学习方法和信息处理设备与流程
本文讨论的实施方式涉及学习方法和信息处理设备。
背景技术:
1、信息处理设备有时被用于使用自然语言处理模型来执行自然语言处理任务,例如命名实体识别、机器翻译和情感分析。自然语言处理模型可以是通过机器学习从训练数据生成的机器学习模型。这样的机器学习模型可以是神经网络。
2、已经提出了如下系统:该系统通过规范化、词干提取、词条化和词元化(tokenization)从文本数据中提取要输入到机器学习模型的特征。另外,已经提出了如下语言处理设备:该语言处理设备将长文本划分成特定大小的短文本片段,并且使用机器学习模型根据每个短文本片段来计算表示短期上下文的短期特征。
3、参见例如美国专利申请公开第2020/0302540号和国际公开小册子第wo2021/181719号。
4、存在已知的如下信息处理设备:在自然语言处理模型的机器学习中,该信息处理设备将包含多个句子的训练数据划分成小批量(mini-batch),并且针对一个小批量重复一次对自然语言处理模型的参数值的更新。每个小批量可以包含两个或更多个句子。
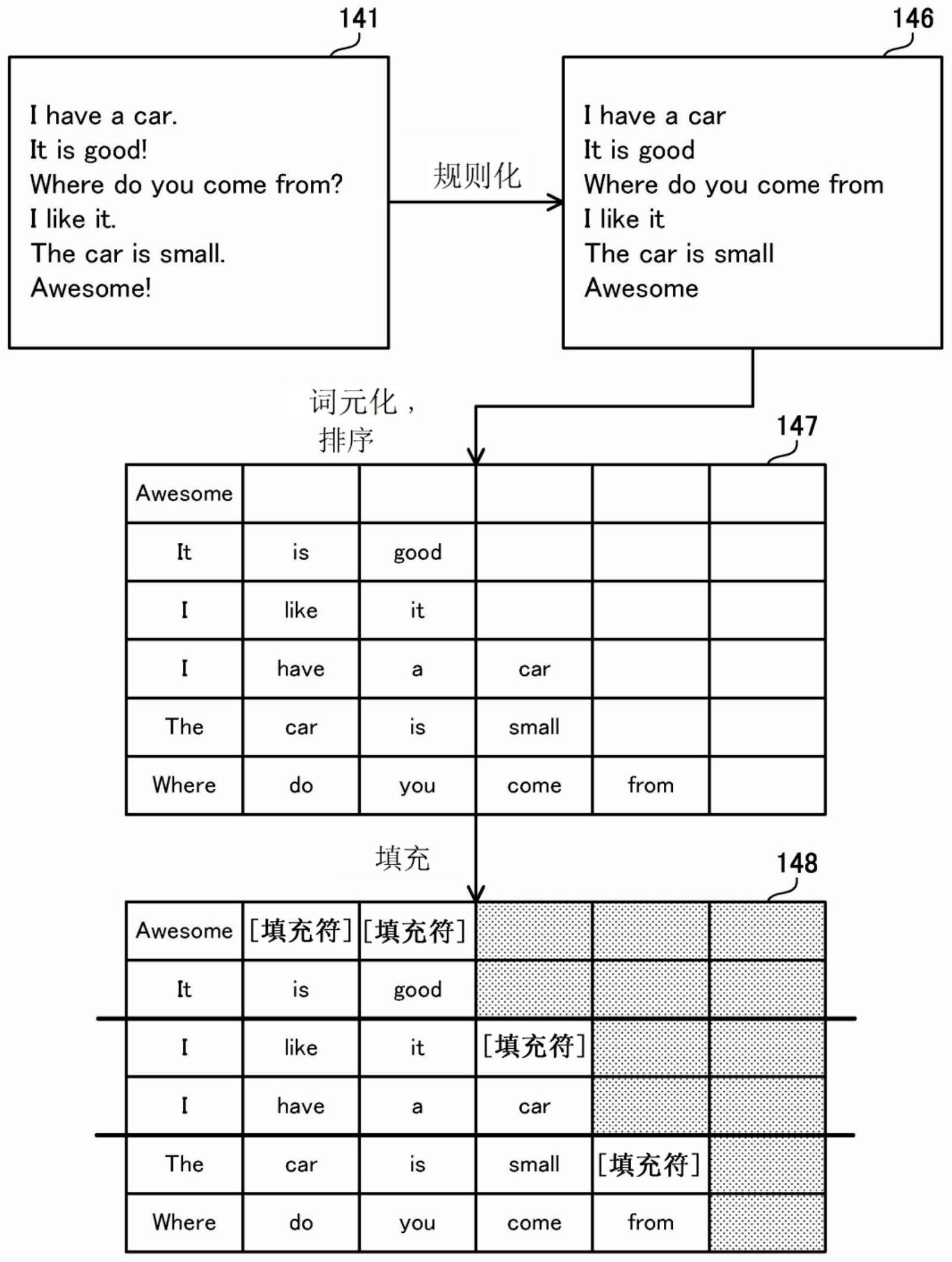
5、然而,注意,有时存在以下情况:由于参数计算的限制,同一小批量中包括的两个或更多句子需要具有相同的长度。在这种情况下,信息处理设备执行填充以将各自代表空白空间的填充符(pad)添加至较短的句子,以使得至少在同一小批量中句子共享相同的长度。然而,直接对包括各种字符的句子进行填充可能会不期望地增加填充后的小批量的数据大小。这可能会增加机器学习的计算复杂性,并且因此增加学习时间。
技术实现思路
1、实施方式的一个方面是缩短自然语言处理模型的学习时间。
2、根据一个方面,提供了一种非暂态计算机可读记录介质,存储有使计算机执行处理的计算机程序,所述处理包括:从多个句子的每个句子中删除特定类型的字符,并且生成不包括特定类型的字符并且与所述多个句子相对应的多个单词串;将多个单词串划分成多个组,多个组中的每个组包括两个或更多单词串;针对多个组中的每个组,基于两个或更多个单词串中的最大单词数量执行填充以使两个或更多个单词串中的单词数量相等;以及使用多个填充后的组中的每个组来更新自然语言处理模型中包括的参数值,其中该自然语言处理模型根据输入到自然语言处理模型的单词串来计算估计值。
技术特征:
1.一种非暂态计算机可读记录介质,存储有使计算机执行处理的计算机程序,所述处理包括:
2.根据权利要求1所述的非暂态计算机可读记录介质,其中:
3.根据权利要求1所述的非暂态计算机可读记录介质,其中:
4.根据权利要求1所述的非暂态计算机可读记录介质,其中:
5.一种由计算机执行的学习方法,所述学习方法包括:
6.一种信息处理设备,包括:
技术总结
公开了学习方法和信息处理设备。信息处理设备从多个句子的每个句子中删除特定类型的字符,并且生成不包括特定类型的字符并且与多个句子相对应的多个单词串。信息处理设备将多个单词串划分成各自包括两个或更多个单词串的多个组。信息处理设备针对多个组中的每个组,基于两个或更多个单词串中的最大单词数量执行填充以使两个或更多个单词串中的单词数量相等。信息处理设备使用多个填充后的组中的每个组来更新自然语言处理模型中包括的参数值,其中该自然语言处理模型根据输入到自然语言处理模型的单词串来计算估计值。
技术研发人员:邓唯胜
受保护的技术使用者:富士通株式会社
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!