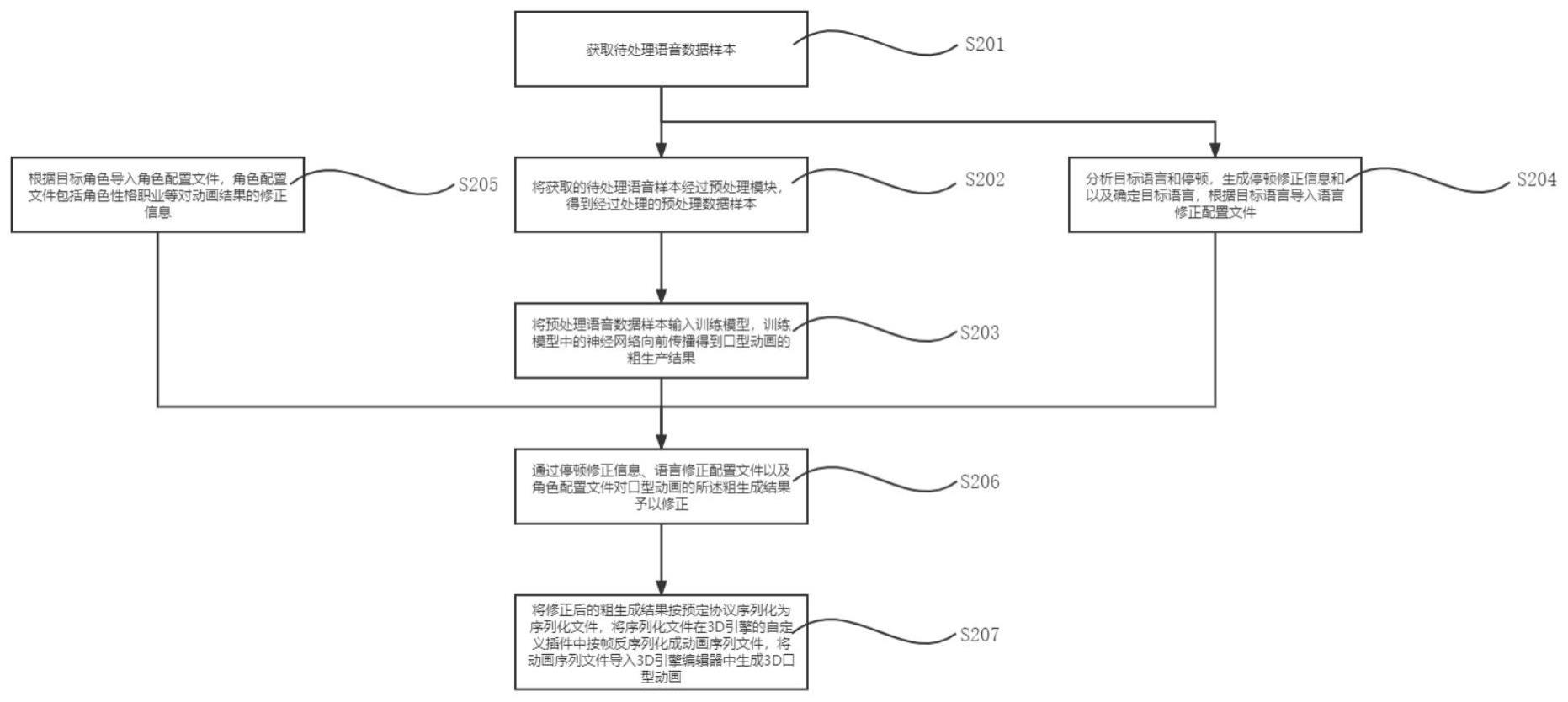
2、本发明提出一种通用即时3d口型动画生成方法、装置及存储介质,获取待处理语音数据样本;
3、将获取的待处理语音数据样本经过预处理模块,得到经过预处理的预处理语音数据样本;
4、将预处理语音数据样本输入预测模型,得到口型动画的粗生成结果;
5、根据语音类型、语言类型以及3d人物特化建模特点对口型动画的所述粗生成结果予以修正并生成3d口型动画;
6、其中,所述预测模型通过训练数据集经过以下训练方法训练得到:
7、所述训练数据集包括训练语音数据样本和训练动画数据样本;
8、将获取的所述训练语音数据样本经过预处理模块,得到经过预处理的预处理训练语音数据样本,并将所述预处理训练语音数据样本作为驱动初始预测模型训练的输入特征,所述初始训练模型由通用特征提取器神经网络以及深度卷积神经网络组成;
9、通过所述初始预测模型对生成的所述输入特征的预测,得到口型动画的预测数据;
10、通过所述预测数据和所述训练动画数据样本确定用以计算预测效果的准确度的代价函数;
11、通过最小化的所述代价函数对初始预测模型的参数进行调整,使初始预测模型的预测精度达到预设的拟真标准,从而得到所述预测模型。
12、优选地,得到修正后的所述粗生成结果后生成3d口型动画的步骤为:
13、1)将修正后的所述粗生成结果按预定协议序列化为序列化文件;
14、2)将所述序列化文件在3d引擎的自定义插件中按帧反序列化成动画序列文件;
15、3)将所述动画序列文件导入3d引擎编辑器中生成3d口型动画。
16、优选地,所述通用特征提取器神经网络为通用语音识别预训练模型wavlm,,所述通用特征提取器神经网络包含第一卷积编码器以及transformer编码器。
17、优选地,所述深度卷积神经网络包括第二卷积编码器以及第一卷积解码器;所述第二卷积编码器的卷积层包含有当前语音帧与相邻语音帧之间的关系。
18、优选地,所述根据语音类型、语言类型以及3d人物特化建模特点对口型动画的所述粗生成结果予以修正并生成3d口型动画,包括:
19、1)分析目标语言和停顿,生成停顿修正信息和以及确定目标语言;
20、2)根据目标语言导入语言修正配置文件,所述语言修正配置文件包括不同语言下,同一音素的口型幅度变化信息,根据目标角色导入角色配置文件,所述角色配置文件包括角色性格职业等对动画结果的修正信息;
21、3)通过停顿修正信息、语言修正配置文件以及角色配置文件对口型动画的所述粗生成结果予以修正并生成3d口型动画。
22、优选地,包括:
23、语音数据获取模块,获取待处理语音数据样本;
24、预处理模块:将获取的待处理语音数据样本经过预处理模块,得到经过预处理的预处理语音数据样本;
25、主生成模块,将预处理语音数据样本输入预测模型,得到口型动画的粗生成结果;
26、后处理模块,根据语音类型、语言类型以及3d人物特化建模特点对口型动画的所述粗生成结果予以修正并生成3d口型动画;
27、在线生成模块,用于对所述后处理模块即时生成的3d口型动画,随着游戏的运行即时展示动画效果。
28、优选地,所述计算机程序被处理器执行时能实现如权利要求1-6任一项所述的方法。
29、本发明的通用即时3d口型动画生成方法、装置及存储介质的有益效果为:
30、1、使用通用语音识别预训练模型wavlm来作为通用特征提取器神经网络,能够对不同语言、不同说话人、不同噪声环境和不同的录音设备都具有良好的泛化性。
31、2、通过采用cnn+transformer+cnn的整体架构能够保证通用即时3d口型动画生成方法的通用性和即时性。
32、3、通过使用语音类型、语言类型以及3d人物特化建模特点对口型动画的粗生成结果予以修正并生成3d口型动画能够使得最终的动画效果更为拟真。
技术特征:
1.一种通用即时3d口型动画生成方法,其特征在于,
2.根据权利要求1所述的通用即时3d口型动画生成方法,其特征在于,得到修正后的所述粗生成结果后生成3d口型动画的步骤为:
3.根据权利要求1所述的通用即时3d口型动画生成方法、装置及存储介质,其特征在于,所述通用特征提取器神经网络为通用语音识别预训练模型wavlm,所述通用特征提取器神经网络包含第一卷积编码器以及transformer编码器。
4.根据权利要求1所述的通用即时3d口型动画生成方法,其特征在于,所述深度卷积神经网络包括第二卷积编码器以及第一卷积解码器,所述第二卷积编码器的卷积层包含有当前语音帧与相邻语音帧之间的关系。
5.根据权利要求1所述的通用即时3d口型动画生成方法,其特征在于,所述根据语音类型、语言类型以及3d人物特化建模特点对口型动画的所述粗生成结果予以修正并生成3d口型动画,包括:
6.一种通用即时3d口型动画生成装置,其特征在于,包括:
7.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时能实现如权利要求1-6任一项所述的方法。
技术总结
本发明公开一种通用即时3D口型动画生成方法,具体实现方法为:获取待处理语音数据样本,将获取的待处理语音数据样本经过预处理模块,得到经过预处理的预处理语音数据样本,将预处理语音数据样本输入预测模型,得到口型动画的粗生成结果,最后根据语音类型、语言类型以及3D人物特化建模特点对口型动画的所述粗生成结果予以修正并生成3D口型动画。
技术研发人员:石梓豪,高原
受保护的技术使用者:软星科技(北京)有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!